The Distributed SAS 9.4 LASR Analytic Server provides a massively parallel processing solution for working very quickly with huge volumes of data. LASR was built from its earliest invocations to provide for incredible scalability and growth. One of the primary criteria which drives the considerations of scalability is load management. And LASR was built with a very specific principle to deal with managing load. LASR architecture assumes maximum efficiency is achieved when each node of the cluster is identical in terms of CPU, RAM, data to process, and other ancillary processes. LASR’s approach to load management gives external forces the ability to affect performance. So let’s look at some of the considerations we should all know about.
Load management in LASR is based on the assumption that all host machines are equal – that is each host has the same number and kind of CPUs, same RAM, same OS, and same ongoing workload as all the other hosts which are participating in the cluster. So with all those things set, there is only one item left to manage LASR’s workload: distribution of the data. With everything being equal on our hosts, then we want to distribute the data equally to each of the LASR Workers so that when they’re given an analytic job to perform, each of them can do the same tasks on the same amount of data and therefore finish in the same elapsed time.
Load Balancing == Even Data Distribution
When data is loaded into a Distributed LASR Analytic Server from SAS, the LASR Root Node accepts the incoming data and then distributes it evenly across all of the LASR Workers. Similarly for parallel data loading from a remote data provider, the SAS Embedded Process will evenly distribute blocks of data directly over to the LASR Workers as well.

Growing the LASR Cluster
With Massively Parallel Processing software, like the Distributed SAS LASR Analytic Server, when you need more performance or more capacity, then the expected approach is to add more machines to the cluster. Unlike traditional SMP systems where you might add in more RAM or more disk to an existing host so that it can do more on its own, with MPP we really prefer to distribute the load across as many cheap commodity-grade machines as possible. So rack up some new server hardware, install the necessary software, and then load in the data and get to work.
The MPP approach sounds simple and the SAS High-Performance Analytics Environment software is easy to deploy. But the real world doesn’t sit still and technology progresses quickly. If you initially setup your LASR cluster a year or so ago, and now you’re shopping for additional machines to add to your cluster, there’s a good chance that the vendor is selling new models which feature faster CPU and RAM than the old ones in your cluster.
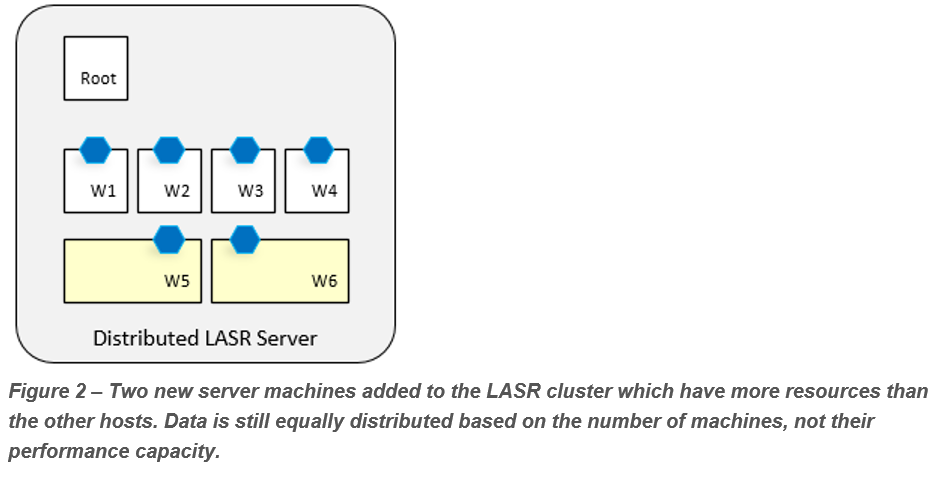
Is This a Problem?
No, it’s definitely not a problem. LASR will function just fine when hosted on machines with slightly different resources. Furthermore, you will certainly see an improvement in performance. In the illustrations above, we’ve taken our data from being distributed across only four LASR Workers and upgraded the cluster so that the data is now processed across six machine hosts. Therefore you can expect almost 50% improvement in LASR processing time (not total response time – we still have network i/o, middle-tier communications, browser rendering, and more to deal with).
You’re probably wondering why the improvement is “only” 50%. After all, the two new machines (W5 and W6) have faster CPUs than the other older four machines (W1 – W4). They should be able to knock out their specific tasks faster, right? And indeed, they do. But it’s not the new machines’ performance we need to look at – the old ones are setting the pace.
This comes back to LASR’s assumption that all machines hosting the LASR Workers are identical in terms of resources and performance. When dealing with future cluster expansion, try to keep the new machines as close as possible in terms of performance and capacity to the old machines simply because you don’t want to spend money unnecessarily for capacity which might be underutilized.
The Crux of the Matter
When LASR is distributing data to its Workers, there is no accommodation made for machines which have more CPU or RAM (or any other resources) than their cluster comrades. Each gets an equal portion of data simply based on dividing the data up among the number of machines in the cluster. Since each machine in the LASR cluster is operating on the same amount of data, machines which can crunch the numbers quicker (e.g. due to faster CPU or RAM) will finish their tasks sooner. However, the final answer is only available once the LASR Root Node has the responses from all of the Workers, so it must wait for the older/slower ones to finish as well.
Unbalanced Data Does Happen
Machine resources aren’t the only thing which can impact overall performance of LASR. On the flip side of the same coin is the amount of data being worked on. It is possible for data to get loaded in such a way that some LASR Workers will actually have more data to work on than others. That means that those with more data will need more time to complete their jobs.
For example, the SAS Embedded Process which provides SAS In-Database functionality has the ability to load data directly into LASR Workers. And the SAS EP attempts to distribute that data evenly. But at what level? In a Hadoop environment, the EP will distribute blocks of data, not rows, evenly across the LASR Workers. Depending on the size and number of blocks, it’s possible that some Workers will receive one more block than others will. This is unlikely to cause any notable performance lag for end-users, however a sysadmin monitoring low-level system performance might pick up on it. It’s not a big deal, but it can be helpful to be aware of.
Another Hadoop-based example where unbalanced data might occur is with SASHDAT tables. SASHDAT is stored as blocks in HDFS which the LASR Workers read and write themselves directly to disk. Hadoop is responsible for managing those blocks once they’re committed to disk. And if an HDFS Data Node fails or if new HDFS Data Nodes (along with associated new LASR Workers) are added to the cluster after the SASHDAT file has been written out, then Hadoop might move blocks around in line with its block replication and disk utilization schemes. Later on, when LASR attempts to read those SASHDAT blocks back into memory, some Workers might end up with more blocks of data than others.
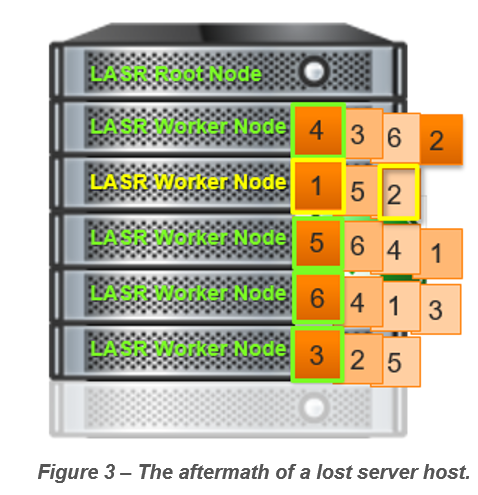
In Figure 3, we can see that one host machine has gone offline. HDFS data is still available due to block replication. However, we can see that one LASR Worker must load up two blocks whereas the rest each get one. The result will be that LASR Worker will need twice as long to perform assigned tasks. Hence, LASR Root must wait twice as long to compile its final answer. Keep in mind that this example is contrived to make a point. In the real world, data volume, block sizes and distribution, as well as other factors will determine the impact on actual performance.
For more information about the HDFS block replication and SASHDAT, see the whitepaper The Impact of Hadoop Resiliency on SAS® LASR™ Analytic Server presented at SAS Global Forum 2015.
Balancing the Data
LASR offers builtin functionality whereby you can re-balance the data which resides in memory.

Here’s some sample code which shows how to promote, balance, and save your LASR in-memory data:
/* Promote, Balance, and Save */
/* Setup a SASIOLA libref that specifies the LASR server */
/* where the unbalanced table resides */
libname example sasiola host="root.lasr.com" port=10010 tag='hps';
/* Use the data management capabilities of the IMSTAT */
/* procedure */
proc imstat immediate;
/* Specify the unbalanced table */
table example.the_table;
/* Print out the distribution stats */
distributioninfo;
/* Perform the balance – each node will be +/- 1 row */
/* A new temporary table (balanced!) is created */
balance;
/* Drop the original unbalanced table */
droptable;
/* Now reference the newly balanced temporary table */
table example.&_templast_;
/* Promote the temporary table to active status with the */
/* original table’s name */
promote the_table;
/* Now reference the new table by its permanent name */
table example.the_table;
/* Print out the distribution stats for confirmation */
/* of balance */
distributioninfo;
/* Save the LASR table back down to SASHDAT on HDFS */
/* and replace the old, unbalanced table there */
save path="/path/in/hdfs" replace;
quit;
Extending What We Know
The concepts of resource utilization and data balancing don’t only apply to LASR. Many similar challenges apply to the SAS High-Performance Analytics software (such as HP STAT) as well because it’s running on the same software foundation as LASR which is provided by the SAS High-Performance Analytics Environment software.

1 Comment
Thanks Rob - very helpful!