The customer journey is at the forefront of every discussion about modern marketing. The idea that customers move in premeditated or, at the very least, marketer-meditated paths between well-defined states is alluring (and comforting) to a marketing professional. Of course, even a cursory examination of a web path analytics (Sankey) diagram calls this notion into question, revealing the non-linear events that characterizes today’s omnichannel environment.
SAS Customer Intelligence already uses advanced analytics to make these visualizations simple (but not too simple) by identifying and visualizing the most important conversion paths in a meaningful way. This is discussed in more details in Suneel Grover’s three-part series beginning with algorithmic marketing attribution and conversion journey analysis .
It’s like using stepping stones to cross a river. The objective is to help customers get to the other side. The stepping stones represent touchpoints where you can lend a helping hand. There are short paths, there are long paths and there are dead-end paths. If the helping hand is too firm, then balance is lost, and the customer is gone. The question is: How can the marketer best guide the customer as they move between touchpoints on the journey towards their objective?
The challenge is that customers can choose many paths. Each customer arrives at a touchpoint with a unique history and you need to understand this to provide a nudge (marketing message) with the right strength and direction. This challenge is compounded by the permutations of paths in a journey. How is it possible to figure out the right message out of many given the context of the current interaction and history of the customer?
The rise of automated AI technologies is fortunate in that they offer a way to solve problems that require high-scale, automated and iterative experimentation to learn patterns in dynamic systems. Customer journey optimization is certainly a candidate business problem for these sorts of AI system. Let me explain how SAS has applied a particular AI technique (reinforcement learning) to answer this question by identifying optimal sequences of creatives on a web site to maximize conversion.
Optimizing customer journeys
Journeys come in all shapes and sizes. Literally. Navigating from a product image to checkout for a spontaneous purchase is a simple, two-step path. Multiple touchpoint interactions, including those of competitors, price comparisons and other research before making a major commitment (such as a mortgage) are far more complex and difficult to piece together. Some of these steps are invisible to a marketer (offline research, competitor influence, etc.) and even the signals that could be detectable can be hidden in extraneous noise.
Optimizing the customer journey usually means simplifying it, providing value to the organization (reducing cost or time to value) and to the customer (achieving their objective faster). Traditional wisdom is that you need to know what the journey looks like before you can optimize it. Prescription and discovery are the two main methods for determining journeys.
Using the prescription method, key stakeholders discuss specific customer objectives (purchase, information gathering, service etc.) and then try to view the process through the customer’s eyes and imagine the most likely sequences of touchpoints between the customer’s current state and success. While data is used to validate these marketer-created journeys, they do not start with data, so it’s a top-down approach.
The second method, bottom-up journeys, start with data – usually lots of it – and identifies common patterns from the vast number of touchpoint combinations. Therein lies the challenge. If the aim is to start with unconstrained journeys and discover something interesting, then the volume will overwhelm any attempts at rationalization.
Overcoming this challenge means finding an alternative to the traditional “discover the journey, visualize and then optimize it” approach. Schematically, a system that does this would look a bit like this:
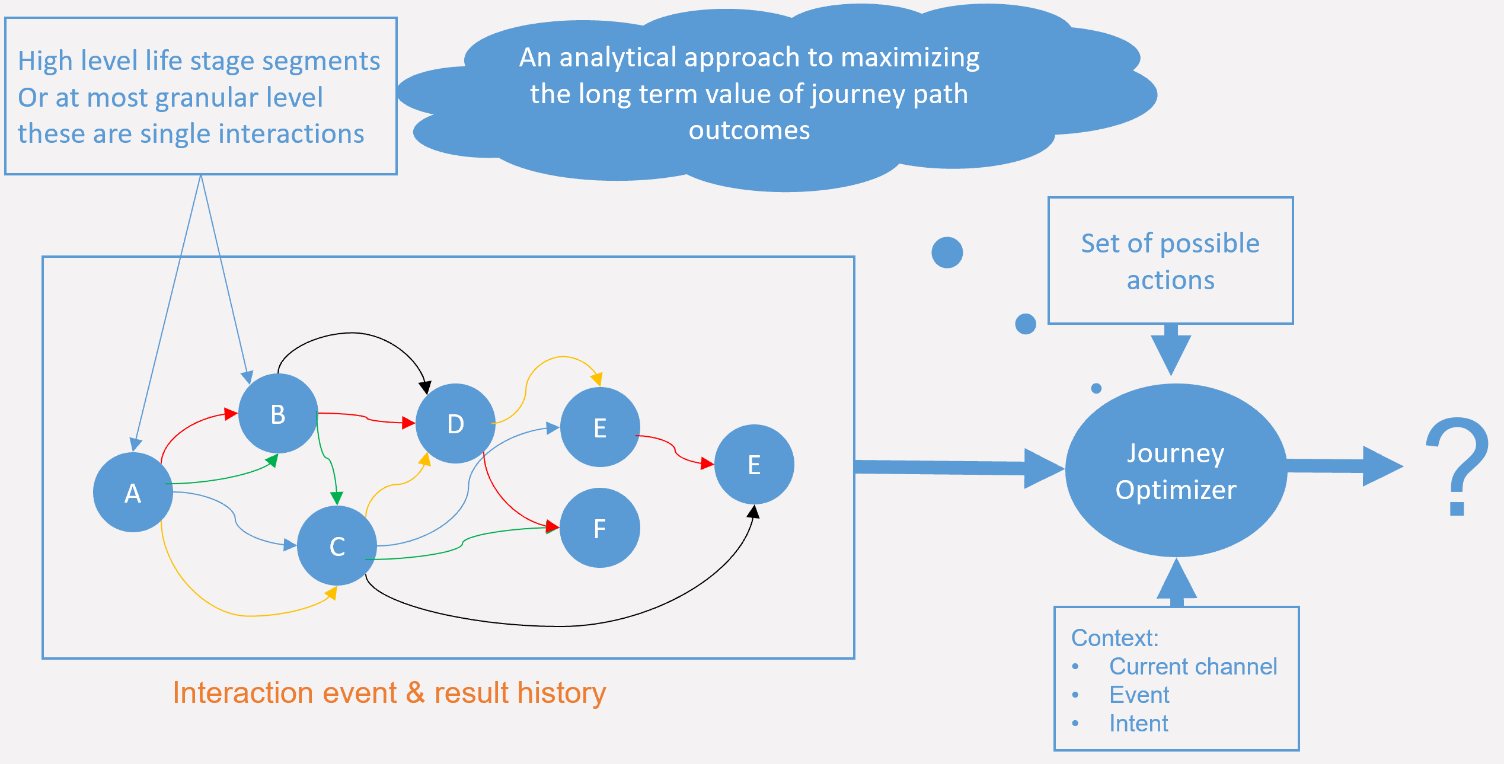
Each customer interaction is evaluated through the lens of that customer’s past interactions and how similar customers behaved in similar situations in the past. The “magic” is represented by the journey optimizer component. Its job is to learn, given the current context and history of a given customer, what action (marketing message) will lead to the best long-term goal.
In the past, this was where we would start to talk about predictive modeling and next best action. Such systems are good at determining an immediate best action based on instantaneous arbitration. Optimizing over sequences and longer-term objectives is more of a challenge, which is why we turned to AI-based systems for the solution.
Customer journeys and AI
AI is one of the most overloaded and hyped phrases in modern business technology parlance. It captures wider imagination for good, as well as bad, reasons. The fear or promise of machines taking over (or even superseding) humans is the stuff of science fiction nightmares. Fortunately, for now, there is little evidence of an outbreak of real (malevolent, or otherwise) machine intelligence. Rather, what AI promises us is the ability to automate well-defined tasks that require some degree of learning or learned response to dynamic environments.
The learning algorithms are the core of how AI works, though they are not AI in themselves. It is how the algorithms are applied to the problem being solved that marks a solution as AI. In many cases it comes down to an optimization problem – for a given environment and given a set of states, potential actions and a measurable objective, the question is: Which specific sequences of actions leads to meeting the objective?
One of the first and most famous examples is the application of a particular technique, reinforcement learning (RL) to the classic Atari game, Breakout (the illustration below is from a version featured on Google). Initially knowing nothing about the game, the RL system learned the rules and eventually developed a novel strategy for beating the game. The environment in this case is the game, the states are represented by frames (or screenshots) of the game and the actions are the eight possible actions of the player’s joystick. Each state and action combination has a state action value (the value derived from a change in state induced by the action). The aim of RL is to learn all the state action values.

The objective function in Breakout is the score. The way the algorithm works is to try many different actions and evaluate each one to determine if that leads to an increase or decrease in score (related back to the state action value). The algorithm behind this application of AI rewarded positive actions (which means they were more likely to be considered in the future) and penalize negative actions (which became less likely to be repeated). There is also a “discount factor” applied to future values. The discount factor can be tuned to reward shorter or longer-term gains.
While the system learned the rules, humans can’t easily learn from the system. There is no output in the form of a training manual or cheat list for a human player to read through. The system just does what it does, and we can observe. Of course, observation leads to interpretation and learning for the human player, but that is applying human intelligence.
Also, the initial learning phase (to figure out the most basic moves) took the RL system far longer than it would take a human. That is because a human comes into the game with a huge library of experiences to draw from and the ability to generalize and abstract. A human player, when seeing something on screen that looks like a bat and something else that looks like a ball, can almost instantly figure out that hitting the ball with the bat is part of the game.
Ultimately though, the AI surpassed human performance because of the relentless way in which it was able to try different combinations of actions and identify successful strategies through a combination of tireless pursuit and smart search techniques embedded in the algorithm.
An analogy between Breakout and customer journey optimization might seem far-fetched, but is germane to my next post. The journey optimization environment consists of a set of customers and potential marketing messages. The states of the game are individual customers (as describe by their attributes) at a given point. Marketing messages are the actions and the aim of the optimization is to learn the sequences of messages that lead to the highest long-term value across all customers.
Join me in Part 2 and discover how the analogy between a video game and customer journey optimization takes shape as we move into the exciting new world of AI-assisted marketing.
