So let’s get down to it, what exactly do we mean by data in SAS? We hear all about “big data”, tiny data, datasets, metadata, OLAP, relational data, but what do I really need to know when it comes to SAS?
If we dig deep into the annals of SAS history, we have the SAS “dataset”. Then came along the need to read data from source systems (remember VSAM?), and ,of course, SAS’ ability to write to lots and lots of target systems such as files (Excel, CSV, delimited), databases (Oracle, DB2, Teradata) and unusual places (FTP, SMTP, WebDAV). For an experienced perspective on some of these unusual data sources, take a look at a paper by Steven First who takes us down memory lane.
I promised in my last post to start with an overview of how SAS “eats” data and what SAS cares about when processing data. So let’s start with what we mean by data.
How data is represented in SAS
Look at any spreadsheet and you’ll begin to understand the basics. We have rows and columns, and on the columns, we have additional information such as how the column is formatted (for example, date versus dollar versus lots of decimal points). Moving even higher, we have knowledge about the spreadsheet such as when it was created, how many records (or rows) it has, when it was last updated and by whom. We may also realize that there are lots of spreadsheets in our workbook. This simplistic description of a spreadsheet can be translated roughly to what we see in SAS. Here are the corollaries working our way from the Excel file down to the details:
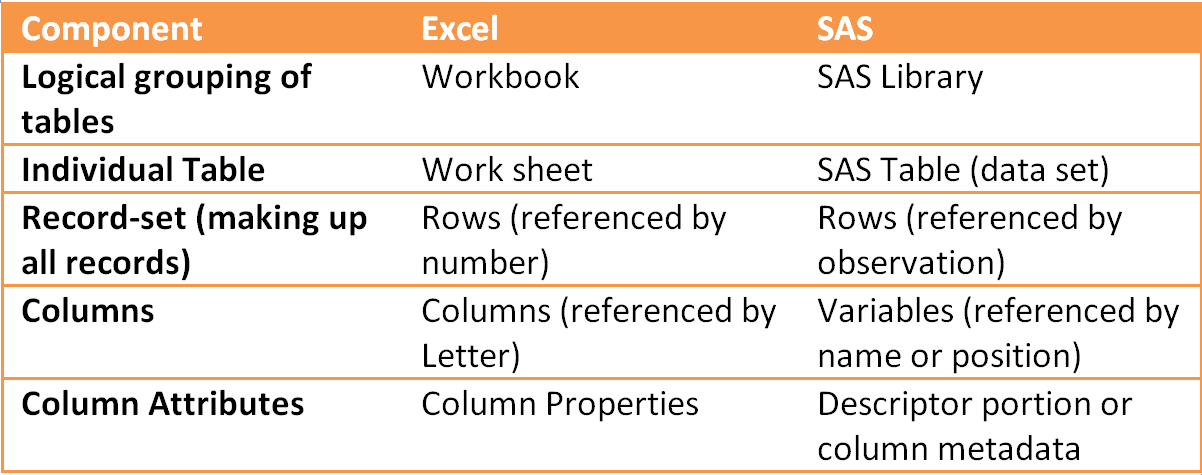
The spreadsheet analogy breaks down a bit when we deal with more complex structures like relationships (integrity constraints and foreign keys), dataset auditing, hierarchies and alternative SAS data structures like multidimensional databases (OLAP), Scalable Performance Data Server (SPDS) and its baby brother, Scalable Performance Data Engine (SPDE), generation data groups (collection of generation data sets), indexes and compression. But for now, we will keep it simple.
Referencing data
In SAS, when we read or write data, we generally do so by referencing the directory (through a LIBNAME statement) or the file directly (FILENAME statement). As we highlighted in the summary table above, the library is a collection of tables that exist in a directory on our system. In UNIX/ Linux this library might look like:
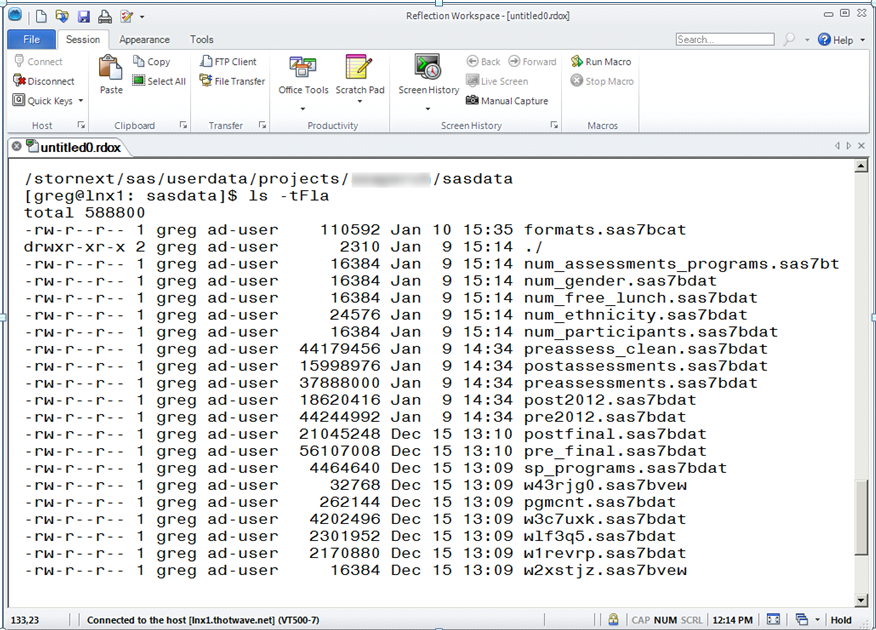
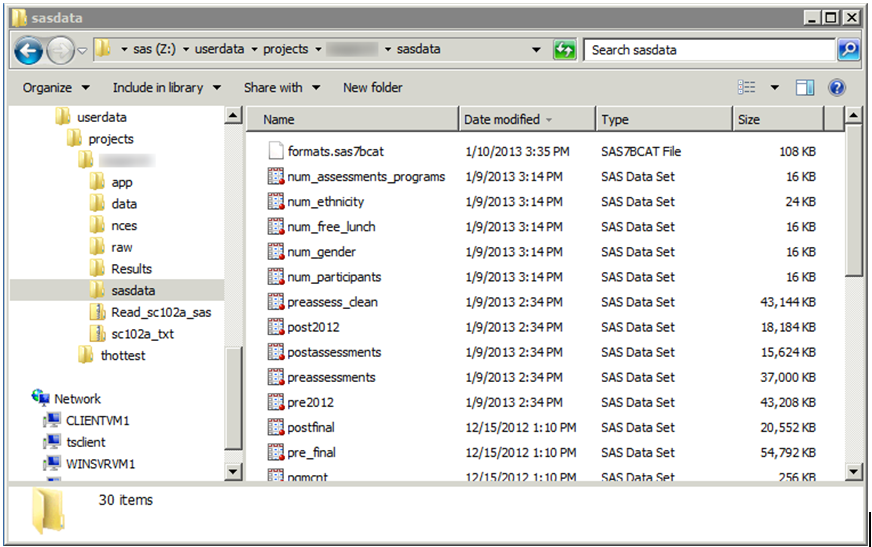
Similarly, we can see the same library on Windows.
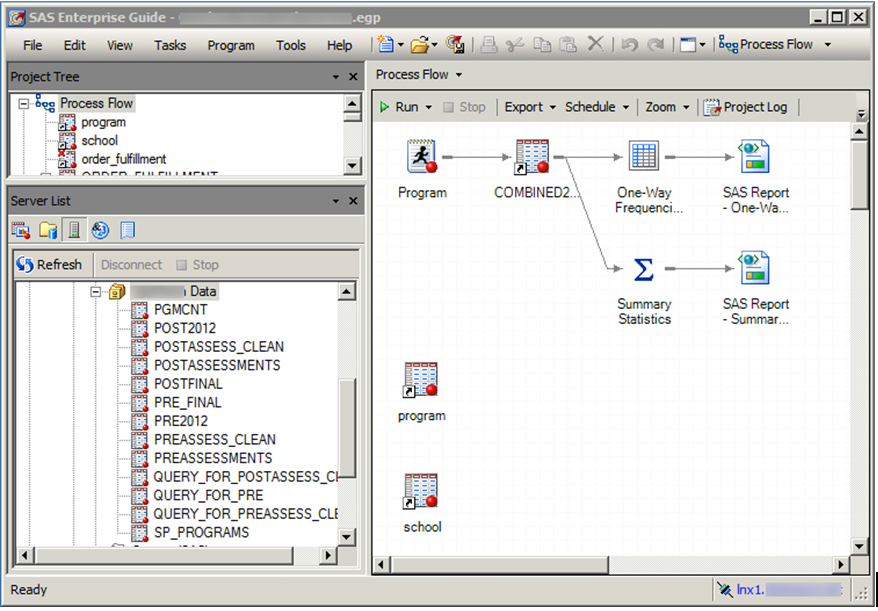
And finally, we see the same directory through SAS Enterprise Guide.
Since Version 9, SAS allows us to read and write files created on multiple operating systems through the use of something they call Cross-Environment Data Access, or CEDA. This feature makes data accessible when you move it from one system to another. If you require access to data that is not supported by CEDA, then you’ll have to move it around using some of the SAS utilities like one of these procedures: COPY, UPLOAD, DOWNLOAD, CPORT, CIMPORT or MIGRATE. For a nice summary of common migration questions, take a look at Diane Olson’s paper.
But I digress. So let’s go back to our screenshots above.
Assigning libnames and engines
If we want to reference this location, we assign a library reference (called LIBNAME) so SAS knows where this is and what engine it is going to use to read the file. The concept of an engine is pretty important in SAS as this entity provides the set of instructions to SAS for what we need to do in order to properly read (or write) the data. Here are a few examples of LIBNAME statements using various engines:

Note in the first case, we have an explicit engine called BASE that tells SAS that this is a SAS library. The engine is smart enough to figure out which version of SAS to use based on the files contained in the directory. If you omit an engine, SAS assumes that the BASE engine is being used.
When we issue the LIBNAME statement, SAS can now address tables in this library by name. All references to SAS tables have what is referred to as a two-level name. For example, if I want to reference the table postassessments in the directory above, I would tell reference the table by first adding the library where it resides before the filename, such as: mydata.postassessments
The basis of most procedures in SAS (known as PROCs) use this form to reference the data that is being processed. If I wanted to print the data, for example, I would issue the following statement:
PROC Print data=mydata.postassessments; run;
The difference between data and metadata
So this gets us to the point where we know how to reference data so that we can process it accordingly. In SAS Foundation (which includes the core SAS products such as BASE, STAT, GRAPH and so on), we write programs that utilize this library (LIBNAME) reference.
Up to this point, we have made the assumption that we will explicitly reference data in our program. Similarly, we make the assumption that whoever knows this path (or details in the LIBNAME statement) can use those same directives to issue their own LIBNAME statement.
Another huge assumption that we are making is that the data residing beneath that LIBNAME reference is accessible to the user running the program. That is, when I submit the following LIBNAME statement, I need to be able , at a minimum, to read the directory and the physical file that is being referenced:
LIBNAME mydata BASE “/userdata/project/mydata”;
This is one of the fundamental propositions of SAS data security: the physical operating system security takes precedence over SAS security that you may layer on top of the file. SAS mechanisms for security include password protection on the dataset, encryption, application level security and metadata security.
I promised in my last post that I wouldn’t step into the foray of metadata, but I lied. Next time, I will explore the concept of data as seen through the eyes of modern SAS clients such as SAS Enterprise Guide and Web Report Studio. There we will explore the main differences between accessing data directly (as we saw above with the LIBNAME statement) and accessing them through the metadata server. Soon thereafter, we will dive deep into external databases and how SAS processes data using various database engines.
Until then, remember – “Happy Data = Happy SAS = Happy Users = Happy Admin”! See, it really is all about the data!
--greg

3 Comments
Pingback: SAS metadata and third-party databases—an FAQ - SAS Users Groups
Pingback: Understanding SAS and third-party databases - SAS Users Groups
Pingback: Seeing SAS data through metadata - SAS Users Groups