If you think that baby names and data analysis have nothing to do with one another, then you haven’t read Freakonomics. When my wife and I were expecting our third daughter, we had specific criteria in mind for her name. I used SAS Enterprise Guide and data from the Social Security Administration to select a list of candidate names.
I first wrote a blog entry about this process last June. Joining the trend of turning blogs-into-real-publications, I've written a paper for SAS Global Forum 2008 that fills in more of the details. In today's blog entry, I've included a high level summary plus a link to the SAS Enterprise Guide project that I created along the way.
Background: The Shame of Being Unoriginal
It started with my first two daughters, Marguerite (nickname: "Maggie") and Evelyn. We did not apply particular methodology when selecting their names, but our friends noticed something: each name was considered "old-fashioned" and not used much anymore. At least, that was a first impression. However, as the months went by, we noticed that other families that we met had small children with the same names we had picked. We had been part of a trend, completely by accident. In fact, according to the Social Security Administration, "Evelyn" ranks 98th in the top 1000 girls' names of 2002. I never saw that coming.
Analysis to the Rescue
When we were expecting our third daughter in 2005, I decided to devise a litmus test for our preferences. Knowing that we like "old-fashioned" names, but don't want to take part in a "name comeback" trend. In plain language, the question was: what are the names that were popular 80 to 100 years ago but aren't as popular now? Even fancy new web tools like the Baby Name Wizard don't answer that directly.
Here is what I did to find the answer:
1. Coalesced the top 1000 names from each of three decades: 1900-10, 1910-20, and 1920-30. Using SAS Enterprise Guide, I brought that data into SAS. It's about 3000 entries of course (1000 per decade), but really only about 1200 unique girl names.
2. Collected the top 1000 girl names from the most recent year available (2003 at the time), and brought that data into SAS.
3. Joined the two data sources to create a result set that contained only those girl names that appear in the "old names" list but not in the "new names" list. (In query parlance, this was a full outer join of the two tables based on "girl name", where "old girl name" is NULL in the "new girl name" list.)
Here is a snapshot of the process flow in the SAS Enterprise Guide project. It shows the two data sources joined in a query step.
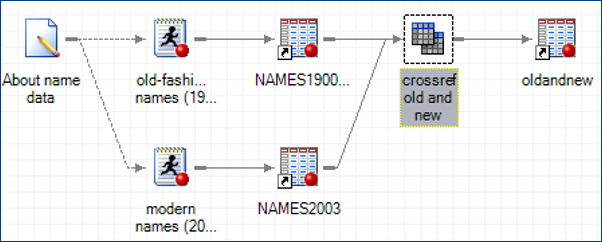
The result was over 900 names. The next step was clear: pick from one of these 900 names and we'd be original. If other kids started popping up with the same name, we would be the leader, not the follower.
More to Decisions than Analytics
I'll be honest -- there is a reason some of those old names aren't used much anymore (apologies to any "Hilda"s out there reading this). In the end, we settled on "Gwendolyn," a name that sounds old fashioned and yet still sweet to us. It turns out "Gwendolyn" still has some measure of popularity as a girl name -- it ranked 598th out of 1000 in the year 2003 (when 456 little girls were given that name, according to the Social Security numbers).
But at least we walked into that name fully informed. We haven't yet met very many other little Gwendolyns, so perhaps her name will still rank as one of her many outstanding, unique qualities.
Looking Back: How We Did
Taking the data available at the Social Security Administration's "baby names" site and bringing it into SAS Enterprise Guide, I was able to plot the popularity of the names we gave to our three children.
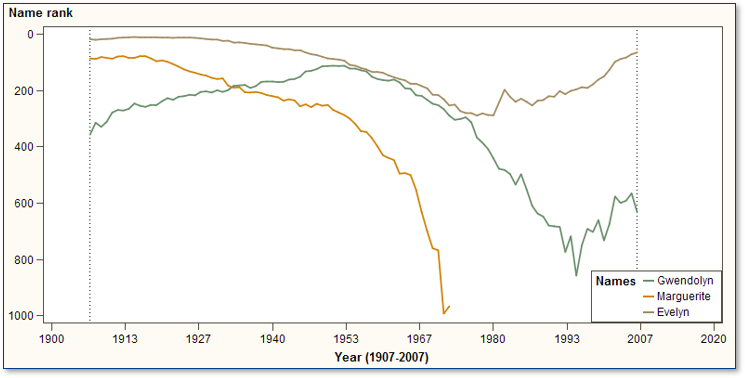
As you can see, we bucked the trend with Marguerite (named after my maternal grandmother). Her name (shown by the yellow line) drops out of the top 1000 list after 1972. But it appears that Evelyn (the brown line along the top) can expect to encounter many peers who share her first name. With Gwendolyn (the green line), we ended up somewhere in the middle. Note: The plot above shows ranking trends only, not frequency of use. We cannot draw conclusions about how often a name is used in relation to other names; we can infer its popularity based only on its placement in the top 1000 names.
Notes:
The full paper is available in the SAS Global Forum Proceedings.
The SAS Enterprise Guide project that accompanies the paper is available here. This is a ZIP archive that contains a project file named "Names41.egp", which is compatible with SAS Enterprise Guide 4.1 or later. It shows the data analysis step that produced a list of candidate names, plus a "how we did" step that produced the plot of name trends.

19 Comments
That amazing, we only go through web sites until we find the perfect baby name for us.
Neat visualization of that data. I've been building a map of popular baby names which includes the SSA dataset so I added a
Amazing amounts of data. Where did the 1910-1930 data come from? Was it just census data?
It all came from the Social Security Administration web site: http://www.ssa.gov.
Will you be willing to share the list of names you came up with based on your analysis? As someone interested in names, I stumbled across this post, and it's interesting, but I'd LOVE to see the actual list of names that are old-fashioned but not part of the old-fashioned trend.
Chris,
Throughout your journey for the quest to find the right baby name, did you come across any info on parents who regretted and wanted to change their baby's name. Baby is now 5 months old, and I can't get this out of my head that I want another name for him. (The name is Christopher by the way!) I was pressured into naming him another name that is very nice, but...
Anyway, friends and family have told me that I will certainly scar him for life if I call him something other than his given name?! I disagree... Wondering if you came across any notes re this.
Thanks,
Mommy Obsessed
I've replied to Kathleen with a text file of the old-fashion names. A sampling from the "A-list":
Afton
Agatha
Agnes
Agustina
Aida
Alba
Alberta
Albertha
Albertine
I'm no naming expert, nor am I an expert in what might "scar a child for life".
However, I did grow up with an interesting surname ("Hemedinger") that some might consider unfortunate -- and I think I came out of it okay.
Anecdotally, I can offer this: I've seen that a given name is often not a constraint on what you call your child. I know several people who refer to their children by names other than what appears on their birth certificate. I'm not just talking about diminutives that are rooted in the given name, either.
And as a child gets older, he/she might decide on a different preferred name anyway. In the long run as a parent, you don't really have that much say in it.
Chris
Wow Chris! You've put in a lot of effort in this one and the data you've shown are quite amazing. By the way, my grandmother's name was Agatha
Hello
Last week I was randomly googling for names and found a website where you coudl not only track one name over time but multiple names. I fogot to favourite it and now all i can find is the name voyager but that only allows you to track one name is not as good. Has ANYONE seen the site I am talking about? I am so annoyed with myself for not saving the address now!
Belinda
It's all very interesting to me, I also have a small list of possible baby names for my future child. Apparently baby names and data analysis can come together. After reading this article Freakonomics is a valuable option for me.
I am a huge fan of allthebabynames.com. It is a great site to help you choose a name for your new baby.
you can find a numerous of baby names in the below list... check it..
List of Baby Names
Pingback: Your million and one uses of SAS - The SAS Training Post
Pingback: Traffic report: the most visited posts of 2011 - The SAS Dummy
Ηеllο, I lοg on to your blogs on a гegular basіs.
Youг writing style iѕ witty, kееp it uρ!
Pingback: Building an SQL subquery in SAS Enterprise Guide - The SAS Dummy
Pingback: Confessions of a SAS Dummy - The SAS Dummy
Pingback: Copy McCopyface and the new naming revolution - The SAS Dummy