Modelos de machine learning estão cada dia mais em alta no mercado de trabalho. Mas o que são esses modelos? Por que eles ganharam tanto destaque? Por que todos querem usar?
Gosto de dizer que modelos de machine learning são modelos estatísticos acrescidos de poder computacional, e que as empresas querem usá-los pois estão aumentando seus níveis de maturidade com relação a analytics e entendendo melhor os benefícios que estes modelos podem trazer.
Para apoiar essas empresas no caminho rumo ao uso de machine learning, costumo sugerir um roadmap de 9 passos para o desenvolvimento de um modelo preditivo. É importante ressaltar, de qualquer forma, que isso não é uma receita de bolo, mas sim um direcionamento para facilitar os primeiros passos daqueles que querem construir um modelo preditivo eficaz.
1.Definição do problema
A primeira coisa que precisamos fazer é definir o problema que queremos resolver. Iniciar com perguntas pertinentes à área de negócio é um bom começo. Após definir o problema - ou seja, qual é o objetivo, resposta, dependente, target (como queira chamar) que queremos prever e o seu tipo (nominal, ordinal, contínua, binária, etc) -, precisamos também especificar a necessidade relacionada à questão que estamos tentando responder, pois isso ajuda na seleção das técnicas de modelagem mais apropriadas.
2.Captura de dados
 É nessa fase que analisamos as fontes das quais poderão ser extraídos os dados, tanto a variável-resposta (target), como as variáveis independentes, ou seja, que serão utilizadas para explicar meu evento de interesse. Esses dados podem estar em diferentes formatos e vir de diferentes fontes, por isso há a necessidade de consolidação e tratamento (verificar a qualidade dos dados), para que os dados brutos possam ser usados como entrada na modelagem preditiva.
É nessa fase que analisamos as fontes das quais poderão ser extraídos os dados, tanto a variável-resposta (target), como as variáveis independentes, ou seja, que serão utilizadas para explicar meu evento de interesse. Esses dados podem estar em diferentes formatos e vir de diferentes fontes, por isso há a necessidade de consolidação e tratamento (verificar a qualidade dos dados), para que os dados brutos possam ser usados como entrada na modelagem preditiva.
A parte de preparação está cada vez mais desafiadora devido à grande quantidade de informação que vem sendo armazenada e muito tempo é gasto aqui.
3.Amostragem
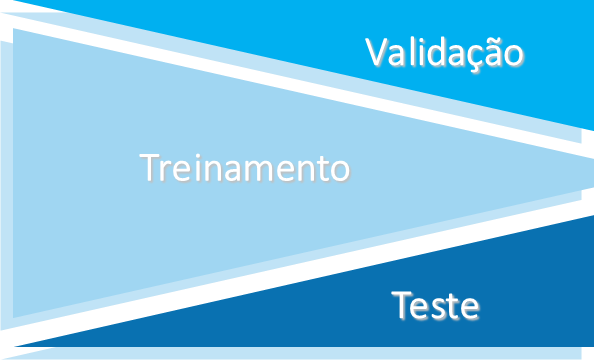 O objetivo dos modelos preditivos é a generalização, ou seja, a habilidade de prever a variável-target para novos casos. Por isso, não basta apenas ajustar um modelo, precisamos verificar se a generalização está ocorrendo de forma efetiva. Para isso podemos dividir a base de estudo em treinamento (ajustar alguns modelos), validação (verificar a qualidade dos modelos ajustados e escolher o modelo campeão) e teste (avalia o modelo campeão).
O objetivo dos modelos preditivos é a generalização, ou seja, a habilidade de prever a variável-target para novos casos. Por isso, não basta apenas ajustar um modelo, precisamos verificar se a generalização está ocorrendo de forma efetiva. Para isso podemos dividir a base de estudo em treinamento (ajustar alguns modelos), validação (verificar a qualidade dos modelos ajustados e escolher o modelo campeão) e teste (avalia o modelo campeão).
Mas porque essa divisão? Quando ajustamos um modelo nos dados de treinamento esse modelo pode ser simples ou complexo demais. Como não queremos que isso aconteça, pois afetará a previsibilidade, a ideia é encontrar um modelo que se comporta de forma parecida na base de treinamento e teste. Utilizar a mesma base para ajustar um modelo e verificar a qualidade do ajuste pode levá-lo ao princípio do otimismo, onde você acha que o modelo generaliza bem, mas ao utilizá-lo em uma base-teste verifica que isto não ocorre.
4.Exploração
Aqui é onde abrangemos tanto a parte da estatística descritiva como a diagnóstica, ou seja, exploramos os dados procurando tendências ou anomalias inesperadas para obter uma melhor compreensão e assim entender o que, e por que, aconteceu. Precisamos saber com o que estamos trabalhando. Verificar as distribuições das variáveis que pretendemos usar e as relações bivariadas entre todas as variáveis que podem entrar no modelo é uma maneira de começar.
5.Transformação
![]() Ao examinar os dados, na fase de exploração, você pode encontrar a necessidade de criar, transformar, excluir ou combinar variáveis a fim de construir o modelo.
Ao examinar os dados, na fase de exploração, você pode encontrar a necessidade de criar, transformar, excluir ou combinar variáveis a fim de construir o modelo.
Esta etapa é considerada uma das mais demoradas. Por isso, ter um direcionamento pode facilitar o processo. Seguem alguns passos que podem ser realizados:
• Tratamento de missing (valores faltantes)
• Agrupamento dos níveis para variáveis categóricas
• Criação de variáveis secundárias, ou seja, derivadas das variáveis originais, como por exemplo: consolidado dos últimos 3 meses de vendas, se ocorreu ou não uma promoção nos últimos 12 meses.
• Exclusão de variáveis redundantes (variáveis independentes altamente correlacionadas) e irrelevantes (variável independente com baixa correlação com a resposta, ou seja, não contribui para sua previsão).
6.Seleção
Após a realização de todos os tratamentos necessários chegou o momento de selecionar as variáveis que serão utilizadas na construção do modelo final. Os métodos mais conhecidos para esta fase são:
- Forward (variável entrou não sai mais): Começamos a construção do modelo sem nenhuma variável. Em cada um dos passos seguintes a variável selecionada é a que aumenta a explicabilidade do modelo. Esse processo é finalizado quando nenhuma das variáveis restantes for significativa.
- Backward (variável saiu não entra mais): O processo de construção do modelo se inicia com a inclusão de todas as variáveis. A cada passo a variável menos significante é removida e assim por diante até que nenhuma variável não significativa permaneça.
- Stepwise (variável pode entrar e sair a qualquer momento): É uma combinação das técnicas forward e backward.
7.Modelagem
Enfim, o passo mais esperado. Todo esse trabalho de preparação até aqui faz com que este passo seja mais “simples”. Com base no tipo da variável resposta e no seu objetivo, definidos no primeiro passo, escolhemos algumas técnicas de modelagem para ajustar modelos na base de treinamento. Conforme quadro a seguir.

8.Avaliação
Após ajustar os vários modelos na base de treinamento, precisamos definir qual será o modelo final utilizado para fazer as futuras previsões. Para isso, conforme discutido no tópico de amostragem, é necessário escolher uma métrica de ajuste e comparar o resultado de todos os modelos na base de validação. O modelo com a melhor estatística, na base de validação, é escolhido como o modelo campeão. A base de teste é utilizada para verificar a consistência do modelo escolhido como campeão, como se fossemos prever o que aconteceria se colocássemos o modelo em produção.
9.Produção
Após colocar o modelo em produção, devemos monitorá-lo em intervalos de tempo recorrentes para identificar se a performance está sendo mantida. Se for identificada a perda de performance, o modelo deverá ser atualizado para que continue a produzir os resultados desejados. A ideia é criar um loop contínuo de aprendizado o que torna o processo um ciclo - conhecido como ciclo analítico, como podemos ver na figura a seguir.
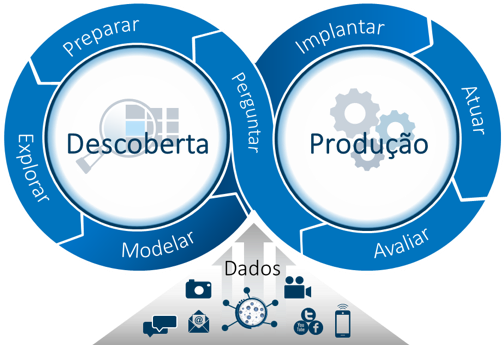
Espero ter colaborado um pouco para esclarecer algumas ideias com relação aos passos que devem ser seguidos para construir um modelo analítico.

1 Comment
Bom dia,
Cristiane,
tudo bem?
Gostaria de saber se vc tem algum canal no youtube, ensinando estatistica?
muito obrigado.
atenciosamente:
Wagne das chaga