 Most SAS programmers would agree that they use the SET statement without giving much thought to the syntax, because it’s such a widely used statement of choice. We routinely name the expected data sets and possibly a few options, and away we go. A visit to the documentation can be saved for more complex concerns such as arrays, hash tables, and regular expressions. Maybe a review of how the Program Data Vector (PDV) stores and outputs variable values could interest even the most experienced SAS programmer.
Most SAS programmers would agree that they use the SET statement without giving much thought to the syntax, because it’s such a widely used statement of choice. We routinely name the expected data sets and possibly a few options, and away we go. A visit to the documentation can be saved for more complex concerns such as arrays, hash tables, and regular expressions. Maybe a review of how the Program Data Vector (PDV) stores and outputs variable values could interest even the most experienced SAS programmer.
Often in Technical Support, we hear from customers who are referencing more than one data set on the SET statement and their results “aren’t correct”. Once we see the code, it’s obvious that this is a case of SAS behaving by design but different than expected by that customer. The following DATA steps and resulting output use missing values to illustrate one common situation where the PDV causes the DATA step to “misbehave”:

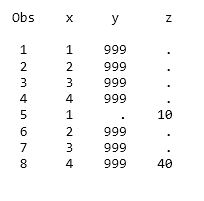
Why the IN= data set option helps, but isn’t the total solution
Because Z doesn’t exist in data set A, all observations from data set A meet the IF condition, thus all Y values are set to 999. It’s likely that most users want only the observations from data set B evaluated by the IF statement. The addition of the IN= data set option seems like a reasonable fix.

Don’t forget how the SET statement changes PDV processing
Observations from data set A are no longer affected by the IF statement. But wait, the eighth observation has a Y value of 999 although Z isn’t missing. What happened? The main points to remember when reading data sets with a SET statement are these:
- The SET statement does not reset the values in the program data vector to missing, except for variables whose values are calculated or assigned during the DATA step.
- Variables that are created by the DATA step are set to missing at the beginning of each iteration of the DATA step.
- Variables that are read from a data set are not.
These differences are key to what happens when data sets are combined with a SET statement. The Combining SAS Data Sets: Methods section of the SAS 9.4 Language Reference: Concepts manual is very helpful.
How to override the automatic retain in the PDV
To take the code sample one step further, observations six and seven correctly show Y values of 999, but since Z isn’t missing on the eighth observation, Y should be a missing value.
You can manually set Y to missing at the top of the DATA step to prevent the automatic retain. Each iteration of the DATA step sets Y to missing, and the SET and IF statements execute and populate the PDV accordingly. Now the resulting data set values are as expected.

Usage Note 48147: Variables read using SET, MERGE, and UPDATE statements are automatically retained is an excellent note to bookmark for future use when reading data sets with the SET, MERGE, or UPDATE statements.

9 Comments
Your second code block would provide greater insight if it was
data final;
set a b(in=inb);
if inb and z=. then y=111*_n_;
run;
it would then be more obvious that the unexpected y value is retained from the previous observation and not the result of the IF condition.
Based upon the description provided of the behaviour of the variables in the PDV and the effects of the DATA and SET statements, one must ask why the value of the Y variable of the fifth observation in the FINAL output dataset in the first example, where the IN= option is not used, is missing and not 999. As per the description, Y is retained, as proven by observation 8, and it is 999 after processing observation 4, so what made it become missing when it was not read to process observation 5, which is the first observation of the B dataset and which does not contain variable Y.
Cheers
We haven’t explained why variable Y is missing in observation 5 in the first example. The discussion explains why Y is 999 in observation 8 – because Y is not reset so the value of 999 in previous observations persists to the end. Wouldn’t that similarly suggest that the value of Y in observation 5 should be 999?
I think I remember reading somewhere that the data step resets the PDV when starting to read any new dataset named in the SET statement. Is that true? (This rule gets complicated with the addition of BY group processing.) If that’s true, is that then the reason Y=. in observation 5?
Peter,
The Y value is missing in the fifth observation because of how the SET statement behaves when reading multiple data sets with one SET statement. The variables in the program data vector are set to missing when SAS begins reading observations from the second data set. Here's the link to our documentation on combining data sets with one SET statement. Look at "Execution - Step 2" section in particular.
http://support.sas.com/documentation/cdl/en/lrcon/67227/HTML/default/viewer.htm#n1tgk0uanvisvon1r26lc036k0w7.htm
Yes, Kim! There it is. I _knew_ I read that _Somewhere_.
Thanks for a great "Tech Tips" column!
Hi. Nice posting.
If anyone would like to read a classic paper about a similar topic, take a look at
"The SAS Supervisor"
http://www.sascommunity.org/wiki/The_SAS_Supervisor
It is the annotated, SAS Community version of a paper given at NESUG in 1988 ...
http://www.lexjansen.com/nesug/nesug88/NESUG88004.pdf
In teaching SAS Education courses in Australia over the years I've found myself saying on each programming course that there appears to be 2 groups of SAS programmers... Those that do SAS programming and those that understand SAS programming. One can copy and paste SAS code for years and say they are a SAS programmer however they may not fully understand what is happening at compilation and execution time and spend a lot of time debugging. However, a programmer that understands these concepts including how the PDV works will be more productive in their SAS programming with less debugging as they can forsee how the code will be compiled and executed.
A great post to highlight why it is important to know the fundamentals of SAS programming and the PDV.
Michelle,
I absolutely agree with your comment. These two groups are with quite different skil sets. Thanks again for pointing it out.
Milorad
Excellent post! I still remember being bitten by this implied retain in my first year of progamming (which was quite a while ago : ) And then I was lucky to take a SAS Training class, and the instructor emphasized the PDV over and over again. I'm thankful for having it pounded into my head that to understand the DATA step, you need to think PDV.