If you routinely import data from external sources, chances are you’ve learned the value in having a systematic import process. In this post, I will begin sharing my approach of using metadata tables to guide the importing of data.
My real-world problem
First, here is a little background on where I’m coming from. I work at the Faculty of Social Work at the University of Toronto where my team works with child welfare data from agencies across the province of Ontario. We periodically receive extracts from the different agencies, then harmonize and structure them in a way that allows researchers to easily query the data. Our Web-based dynamic reporting tool provides each participating agency with information about its performance on available measures along with a comparison to the provincial norm. My main role in this project is working with the various agencies to facilitate the extractions, process the data and push it to our live SQL database.
The University is always expanding to work with more agencies. I usually start my correspondence with an IT contact at an agency by sharing a copy of our latest specifications. This document describes things like the tables, the common identifiers that link them to one another, and the relationships between them. Even though the specifications help each agency to put their data into a uniform format for us, agencies’ systems are different from each other. At a basic level, system differences will result in different code breakdowns. For example, one agency’s idea of ethnicity may be different from another, and these difference in concept will be reflected in their categories. Even if a concept is pretty standard, e.g. a checkbox is either checked or unchecked, the representative codes can be different. For example, one agency might have “A” as checked, “B” as unchecked while another uses “1” and “2”.
Solving the problem
I use metadata tables to store all the agency-specific and database-specific details and have tools that can apply this information to reshape the data. A benefit to this separation of logic from information is that one does not need to be a SAS programmer to update the information side. Let’s say a new table is added or a new agency comes on board, their categories will have to be defined and mapped. A non-programmer can modify the metadata tables to reflect these changes or additions. When the code is run, it will pull in all this information dynamically and use it in its logic. The benefits go the other way too. As a programmer, I can refactor the programs without being bogged down by hard-coded information. The figure below is a small subset of what the structure of one of our databases looks like. We will work with this metadata in the examples going forward.
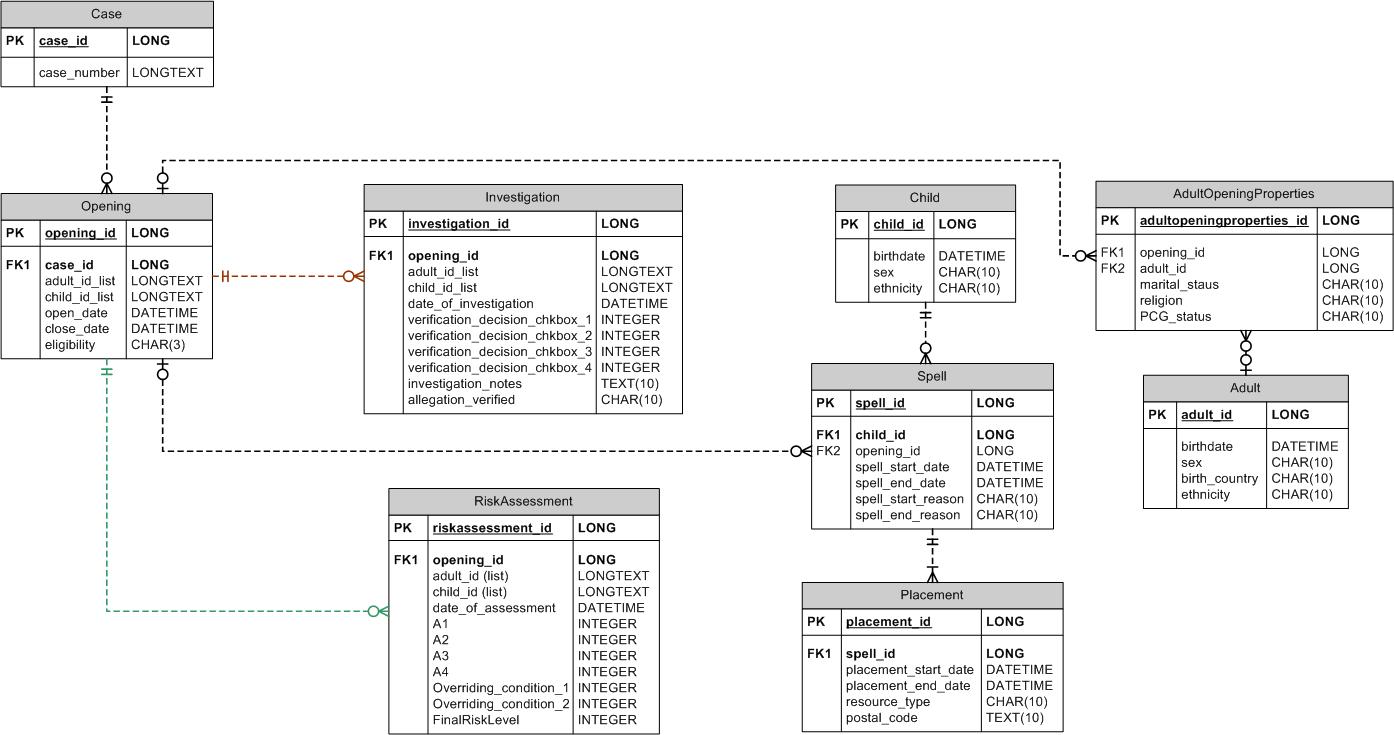
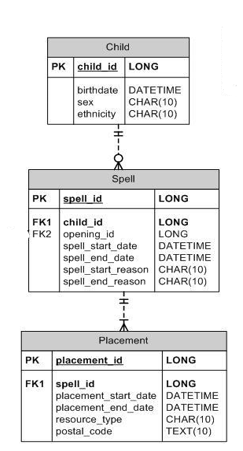
Note that there are multiple tables connected by common identifiers and containing different types of variables. There are also relationships. For example, the spell_id exists as a primary key on the spell table and as a foreign key on the placement table. The relationship between these two tables is such that a spell can have one to many placements. On the other hand, the placement table has a one to one relationship to child so each placement is linked to one child. I am not going to cover database concepts in this post but if this sort of thing interests you, I encourage you to read up on it. There are some great resources available online.
How to store information in metadata tables
Back to the above diagram. We want to be able to store this information in a way that programs can have access to it. Let’s store this information in two metadata tables: one for the table information and one for the variable information. The first, named meta.table, can store properties of the table like the primary key. The table named meta.variables has information such as variable data type, length, position in the table, formats, a link to a mapping scheme (more on this later), and flags describing the variable (for example, whether or not it is the main date field in the table).
A good starting point is SAS DICTIONARY tables. You can build on this base to add information that you will need in your environment. Having a means for systematically recovering the main date variable for a particular table was important for me so I added a field to store that meta information. You may have other bits of information that are valuable to your processes. You can store them in the metadata layer and build functions that can retrieve them when needed.
Returning the primary key for a table
Have a look at the tables included with this post to see what type of information I have stored in the meta.table and meta.variable tables. In building tools that retrieve this type of information, it is a good idea to refrain from using DATA steps or SQL queries in your implementation. You want the ability to use these tools at any point in your programs, so using the SAS Macro language is a good way to go. This is similar to the implementation of the %varlist function we covered on a previous post. Here is how we might create a function for getting the primary key in a table:
/*
Returns the primary key for a specified table.
EXAMPLE:
%getPrimaryKey(riskassessment);
*/
%MACRO getPrimaryKey(table);
%LOCAL primarykey vartable_id varname_vnum rc;
/* Go through variables for the specified table. */
%LET vartable_id = %SYSFUNC(open
(meta.variables (WHERE=(UPCASE(tablename)=UPCASE("&table") AND (isPrimaryKey=1))) ));
%LET varname_vnum = %SYSFUNC(varnum(&vartable_id,varname));
%LET rc = %SYSFUNC(fetchobs(&vartable_id,1));
%LET primarykey = %SYSFUNC(getvarc(&vartable_id, &varname_vnum));
%LET rc = %SYSFUNC(close(&vartable_id));
&primarykey
%MEND getPrimaryKey;
When opening the data set in this way, we have the option to specify a condition to limit the resulting rows that we can subsequently parse. Here, I’ve opened the meta.variables data set and requested only the rows where the variable “tablename” is equal to the &table parameter and the variable “isPrimaryKey” has a value of 1. You can refactor this macro to get the result from the meta.table data set instead. In my sample files, both tables have the primary key information stored in different ways. Storing the same information more than once is redundant: I’ve just included them as examples.
Returning a list of foreign keys
Here’s another metadata function, this time one that can return more than one thing. This macro will return all the foreign keys for a specified table in a convenient list format (convenient because we have already created tools that work with lists!).
/*
Returns the list of foreign keys for a specified table.
EXAMPLE:
%getForeignKeys(riskassessment);
*/
%MACRO getForeignKeys(table);
%LOCAL foreignkeys vartable_id varname_vnum rc i;
/* Go through variables for the specified table. */
%LET vartable_id = %SYSFUNC(open
(meta.variables (WHERE=(UPCASE(tablename)=UPCASE("&table") AND (isForeignKey=1))) ));
%LET varname_vnum = %SYSFUNC(varnum(&vartable_id,varname));
%LET i = 0;
%DO %UNTIL (%SYSFUNC(fetchobs(&vartable_id,&i)) = -1);
%IF (%SYSFUNC(getvarc(&vartable_id, &varname_vnum)) ^= %STR())
%THEN %DO;
%LET foreignkeys = &foreignkeys %SYSFUNC(getvarc(&vartable_id, &varname_vnum));
%END;
%LET i = %EVAL(&i + 1);
%END;
%LET rc = %SYSFUNC(close(&vartable_id));
&foreignkeys
%MEND getForeignKeys;
I have included a couple more functions in this post’s files: one that returns the list of tables that are in the database and another that returns the list of variables in a specified table. I have made an autoexec.sas that will %INCLUDE all the other sas programs so that you don’t have to run each one. All you have to do is open the autoexec.sas and fill in the %LET project = %STR(); line with the directory that you used and then run it. You can find all the programs and data referenced in this post at http://dontsasme.com/SASUserBlogSeries/Post4/. As usual, all previously covered tools are also included.
Feel free to play around. Think about some other metadata functions that might be handy and try making them yourself. Next time, I will continue with more metadata tables and functions that focus more on mapping.
