1. はじめに
前回投稿しました「SAS/ACCESSのご紹介とSnowflakeとの連携デモ」はご覧になったでしょうか。SASと外部のデータストレージサービスを連携する「SAS/ACCESS」のご紹介と、実際に「Snowflake」というサービスに連携してみました。今回は、その続きとして、10年以上前からビッグデータ・アナリティクスの基本アーキテクチャである、In-Database機能の代表的な機能である、SQLパススルーという機能をご説明し、デモを準備しました。
2. SQLパススルーについて
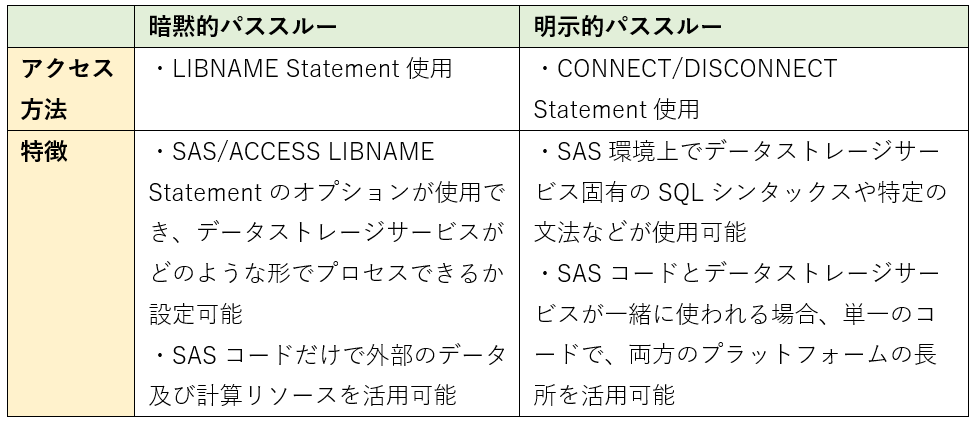
SAS/ACCESS がインストールされている場合、SQLパススルーを使用してデータストレージサービスにクエリできます。接続方法に応じてSQLパススルーは、「暗黙的パススルー」と「明示的パススルー」に分けることができます。
暗黙的パススルーの価値は、作成したSASコードが自動的にデータストレージサービスが処理できるSQLに変換され、そのSQLをデータストレージサービス側に与えることにあります。ですので、SASで実行されたSQLやSASプロシジャに指定されたWHERE句など、可能な限りデータストレージサービス側で処理を行い、結果だけをSAS側に転送することが可能です。一方、明示的パススルーの場合には、DB依存のSQLを明示的に記述することできます。暗黙的パススルーと明示的パススルーについてまとめた表を下に記載していますので、ご覧ください。今回は、暗黙的パススルーについて詳しくご紹介したいと思います。

▲SAS CommunityでSQL Pass throughについて質問するユーザー
暗黙的パススルーを使用する方が良いか、明示的パススルーを使用するのが良いのか気になるかと思います。実はこのトピックは、SAS Communityでもよく見られ、SAS/ ACCESSを使用している全世界のユーザーにとっても気になる質問です。どちらを使用するかは、どこに基準を置くか、また、SASとデータストレージサービスの環境のスペックによって異なると思います。ですので、皆さんもこのような疑問が生じた場合は、SASに相談してみてはいかがでしょうか。
3. 暗黙的パススルーのデモ
3-1. データの紹介とデモの概要
今回のデモのために、「pets」と「owners」という名前で2つのテーブルをデータストレージサービス(今回は、Snowflake)側に事前に保存しておきました。
「pets」テーブルには、3つのカラムがあります。
- Id: ペット固有のid
- Name: ペットの名前
- Type: ペットの種類(犬、猫、その他)
| Id | Name | Type |
| 1 | オオビ | 犬 |
| 2 | ローザ | 猫 |
| 3 | ワンチャン | その他 |
| … | … | … |
もう1つのテーブル「owners」にも3つのカラムがあります。
- Id: オーナー固有のid
- Name: オーナーの名前
- Pet_id: オーナーが持っているペットのID番号(ペットテーブルのペットのID番号と一致)
| Id | Name | Pet_id |
| 1 | 小林絵里 | 2 |
| 2 | エリック直美 | 1 |
| 3 | 川口直子 | 3 |
| … | … | … |
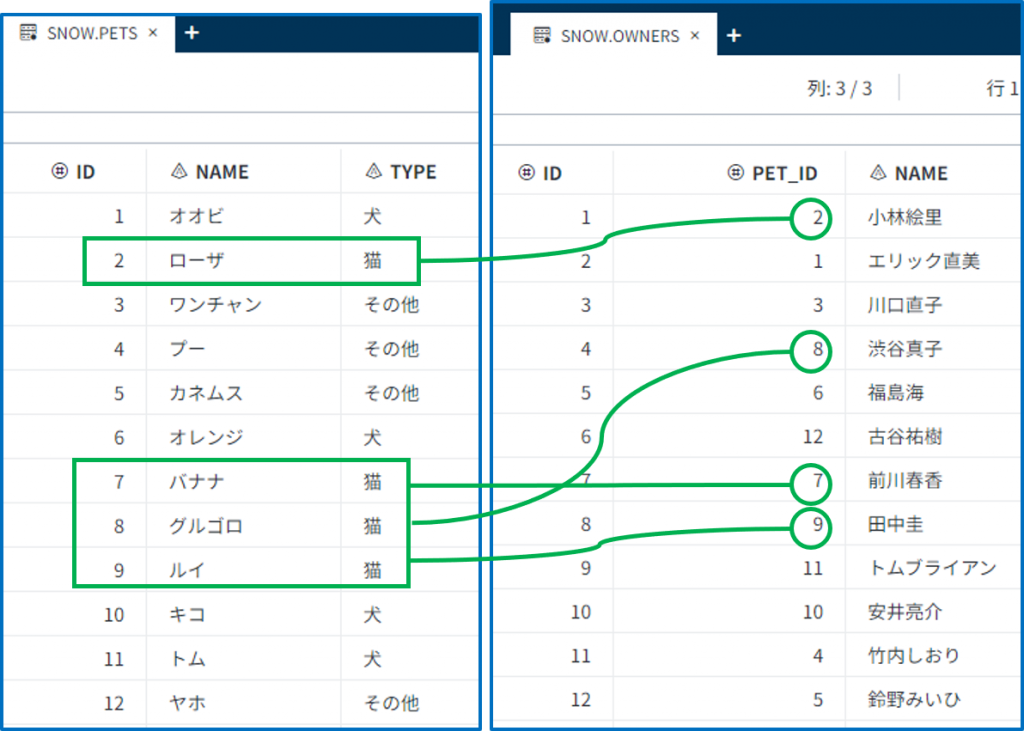
デモでは、暗黙的パススルーを使って「猫を持っているオーナーとそのペット」の情報を出力したいと思います。暗黙的パススルーを用いたら、SAS言語だけでSAS環境から必要なデータ処理や分析を行うことができますので、データストレージサービス固有のSQL知識がなくても大丈夫です。
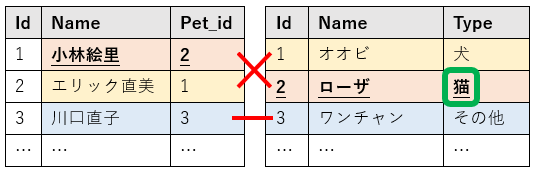 ▲「猫を持っているオーナーとそのペット」のイメージ
▲「猫を持っているオーナーとそのペット」のイメージ
3-2. SAS Viyaの画面で左上にある「ナビゲーター」を押します。
3-3. SAS Studioに移動するため、「SASコードの開発」を選択します。
3-4. SAS Studioで新規プログラムを作り、連携のコードを作成します。

暗黙的パススルーは基本的に、SASライブラリ定義のオプションでその挙動を制御します。
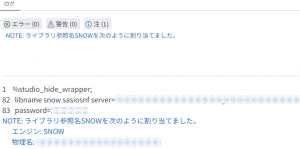
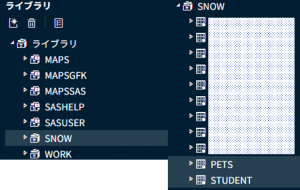
3-5. 実行後、ログと作成したライブラリに問題がないか確認します。ログからきちんとライブラリが作成できたことがわかりました。ライブラリ一覧からは「SNOW」というライブラリが確認でき、その中には「pets」と「owners」のテーブルも入ったことが分かります。
3-6. 「pets」と「owners」のテーブルのデータも確認します。3-1. デモの概要で話した通り、今回は、ペットの中でも猫を選んで、その情報と、主人の番号(id)と名前を出したいと思います。下記のイメージで緑の線で表示されたデータを読みこむと考えることができます。
3-7. SAS StudioでPROC SORT、DATA文を作成し、実行します。
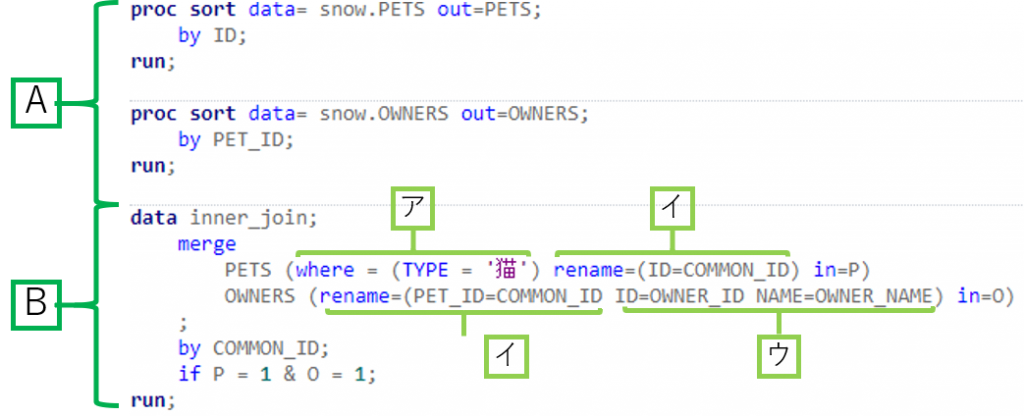
A.
(1) Snowflakeからデータを読み込んできます。下記のログを見ると、SAS言語である「PROC SORT」句がSQLパススルーされ、Snowflake側が理解できるSQLに自動作成された様子が確認できます。ソートの条件に従ってSnowflake側から呼ばれたデータは、SASのデフォルトディレクトリの「work」に保存されます。
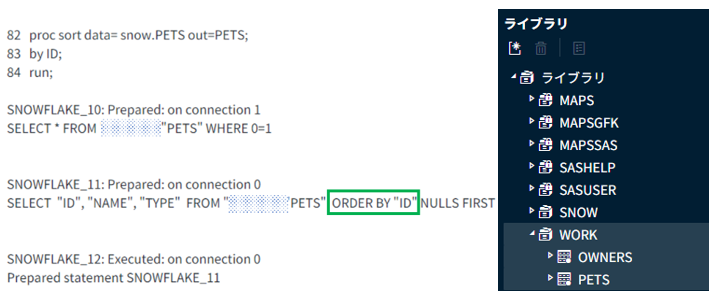
(2) 作成したコードについて少し説明すると、「PETS」テーブルのカラムIDが「OWNERS」テーブルのカラムPET_IDと一致しているので、PETSのテーブルの場合は、IDにソート、OWNERSの場合は、PET_IDを基準としてソートしました。
B. 「PROC SORT」でソートが終わった2つのテーブルをマージして必要な情報だけ出力します。
(ア) PETSのタイプは猫だけ選択するため、where句に「TYPE = ‘猫’」という条件を入れました。
(イ) また、マージの基準になるカラム名を同じ名前にするため、renameオプションを追加しました。
(ウ) 出力した結果をもっと理解しやすくするために、「OWNERS」テーブルのカラムでIDは、OWNER_IDに、NAMEは、 OWNER_NAMEにカラム名を変更しました。
(エ) マージの結果を確認すると、ペットの中でも猫ちゃんだけ選択し、ペットの名前はもちろん、オーナーの情報を取得できたことが分かります。
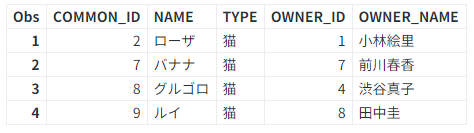
ところで、皆さん、質問があります。

データが非常に大きい場合、この処理方式の問題点は何だと思いますか?
3-8. 質問の答えは、データストレージからSASへと大きなデータ移動が発生しているため、処理時間がかかってしまうことです。ビッグデータ分析の原則は、「データの移動を最小化」することです。もちろんそのアーキテクチャの性質から、データストレージ側が苦手とする機械学習的な処理はSASで実施た方が効率的ですが、そのためのデータ加工は、極力データストレージ側で実行したいものです。もちろん、SASのマージ処理は非常に柔軟性に富んでいるので、上記の記述が解決策の場合もありますが、今回の場合は非常に単純な処理のため、SQLに簡単に変換できることから、この暗黙的パススルーの恩恵を最大限に受けることができます。
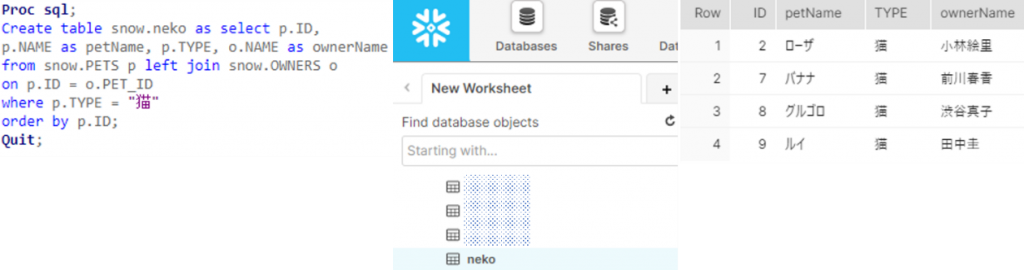
ログを確認すると、SASで作成したPROC SQL句がデータストレージサービス側が理解できるSQLに自動的に変換され、渡されたことが分かります。

今までの動作をまとめて考えるため、下記のフロー図を用意してみました。また、フローを作成する方法について動画を用意しましたので、ご参考ください。
SAS Viyaの最新リリースでは、同様のSQL処理をコーディングすることなく作成・実行することが可能です。このように、ポイント&クリックでクエリを作成するだけで自動的に強力なデータストレージサービスのパフォーマンスを享受することが可能となります。
3-9. より良いアーキテクチャのためにはPROC SORTとマージの方が良いでしょうか、それとも、PROC SQLの方が良いでしょうか。今回は、
- マージの結果が複数のデータセットではなく、1つのデータセットだけ
- マージするテーブルが2つしかない
- マージの条件になるカラム名が異なる
ので、PROC SQLの方が効果的でした。しかし、マージの結果で複数のデータセットが必要な場合や256以上のデータセットをマージする場合など色々な条件によって「より良い仕組み」、「より良いアーキテクチャ」の正解は異なりますので、是非SASまでにお問い合わせください。
4. おわりに
今回のブログでは、SAS/ACCESSのSQL Pass-Throughについて詳しくお伝えしました。デモでは、データストレージサービスの特定のシンタックスを身に着ける必要がなく、SAS言語だけでデータの処理や分析ができる暗黙的パススルーについてご紹介しました。昨年開かれたSASグローバルフォーラムでもこちらのテーマに関するセッションがありましたので、参考資料も合わせてご覧ください。最後まで読んでいただきありがとうございました。