This blog post could be subtitled "To Catch a Thief" or maybe "Go ahead. Steal this blog. I dare you."* That's because I've used this technique several times to catch and report other web sites who lift the blog content from blogs.sas.com and present it as their own.
Syndicating blog content is an honorable practice, made possible by RSS feeds that virtually every blog platform supports. With syndicated feeds, your blog content can appear on someone else's site, but this always includes attribution and a link back to the original source. However, if you copy content from another website and publish it natively on your own web property, without attribution or citations...well, that's called plagiarism. And the Digital Millennium Copyright Act (DCMA) provides authors with recourse to have stolen content removed from infringing sites -- if you can establish that you're the rightful copyright owner.
Establishing ownership is a tedious task, especially when someone steals dozens or hundreds of articles. You must provide links to each example of infringing content, along with links to the original authorized content. Fortunately, as I've discussed before, I have ready access to the data about all 17,000+ blog posts that we've published at SAS (see How SAS uses SAS to Analyze SAS Blogs). In this article, I'll show you how I gathered that same information from the infringing websites so that I could file the DCMA "paperwork" almost automatically.
The complete programs from this article are available on GitHub.
Read a JSON feed using the JSON engine
In my experience, the people who steal our blog content don't splurge on fancy custom web sites. They tend to use free or low-cost web site platforms, and the most popular of these include WordPress (operated by Automattic) and Blogspot (operated by Google). Both of these platforms support API-like syndication using feeds.
Blogspot sites can generate article feeds in either XML or JSON. I prefer JSON when it's available, as I find that the JSON libname engine in SAS requires fewer "clues" in order to generate useful tables. (See documentation for the JSON engine.) While you can supply a JSON map file that tells SAS how to assemble your tables and data types, I find it just as easy to read the data as-is and post-process it to join the fields I need and convert data fields. (For an example that uses a JSON map, see Reading data with the SAS JSON libname engine.)
Since I don't want to draw attention to the specific infringing sites, I'll use an example of a popular (legitimate!) Blogspot site named "Maps Mania". If you're into data and maps (who isn't?) you might like their content. In this code I use PROC HTTP to fetch the RSS feed, using "alt=json" to request JSON format and "max-results=100" to retrieve a larger-than-default batch of published posts.
/* Read JSON feed into a local file. */ /* Use Blogspot parameters to get 100 posts at a time */ filename resp temp; proc http url='https://googlemapsmania.blogspot.com/feeds/posts/default?alt=json&max-results=100' method="get" out=resp; run; libname rss json fileref=resp; |
This JSON libname breaks the data into a series of tables that relate to each other via common keys.
With a little bit of exploration in SAS Enterprise Guide and the Query Builder, I was able to design a PROC SQL step to assemble just the fields and records I needed: post title and post URL.
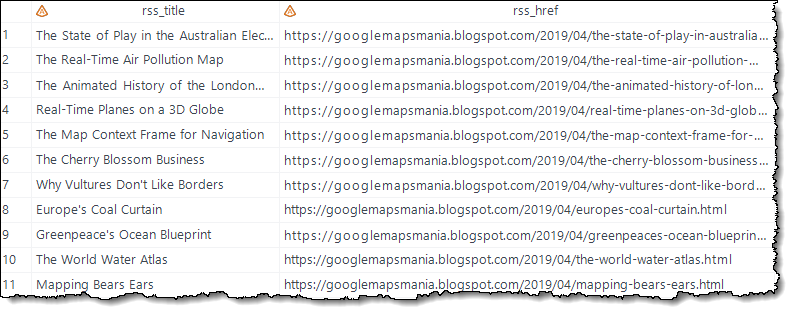
/* Join the relevant feed entry items to make a single table */ /* with post titles and URLs */ proc sql; create table work.blogspot as select t2._t as rss_title, t1.href as rss_href from rss.entry_link t1 inner join rss.entry_title t2 on (t1.ordinal_entry = t2.ordinal_entry) where t1.type = 'text/html' and t1.rel = 'alternate'; quit; libname rss clear; |
Read an XML feed using the XMLv2 engine
WordPress sites generate XML-based feeds by default. Site owners can install a WordPress plugin to generate JSON feeds as well, but most sites don't bother with that. Like the JSON feeds, the XML feed can contain many fields that relate to each other. I find that with XML, the best approach is to use the SAS XML Mapper application to explore the XML and "design" the final data tables that you need. You use SAS XML Mapper to create a map file, which you can then feed into the SAS XMLv2 engine to instruct SAS how to read the data. (See documentation for the XMLv2 engine.)
SAS XML Mapper is available as a free download from support.sas.com. Download it as a ZIP file (on Windows), and extract the ZIP file to a temporary folder. Then run setup.exe in the root of that folder to install the app on your system.
To design the map, I use an example of the XML feed from the blog that I want to examine. Once again, I'll choose a popular WordPress blog instead of the actual infringing sites. In this case, let's look at the Star Wars News site. I point my browser at the feed address is https://www.starwars.com/news/feed and save as an XML file. Then, I use SAS XML Mapper to Open XML (File menu), and examine the result.
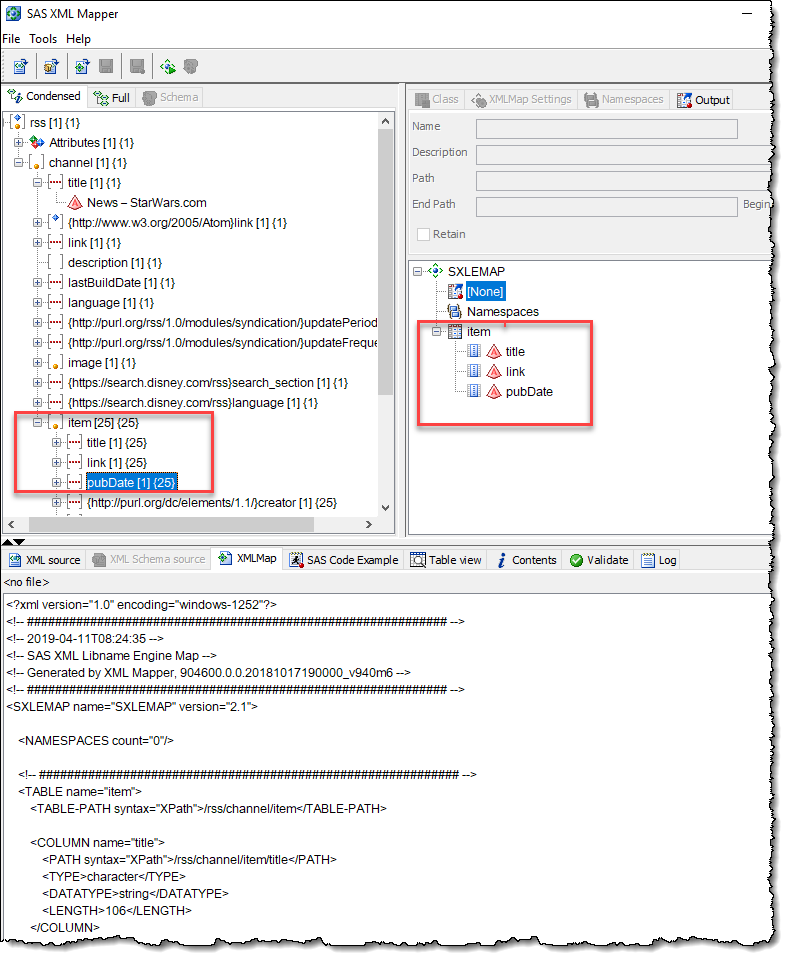
I found everything that I needed in "item" subset of the feed. I dragged that group over to the right pane to include in the map. That creates a data set container named "item." Then dragged just the title, link, and pubDate fields into that data set to include in the final result.
The SAS XML Mapper generates a SAS program that you can include to define the map, and that's what I've done with the following code. It uses DATA step to create the map file just as I need it.
filename rssmap temp; data _null_; infile datalines; file rssmap; input; put _infile_; datalines; <?xml version="1.0" encoding="windows-1252"?> <SXLEMAP name="RSSMAP" version="2.1"> <NAMESPACES count="0"/> <!-- ############################################################ --> <TABLE name="item"> <TABLE-PATH syntax="XPath">/rss/channel/item</TABLE-PATH> <COLUMN name="title"> <PATH syntax="XPath">/rss/channel/item/title</PATH> <TYPE>character</TYPE> <DATATYPE>string</DATATYPE> <LENGTH>250</LENGTH> </COLUMN> <COLUMN name="link"> <PATH syntax="XPath">/rss/channel/item/link</PATH> <TYPE>character</TYPE> <DATATYPE>string</DATATYPE> <LENGTH>200</LENGTH> </COLUMN> <COLUMN name="pubDate"> <PATH syntax="XPath">/rss/channel/item/pubDate</PATH> <TYPE>character</TYPE> <DATATYPE>string</DATATYPE> <LENGTH>40</LENGTH> </COLUMN> </TABLE> </SXLEMAP> ; run; |
Because WordPress feeds return just most recent 25 items by default, I need to use the "pageid=" directive to go deeper into the archive and return older items. I used a simple SAS macro loop to iterate through 5 pages (125 items) in this example. Note how I specified the XMLv2 libname with the XMLMAP= option to include my custom map. That ensures that SAS will read the XML and build the table as I've designed it.
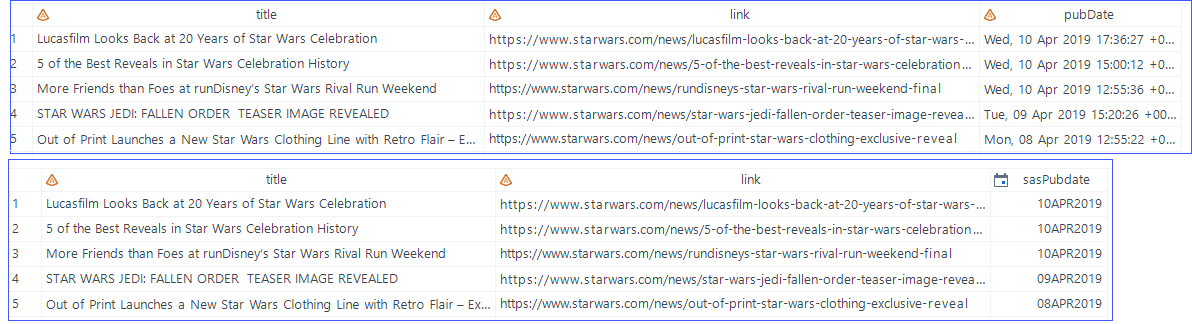
My final DATA step in this part is to recast the pubDate field (a text field by default) into a proper SAS date.
/* WordPress feeds return data in pages, 25 entries at a time */ /* So using a short macro to loop through past 5 pages, or 125 items */ %macro getItems; %do i = 1 %to 5; filename feed temp; proc http method="get" url="https://www.starwars.com/news/feed?paged=&i." out=feed; run; libname result XMLv2 xmlfileref=feed xmlmap=rssmap; data posts_&i.; set result.item; run; %end; %mend; %getItems; /* Assemble all pages of entries */ /* Cast the date field into a proper SAS date */ /* Have to strip out the default day name abbreviation */ /* "Wed, 10 Apr 2019 17:36:27 +0000" -> 10APR2019 */ data allPosts ; set posts_:; length sasPubdate 8; sasPubdate = input( substr(pubDate,4),anydtdtm.); format sasPubdate dtdate9.; drop pubDate; run; |
Reporting the results
After gathering the data I need from RSS feeds, I use SAS to match that with the WordPress data that I have about our blogs. I can then generate a table that I can easily submit in a DCMA form.
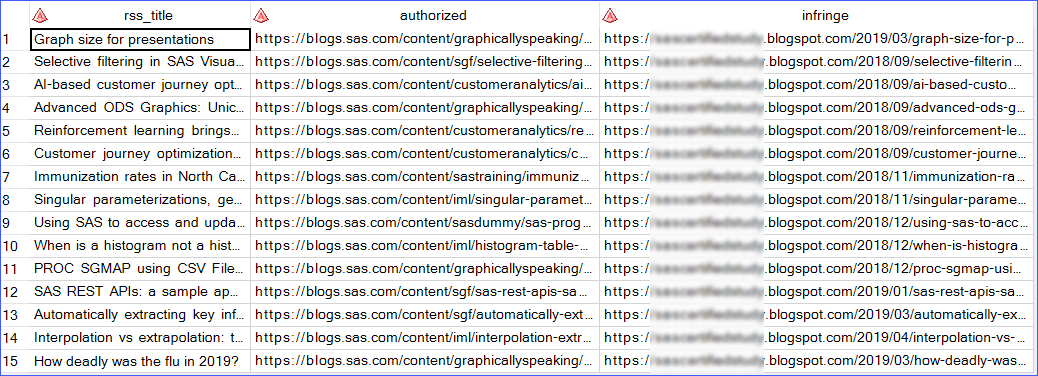
Usually, matching by "article title" is the easiest method. However, sometimes the infringing site will alter the titles a little bit or even make small adjustments to the body of the article. (This reminds me of my college days in computer science, when struggling students would resort to cheating by copying someone else's program, but change just the variable names. It's a weak effort.) With the data in SAS, I've used several other techniques to detect the "distance" of a potentially infringing post from the original work.
Maybe you want to see that code. But you can't expect me to reveal all of my secrets, can you?
* props to Robert "I dare you to knock it off" Conrad.

10 Comments
Great use of tools!
SAS programmers becoming detectives... Fab technique and for keeping some IP to yourself too - keep it secret, keep it safe! ;-)
pity it's such a despicable (plagarising) world, but good that it prompts such a useful article.
....
Would have thought the service allowing "pageid=" might also have something like "pagesize="
.... but that's retirement for you, I don't need to hunt for it anymore..
Thanks Peter. "Pagesize" is a common directive to request a certain number of records from an API, but I didn't find that on WordPress. Might have missed it it though.
Seems the parameter is termed
?per_page=
explained with caveat at
https://developer.wordpress.org/rest-api/using-the-rest-api/pagination/
Caveat :
Limit on ?per_page=100
Good sleuthing Peter! So much for not hunting for it, eh? Couldn't help yourself ;)
Chris,
Awesome article with good programming technical gems throughout!
It would be hilarious if in your next search you found this very article pirated without attribution on a web site.
--MMMMIIIIKKKKEEEE
Yes, hilarious! Maybe to some ;)
Pingback: Tips for reading XML files into SAS® software - SAS Users
thanks. used.