Este recurso está diseñado principalmente para científicos de datos, analistas principiantes o intermedios que están interesados en identificar y aplicar algoritmos de machine learning para abordar los problemas de su interés.
Una pregunta típica de un principiante, cuando se enfrenta a una gran variedad de algoritmos de machine learning, es: ¿Qué algoritmo debo utilizar?. La respuesta a esta pregunta varía en función de muchos factores, entre ellos:
- El tamaño, la calidad y la naturaleza de los datos.
- El tiempo de cálculo disponible.
- La urgencia de la tarea.
- Lo que se quiere hacer con los datos.
Ni siquiera un científico de datos experimentado puede saber qué algoritmo será el mejor antes de probar diferentes algoritmos. No abogamos por un enfoque de un único uso, sin embargo, esperamos proporcionar algunas orientaciones sobre qué algoritmos probar primero en función de algunos factores claros.
Nota del editor: este post lo publicamos originalmente en 2017, pero ahora hemos añadido un video tutorial actualizado sobre este tema. De esta manera, podrá conocer cómo elegir un algoritmo de machine learning o seguir leyendo para encontrar una hoja de trucos, que ayudará a encontrar el algoritmo adecuado para su proyecto.
La hoja de trucos (acordeón, machete, etc.) del algoritmo de machine learning
La hoja de trucos del algoritmo de machine learning le ayuda a elegir entre una variedad de algoritmos de machine learning para encontrar el algoritmo adecuado para sus problemas específicos. Este artículo le guía a través del proceso de cómo utilizar la hoja.
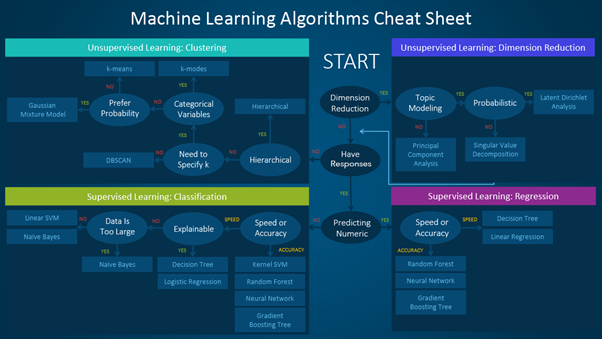
Dado que la hoja de trucos está diseñada para científicos de datos y analistas principiantes, haremos algunas suposiciones simplificadas al hablar de los algoritmos.
Los algoritmos recomendados aquí son el resultado de la recopilación de comentarios y consejos de varios científicos de datos y expertos en machine learning y desarrolladores. Hay varios temas en los que no hemos llegado a un acuerdo y, para estos temas, tratamos de destacar lo común y conciliar la diferencia.
Más adelante se añadirán otros algoritmos a medida que nuestra biblioteca crezca para abarcar un conjunto más completo de métodos disponibles.
Cómo utilizar la hoja de trucos de machine learning
Lea las etiquetas de ruta y algoritmo en la tabla como "Si <etiqueta de ruta> entonces use <algoritmo>". Por ejemplo:
- Si desea realizar una reducción de dimensiones, utilice el análisis de componentes principales.
- Si necesita una predicción numérica rápidamente, utilice árboles de decisión o regresión lineal.
- Si necesita un resultado jerárquico, utilice la agrupación jerárquica.
A veces se aplicará más de una rama, y otras ninguna de ellas será una combinación perfecta. Es importante recordar que estas rutas pretenden ser recomendaciones de regla general, por lo que algunas de las recomendaciones no son exactas. Varios científicos de datos con los que hablé dijeron que la única forma segura de encontrar el mejor algoritmo es probarlos todos.
Tipos de algoritmos de machine learning
Esta sección ofrece una visión general de los tipos más populares de machine learning. Si está familiarizado con estas categorías y quiere pasar a hablar de algoritmos específicos, puede saltarse esta sección e ir a "Cuándo utilizar algoritmos específicos" más abajo.
Aprendizaje supervisado
Los algoritmos de aprendizaje supervisado realizan predicciones basadas en un conjunto de ejemplos. Por ejemplo, las ventas históricas pueden utilizarse para estimar los precios futuros. Con el aprendizaje supervisado, usted tiene una variable de entrada que consiste en datos de entrenamiento etiquetados y una variable de salida deseada. Se utiliza un algoritmo para analizar los datos de entrenamiento y aprender la función que asigna la entrada a la salida. Esta función inferida mapea nuevos ejemplos desconocidos generalizando a partir de los datos de entrenamiento para anticipar resultados en situaciones no vistas.
- Clasificación: cuando los datos se utilizan para predecir una variable categórica, el aprendizaje supervisado también se denomina clasificación. Es el caso de asignar una etiqueta o indicador, ya sea perro o gato, a una imagen. Cuando solo hay dos etiquetas, se denomina clasificación binaria. Cuando hay más de dos categorías, los problemas se denominan clasificación multiclase.
- Regresión: cuando se predicen valores continuos, los problemas se convierten en un problema de regresión.
- Predicción: es el proceso de hacer predicciones sobre el futuro basándose en datos pasados y presentes. Se suele utilizar para analizar tendencias. Un ejemplo común podría ser una estimación de las ventas del año siguiente basada en las ventas del año actual y de los años anteriores.
Aprendizaje semisupervisado
El reto del aprendizaje supervisado es que el etiquetado de los datos puede ser costoso y requerir mucho tiempo. Si las etiquetas son limitadas, se pueden utilizar ejemplos no etiquetados para mejorar el aprendizaje supervisado. Como en este caso la máquina no está totalmente supervisada, decimos que la máquina es semisupervisada. Con el aprendizaje semisupervisado, se utilizan ejemplos no etiquetados con una pequeña cantidad de datos etiquetados para mejorar la precisión del aprendizaje.
Aprendizaje no supervisado
Cuando se realiza un aprendizaje no supervisado, la máquina se presenta con datos totalmente sin etiquetar. Se le pide que descubra los patrones intrínsecos que subyacen a los datos, como una estructura de clustering, un manifold de baja dimensión o un árbol y un gráfico dispersos.
- Agrupación: agrupar un conjunto de ejemplos de datos de manera que los ejemplos de un grupo (o un clúster) sean más similares (según algún criterio) que los de otros grupos. Suele utilizarse para segmentar el conjunto de datos en varios grupos. El análisis puede realizarse en cada grupo para ayudar a los usuarios a encontrar patrones intrínsecos.
- Reducción de la dimensión: reducción del número de variables consideradas. En muchas aplicaciones, los datos brutos tienen características de muy alta dimensionalidad y algunas características son redundantes o irrelevantes para la tarea. Reducir la dimensionalidad ayuda a encontrar la verdadera relación latente.
Aprendizaje por refuerzo
El aprendizaje por refuerzo es otra rama del machine learning, que se utiliza principalmente para problemas de toma de decisiones secuenciales. En este tipo de machine learning, a diferencia del aprendizaje supervisado y no supervisado, no necesitamos tener datos de antemano; en su lugar, el agente que aprende interactúa con un entorno y aprende la política óptima sobre la marcha, basándose en la retroalimentación que recibe de ese entorno. En concreto, en cada paso de tiempo, un agente observa el estado del entorno, elige una acción y observa la retroalimentación que recibe del entorno. La retroalimentación de la acción de un agente tiene muchos componentes importantes. Uno de ellos es el estado resultante del entorno después de que el agente haya actuado sobre éste. Otro componente es la recompensa (o el castigo) que recibe el agente por realizar esa acción concreta en ese estado concreto. La recompensa se elige cuidadosamente para que esté en consonancia con el objetivo para el que estamos entrenando al agente. Utilizando el estado y la recompensa, el agente actualiza su política de toma de decisiones para optimizar su recompensa a largo plazo. Con los recientes avances del aprendizaje profundo, el aprendizaje por refuerzo ha ganado una gran atención, ya que ha demostrado un rendimiento sorprendente en una amplia gama de aplicaciones, como los juegos, la robótica y el control. Para ver en acción modelos de aprendizaje por refuerzo como las redes Deep-Q y Fitted-Q, consulte este artículo.
Consideraciones al elegir un algoritmo para machine learning
A la hora de elegir un algoritmo, tenga siempre en cuenta estos aspectos: la precisión, el tiempo de entrenamiento y la facilidad de uso. Muchos usuarios dan prioridad a la precisión, mientras que los principiantes tienden a centrarse en los algoritmos que conocen mejor.
Cuando se presenta un conjunto de datos, lo primero que hay que tener en cuenta es cómo obtener los resultados, independientemente de cómo sean esos resultados. Los principiantes tienden a elegir algoritmos que son fáciles de implementar y que pueden obtener resultados rápidamente. Esto funciona bien, siempre que sea solo el primer paso del proceso. Una vez que obtenga algunos resultados y se familiarice con los datos, puede dedicar más tiempo a utilizar algoritmos más sofisticados para reforzar su comprensión de los datos y, por tanto, mejorar aún más los resultados.
Incluso en esta fase, es posible que los mejores algoritmos no sean los métodos que han logrado la mayor precisión declarada, ya que un algoritmo suele requerir un ajuste cuidadoso y un entrenamiento exhaustivo para obtener su mejor rendimiento posible.
Cuándo utilizar algoritmos específicos en machine learning
Un análisis más detallado de cada uno de los algoritmos puede ayudarle a entender qué aportan y cómo se utilizan. Estas descripciones proporcionan más detalles y dan consejos adicionales sobre cuándo utilizar algoritmos específicos, en consonancia con la hoja de trucos.
Regresión lineal y regresión logística
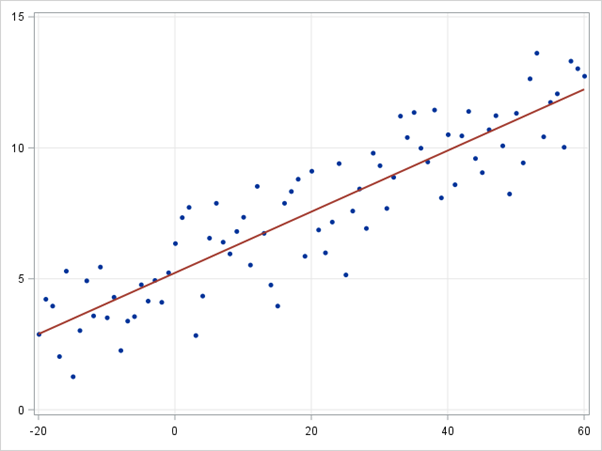
Regresión lineal
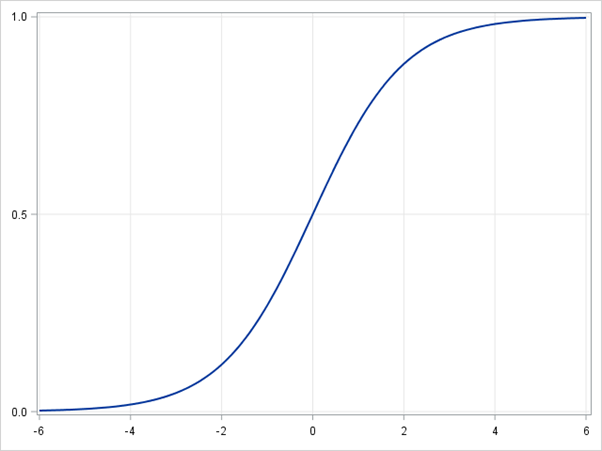 Regresión logística
Regresión logística
La regresión lineal es un enfoque para modelar la relación entre una variable dependiente continua y y uno o más predictores X. La relación entre Y y X puede modelarse linealmente como y=βTX+ϵ Dados los ejemplos de entrenamiento {xi,yi}Ni=1, se puede aprender el vector de parámetros β.
Si la variable dependiente no es continua sino categórica, la regresión lineal puede transformarse en regresión logística utilizando una función de enlace logit. La regresión logística es un algoritmo de clasificación sencillo, rápido y potente. Aquí tratamos el caso binario en el que la variable dependiente y sólo toma valores binarios {yi∈(-1,1)}Ni=1 (que puede extenderse fácilmente a problemas de clasificación multiclase).
En la regresión logística utilizamos una clase de hipótesis diferente para intentar predecir la probabilidad de que un ejemplo dado pertenezca a la clase "1" frente a la probabilidad de que pertenezca a la clase "-1". En concreto, intentaremos aprender una función de la forma: p(yi=1|xi)=σ(βTxi) y p(yi=-1|xi)=1-σ(βTxi). Aquí σ(x)=11+exp(-x) es una función sigmoidea. Dados los ejemplos de entrenamiento {xi,yi}Ni=1, el vector de parámetros β puede aprenderse maximizando la log-verosimilitud de β dado el conjunto de datos.
SVM lineal y kernel SVM
Los trucos del kernel se utilizan para mapear una función separable no linealmente en una función separable linealmente de mayor dimensión. Un algoritmo de entrenamiento de la máquina de vectores de soporte (SVM) encuentra el clasificador representado por el vector normal w y el sesgo b del hiperplano. Este hiperplano (límite) separa las diferentes clases con un margen lo más amplio posible. El problema se puede convertir en un problema de optimización con restricciones:
Minimize ||w||
w
subject to yi(wTXi−b)≥1,i=1,…,n.
Un algoritmo de entrenamiento de la máquina de vectores de soporte (SVM) encuentra el clasificador representado por el vector normal y el sesgo del hiperplano. Este hiperplano (frontera) separa las diferentes clases con un margen lo más amplio posible. El problema puede convertirse en un problema de optimización con restricciones:
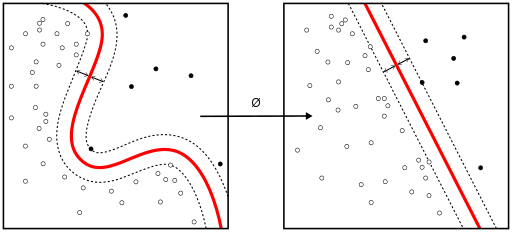
Cuando las clases no son linealmente separables, se puede utilizar un truco de kernel para mapear un espacio no linealmente separable en un espacio linealmente separable de mayor dimensión.
Cuando la mayoría de las variables dependientes son numéricas, la regresión logística y la SVM deberían ser el primer intento de clasificación. Estos modelos son fáciles de implementar, sus parámetros son fáciles de ajustar y su rendimiento también es bastante bueno. Por lo tanto, estos modelos son apropiados para los principiantes.
Árboles y conjuntos de árboles
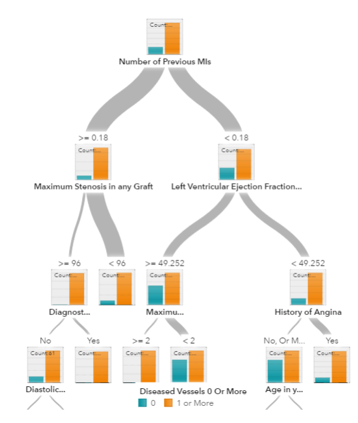
Los árboles de decisión, los bosques aleatorios y la potenciación de gradiente (gradient boosting) son algoritmos basados en árboles de decisión. Hay muchas variantes de árboles de decisión, pero todos hacen lo mismo: subdividir el espacio de características en regiones con la misma etiqueta en su mayoría. Los árboles de decisión son fáciles de entender e implementar. Sin embargo, tienden a sobreajustar los datos cuando agotamos las ramas y profundizamos mucho con los árboles. Los bosques aleatorios y la potenciación de gradiente son dos formas populares de utilizar algoritmos de árboles para lograr una buena precisión, así como para superar el problema de sobreajuste.
Redes neuronales y aprendizaje profundo
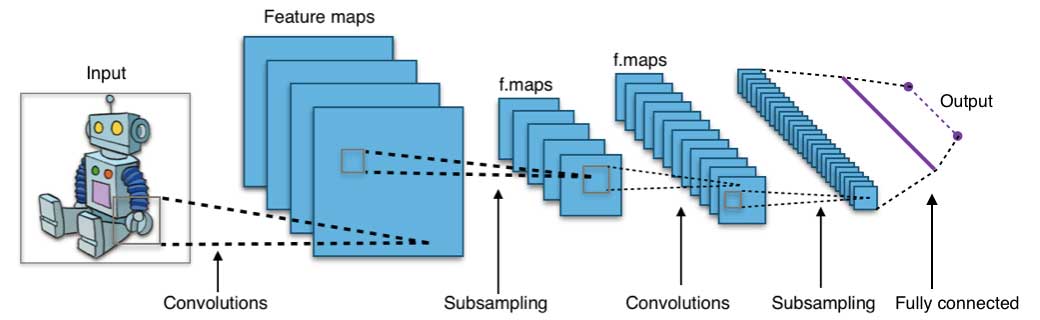
Las redes neuronales florecieron a mediados de la década de 1980 debido a su capacidad de procesamiento paralelo y distribuido. Sin embargo, la investigación en este campo se vio obstaculizada por la ineficacia del algoritmo de entrenamiento de retropropagación, muy utilizado para optimizar los parámetros de las redes neuronales. Las máquinas de vectores de apoyo (SVM) y otros modelos más sencillos, que pueden entrenarse fácilmente resolviendo problemas de optimización convexa, sustituyeron gradualmente a las redes neuronales en el machine learning.
En los últimos años, nuevas y mejores técnicas de entrenamiento, como el preentrenamiento no supervisado y el entrenamiento codicioso por capas, han hecho resurgir el interés por las redes neuronales. Las capacidades computacionales cada vez más potentes, como la unidad de procesamiento gráfico (GPU) y el procesamiento paralelo masivo (MPP), también han estimulado la adopción renovada de las redes neuronales. El resurgimiento de la investigación en redes neuronales ha dado lugar a la invención de modelos con miles de capas.
En otras palabras, las redes neuronales superficiales han evolucionado hasta convertirse en redes neuronales de aprendizaje profundo. Las redes neuronales profundas han tenido mucho éxito en el aprendizaje supervisado. Cuando se utilizan para el reconocimiento del habla y de las imágenes, el aprendizaje profundo funciona tan bien, o incluso mejor, que los humanos. Aplicado a tareas de aprendizaje no supervisado, como la extracción de características, el aprendizaje profundo también extrae características de las imágenes o el habla sin procesar con mucha menos intervención humana.
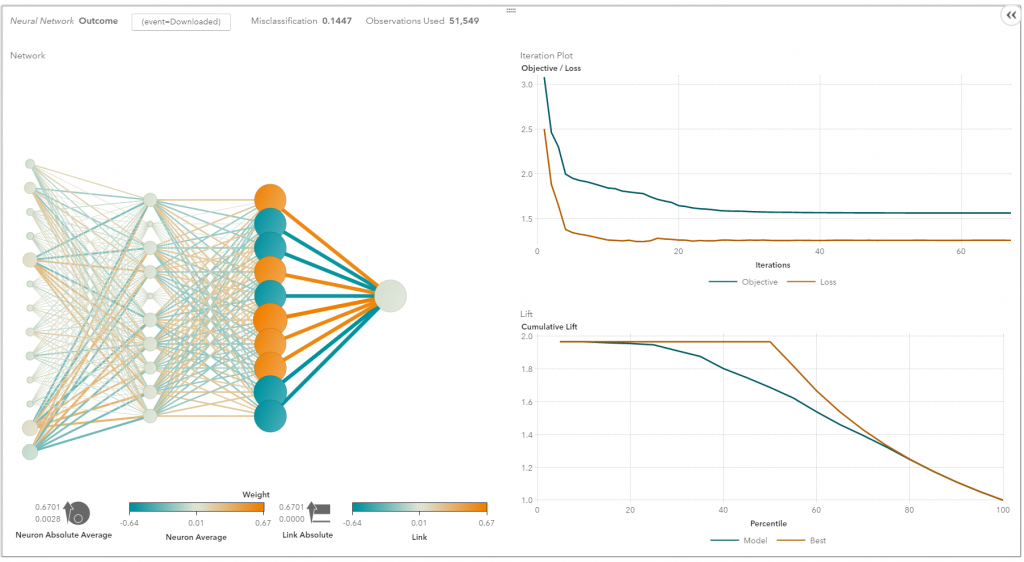
Una red neuronal consta de tres partes: capa de entrada, capas ocultas y capa de salida. Las muestras de entrenamiento definen las capas de entrada y de salida. Cuando la capa de salida es una variable categórica, la red neuronal es una forma de abordar los problemas de clasificación. Cuando la capa de salida es una variable continua, entonces la red puede utilizarse para hacer regresión. Cuando la capa de salida es la misma que la de entrada, la red puede utilizarse para extraer características intrínsecas. El número de capas ocultas define la complejidad del modelo y la capacidad de modelado.
Clustering de k-medias/k-modos, GMM (modelo de mezcla gaussiana)
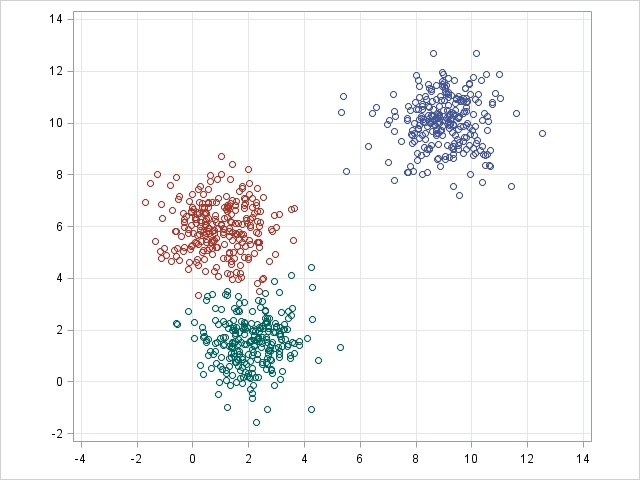
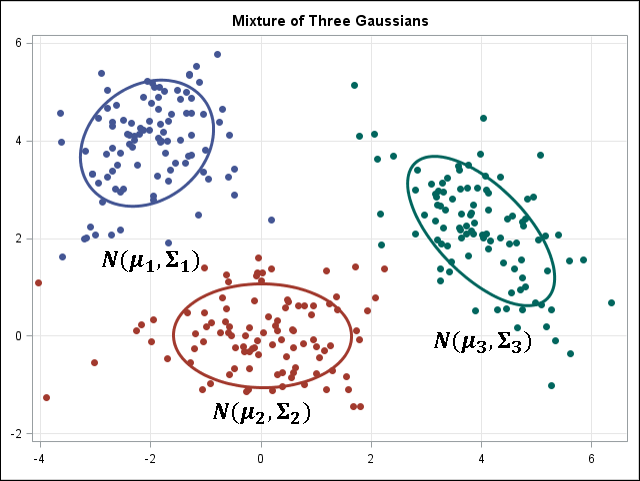
Los Kmeans/k-modes, y el clustering GMM tienen como objetivo dividir n observaciones en k clústeres. K-means define una asignación dura: las muestras deben estar y sólo estar asociadas a un clúster. GMM, sin embargo, define una asignación blanda para cada muestra. Cada muestra tiene una probabilidad de ser asociada a cada clúster. Ambos algoritmos son lo suficientemente sencillos y rápidos para la agrupación cuando se da el número de clústeres k.
DBSCAN
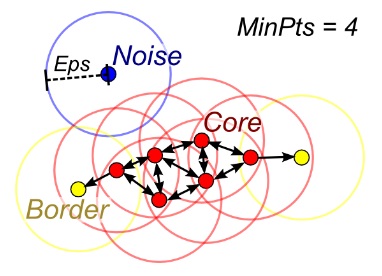
Cuando no se da el número de clústeres k, se puede utilizar el DBSCAN (clustering espacial basado en la densidad) conectando las muestras a través de la difusión de la densidad.
Clustering jerárquico
Las particiones jerárquicas pueden visualizarse mediante una estructura de árbol (un dendrograma). No necesita el número de clústeres como entrada y las particiones pueden visualizarse a diferentes niveles de granularidad (es decir, puede refinar/engrosar los clústeres) utilizando diferentes K.
PCA, SVD y LDA
Por lo general, no queremos introducir un gran número de características directamente en un algoritmo de machine learning, ya que algunas características pueden ser irrelevantes o la dimensionalidad "intrínseca" puede ser menor que el número de características. El análisis de componentes principales (PCA), la descomposición del valor singular (SVD) y la asignación de Dirichlet latente (LDA) pueden utilizarse para reducir la dimensión.
El PCA es un método de clustering no supervisado que mapea el espacio de datos original en un espacio de menor dimensión preservando toda la información posible. El PCA básicamente encuentra un subespacio que preserva al máximo la varianza de los datos, con el subespacio definido por los vectores propios dominantes de la matriz de covarianza de los datos.
La SVD está relacionada con el PCA en el sentido de que la SVD de la matriz de datos centrada (características frente a muestras) proporciona los vectores singulares dominantes de la izquierda que definen el mismo subespacio encontrado por el PCA. Sin embargo, la SVD es una técnica más versátil, ya que también puede hacer cosas que el PCA no puede hacer. Por ejemplo, la SVD de una matriz usuario-película es capaz de extraer los perfiles de los usuarios y de las películas que pueden utilizarse en un sistema de recomendación. Además, la SVD también se utiliza ampliamente como herramienta de modelado de temas, conocida como análisis semántico latente, en el procesamiento del lenguaje natural (PLN).
Una técnica relacionada en PNL es la asignación de Dirichlet latente (LDA). El LDA es un modelo temático probabilístico que descompone los documentos en temas de forma similar a como un modelo de mezcla gaussiana (GMM) descompone los datos continuos en densidades gaussianas. A diferencia del GMM, un LDA modela datos discretos (palabras en los documentos) y restringe que los temas se distribuyan a priori según una distribución Dirichlet.
Conclusiones
Este es el flujo de trabajo que es fácil de seguir. Los mensajes que hay que extraer cuando se trata de resolver un nuevo problema son:
- Definir el problema. ¿Cuál problema quiere resolver?
- Empezar de forma sencilla. Familiarícese con los datos y los resultados de referencia.
- Luego, intente algo más complicado.
SAS Visual Data Mining and Machine Learning proporciona una buena plataforma para que los principiantes aprendan machine learning y apliquen los métodos de machine learning a sus problemas. Regístrese hoy mismo para obtener una prueba gratuita.
