SAS System software supports a wide variety architecture and deployment possibilities. It’s wild when you think about it because you can scale the analytic power of SAS from the humblest single CPU laptop machine all the way up to hundreds-of-machines clusters.
When SAS deployments involve many machines, it’s natural to look for time- and effort-saving options that simplify the initial installation as well as ongoing administration. Electing to employ a shared SAS configuration directory is one of those options. But what does that even mean?
Deploying SAS with a shared configuration directory is always optional. It’s not a technical requirement in any sense. But there are times when it’s really nice to have and SAS does support it in the proper circumstances. Here are some tips on when to take advantage of shared configuration capabilities.
First, you need file-sharing technology
To create a shared configuration directory, we must first set up a way to share a single physical directory with multiple machines. A shared file system is one physical storage location that is
- visible to (mounted on) multiple host machines
- accessible to SAS on each machine by the same directory path.
There are many ways to accomplish this. The simplest place to start in UNIX (and Linux) environments is to define a shared filesystem using Network Attached Storage (or NAS) technology. An NAS-mounted filesystem essentially leverages the computer’s built-in networking ability to share one machine’s local disk such that it’s accessible to multiple machines.
This is fine for a proof-of-concept or small development/test deployment, but for a large production environment, chances are you will want to invest in a more robust and scalable technology. A Storage Area Network (or SAN) is a dedicated, resilient and highly available storage solution with faster connectivity than the standard network interfaces leveraged by NAS. There’s a lot more to shared filesystems than just NAS and SAN, but that’s a topic well covered elsewhere. Visit the SAS Support web site for Scalability and Performance Papers to view the SAS Technical Paper: A Survey of Shared File Systems.
Identify which SAS configuration directory to share
Next, we need to identify which SAS configuration directory to share. And that’s going to depend on your SAS server topology. Let’s begin with the standard SAS Enterprise Business Intelligence platform, which is a common building block for most SAS deployments. Here we’ve got three major service tiers:
- Metadata
- Compute (Workspace, Stored Process, OLAP, etc.)
- Middle (Web)
For performance, efficiency, and availability purposes, we’ve elected to place each of those service tiers into their own set of host machines. That is, we’re going to physically separate those logical tiers by their function:
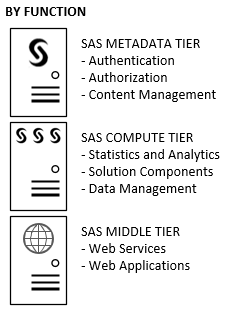
The graphic below shows the necessary deployment steps described by the Planning Application when we choose the topology above from the SAS Deployment Wizard (or SDW):
 The takeaway here: separating the tiers in this way means that each tier will have its own configuration directory. If you choose a multiple machine topology, then on each tier, you must:
The takeaway here: separating the tiers in this way means that each tier will have its own configuration directory. If you choose a multiple machine topology, then on each tier, you must:
- run the SDW
- select a configuration directory that is not shared with any other tier
Avoid this wrong turn!
It’s important to heed this advice: when you’ve chosen a plan with separated tiers, then you must not allow those distinct tiers to write to the same configuration directory.
The SDW warns you if you try to do it:
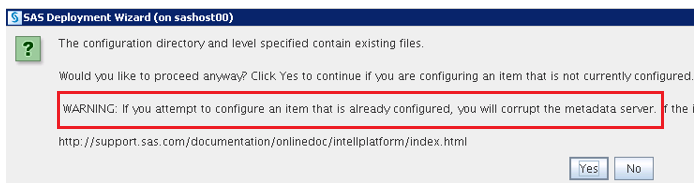
But if you ignore the warning, the SDW will successfully deploy the software for the first as well as the subsequent tiers. SAS services will successfully startup and validate. Everything will appear to work – except for one major problem: the SAS Deployment Registry is overwritten with each new configuration deployment.
That means that in the future, installers for migration, hotfixes and maintenance updates will not be able to see all of the details of the full deployment – only the information for that last SDW configuration is retained. When that day comes, it will create a major headache for support purposes.
Configuring the Compute Tier on a shared directory—an example
Notice that up to this point, we’ve been talking about how the configuration directory must be deployed by tier, not by host machine. Each tier has its own considerations, but the Compute Tier is where we can share the configuration directory across multiple machines.
The Compute Tier can consist of one or more machines. It’s very scalable both vertically and horizontally. For some deployments, there could be dozens, even hundreds, of machines in the SAS Compute Tier. In those circumstances, we don’t want to deploy a separate configuration for each one if we don’t have to, so let’s zoom in on the Compute Tier. In this diagram, we have seven different host machines of varying sizes – all run the same OS version and the same release of SAS. It will save us a lot of installation, configuration, and administration time if they all share a common configuration directory.
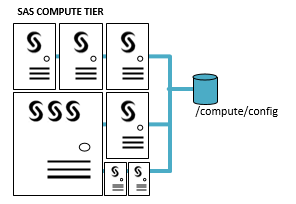
When we run the configuration portion of the SAS Deployment Wizard for the Compute tier, we provide the shared file system’s directory path (in the diagram above, that’s /compute/config). And we only need to run the SDW configuration one time. After configuration is complete, all of the SAS configuration files you’re familiar with are visible and accessible by all machines of the Compute Tier. So with a single deployment run of the SDW, all of the machines in the Compute Tier have access to the same configuration. So what are the benefits?
- From a SAS installer’s perspective, it’s great not having to run the SDW for configuration on each and every host of the Compute Tier.
- For the SAS administrator who is charged with daily operations and maintenance, a shared configuration means that making a change in one place is available to all intended machines.
- Further, when it comes time to deploy hot fixes or maintenance updates, the installation tools also need to run only once for this shared configuration directory.
Finishing the configuration
There is some additional follow-through necessary, depending on your SAS release:
- For SAS 9.4 M1 and earlier releases of SAS, some additional configuration work was required. Certain operational and log files were generically named and if those filenames were not changed, then there be file-locking conflicts as processes on different host machines attempted to write to the same physical file. The procedure is to modify certain scripts to insert variables into the filename references which would then ensure each host machine was writing to its own unique files on the shared filesystem.
- Beginning with SAS 9.4 M2, these manual edits of executable files are no longer required. Filename references now include the hostname by default so everything plays nicely in a shared configuration environment. Yay!
For any release of SAS, you must also make manual changes to the SAS metadata. At this point in the process, you have only deployed a single configuration directory, you have not yet informed the overall SAS deployment of how many server machines are participating in the Compute Tier. Follow the steps provided in the SAS® 9.4 Intelligence Platform: Application Server Administration Guide for Creating Metadata for Load-Balancing Clusters.
Configuring the Metadata Tier and Middle Tier
If you’ve decided to deploy a SAS Metadata Server cluster to ensure high-availability of your metadata services, then you must deploy at least three installations of the SAS Metadata Server. Each of those installations will have its own dedicated configuration directory – they do not share! The only thing shared between the nodes of a metadata cluster is the common network-mounted directory for metadata backups (not shown here).
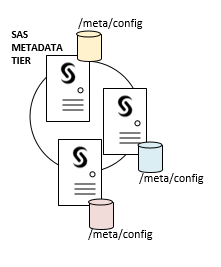
The same holds true if you choose to cluster the SAS Web Application Server. Let’s say you will deploy a horizontal two-node cluster of your SAS Web Application Servers that will be load-balanced by the SAS Web Server. Each node of that web app server cluster will have its own configuration directory – they do not share either!
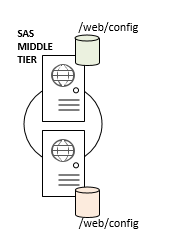
The point is, each of those cluster nodes (for meta and middle) requires their own configuration deployment. Now aren’t you glad we can perform just one configuration deployment in the Compute Tier to share the configuration directory for any number of machines participating there!
Takeaways
In this discussion, we have learned:
- A SAS configuration directory can be shared across multiple machines in the logical Compute tier (as we have it defined separately from the Metadata and Middle tiers) – saving initial deployment effort as well as ongoing administration and maintenance effort
- Clusters of SAS Metadata Servers should not share a configuration directory
- Clusters of SAS middle-tier services should not share a configuration directory
- Do not use the SAS Deployment Wizard to deploy a new configuration on top of another one in the same directory
- Some shared filesystem technologies are better suited for supporting SAS I/O patterns than others – so choose wisely. This list of Scalability and Performance Papers can help.
