 I’ve spent some time over the past couple of months learning more about anonymization.
I’ve spent some time over the past couple of months learning more about anonymization.
This began with an interest in the technical methods used to protect sensitive personally-identifiable information in a SAS data warehouse and analytics platform we delivered for a customer. But I learned that anonymization has two rather different meanings; one in the context of data management and another in the context of data governance for reporting, sharing or publishing information.
I think both sides of the topic are interesting enough that it’s worth writing about them – I hope you will find both of them interesting too, as overall, this is a subject about which anyone who handles sensitive or personal data should know something.
To data managers, anonymization often means the technical process of obscuring the values in sensitive fields in the data, by replacing them with equivalent, but non-sensitive values which are still useful for e.g. joining tables, representing individuals in time-series or transactional etc. In some SAS products, eg SAS Federation Server, this is called ‘masking’.
See the sample code below, in which the name field in the sashelp.class dataset is hashed, using the SHA256 hashing algorithm (new in SAS 9.4 M1? See the blog post, A fresh helping of hash: the SHA256 in SAS 9.4m1) which will return the same hashed name value whenever the same name value is is passed into it, for example on another row of the data in this table, or in another table.
data class_anon (drop=name salt_key); length name_hashed salt_key $128; set sashelp.class; * In real use, you should store the salt key somewhere else than a literal string in your code. Also, I had to break the hex value show here across multiple lines go get it to render properly in Wordpress - it should all be one long string with no whitespace or line breaks; salt_key = '9D91D63B23DB252EB9AD7EFE9A6E7120 8C139AEC1E721635E9EF8D39DF7D5AF5 5E707AD54E03631F130D3F87EA62AC8B 04209ED276317E12D17DE3CF9578D1B9'; name_hashed = %trim(put(sha256(cat(salt_key,strip(name))),hex128.)); run; |
Hashing (or masking) is different from encryption, in a couple of ways:
- Hashing is a one-way function. You cannot take a hashed value and ‘unhash’ it with an algorithm in the same way to produce the clear value.
- The length of the hashed value is fixed, and does not vary with the length of the input value. The input value can be longer, as well as shorter than the output hash value.
SAS Federation Server 4.1 now includes hash functions which can be used to anonymize data. The SAS Federation Server fact sheet illustrates this:
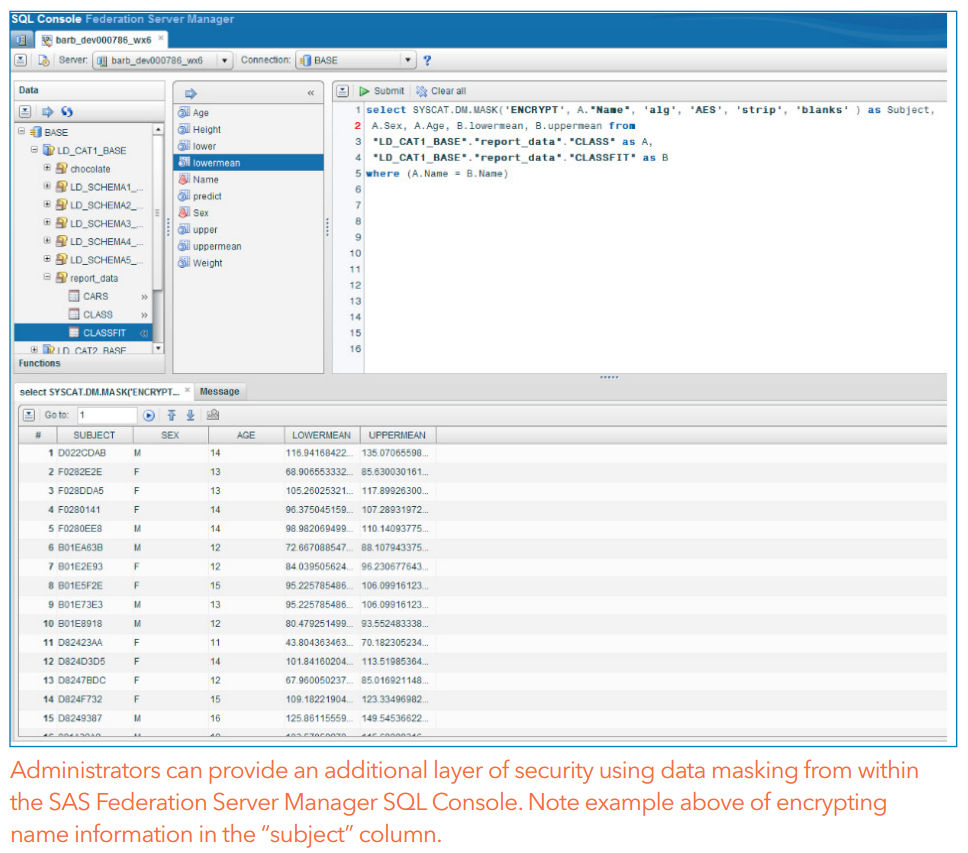
Where the data masking uses reversible encryption, you should make the masked data more difficult to attack (should someone externally obtain it), by storing the encryption key used to mask the data in a table with access controls that are tighter than the access control to see the SQL code behind the view. Far more people have a justifiable reason to see the code behind the view, than those who have a reason to see the encryption key which it uses when it runs. Better still, you should consider using a one-way hashing algorithm such as sha256, to create the hashed value, and maintain a lookup table somewhere secure inside your data warehouse, with the hashed values and their corresponding cleartext values. If you do this, then you should use a salt key.
About salt keys
A salt key value, which should be known only to you, should preferably be concatenated onto the clear value before it is hashed, to change the hashed values. This means that someone can only generate the same hashed value that you generated if they know the salt key too – which is why you must keep the salt key’s value secret. You should also change it regularly if you can, just as you would change a password regularly.
If you don’t add a salt key, a hacker who had gained access to the data could attack the hashed values by brute force, by providing a list of known first names, hashing each of those using the SHA256 function, and then comparing his list of hashed names against the hashed names in our data. There are a lot of people with very common first names, so without a salt key, the hacker would likely get a good hit rate in such an attack. He or she would eventually discover the ‘clear’ names of at least some rows in the anonymized dataset. But with the salt key, it doesn’t matter if the hacker knows the name of someone who is likely to be in our hashed dataset – they don’t know the salt key, so they can’t create hashed values which match ours, and can’t discover which rows of data are for people with names they already know.
Salt keys are important to defend lots of other types of hashed data against brute-force attacks, for example:
- phone numbers (it’s relatively easy to generate a list of all possible phone numbers and hash them),
- bank account numbers,
- credit card numbers (these may be 16-digits long, but an attacker can significantly reduce the number of values he needs to test if he knows who you bank with, or understands the ISO/IEC 7812 Bank Card Number format),
- ZIP code,
- social security number
- etc.
Using this technique, the fields which contain a subject’s real name, address, phone number and credit card number can each be substituted, in your main fact or dimension tables, with alternative fields, containing surrogate ID numbers or hash values, replacing the values in each of the ‘clear’ fields. So FIRST_NAME becomes FIRST_NAME_HASHED, PHONE_NUMBER becomes PHONE_NUMBER_HASHED etc. You still need to keep the clear values of each field in lookup tables in a special, more secure data store, accessible only to a very select group of logins, so that you can use them to contact the individual, or to interact with external systems, but your analysts and call center operators don’t need access to all the clear text values for sensitive data!
To round off this half of today’s article, I’ve included some more sample code below. It is based closely on code used at a real client to manage hashing of values in data read in to the ETL job flows. It is part of the job which reads data in from a source flat file. I’ve added a little to the beginning of the code, to provide a salt key and set up an _INPUT macro variable which is populated by DI Studio in the real code. I’ve also printed the saltkey value to the log so you can see it – that would be a very silly thing to do in real use, where you need to keep the salt key secret. Here’s the code:
* Create a dummy salt key table. Replace this in real use. Also, I had to break the hex value show here across multiple lines go get it to render properly in WordPress - it should all be one long string with no whitespace or line breaks; data salt_keys; format salt_value $128.; salt_value = '9d91d63b23db252eb9ad7efe9a6e7120 8c139aec1e721635e9ef8d39df7d5af5 5e707ad54e03631f130d3f87ea62ac8b 04209ed276317e12d17de3cf9578d1b9'; is_current = 1; output; run; %let _INPUT=salt_keys; * Get the current salt key from an input table. This is part of a feature of the application which allows the salt key to be changed every few months.; proc sql noprint; select SALT_VALUE into :salt_key from &_INPUT where IS_CURRENT = 1; quit; %let salt_key = %trim(&salt_key); %put &salt_key; * DO NOT DO THIS IN REAL CODE! The salt key should be kept secret!; /* The %hash macro below is used in data step code later to hash several columns in each incoming data file, where those columns contain sensitive data. It creates and formats the hashed column, and also caluculates the value for that column for each row of the input dataset. Usage: to create a column called PHONE_NUMBER_HASHED, you would just insert the line: %hash(PHONE_NUMBER); into a datastep which had a column called PHONE_NUMBER. */ %macro hash(column=); format &column._HASHED $64.; retain &column._HASHED; &column._HASHED=%trim(put(sha256(cat("&salt_key.",strip(&column.))),hex64.)); %mend; /* Usage example for the hash macro, hashing the 'name' column in the sashelp.class dataset. */ data class_anon; set sashelp.class; %hash(column=name); run; |
Look for my next blog on this topic - Anonymization for Analysts
Photo credit: Ben Sutherland (https://www.flickr.com/photos/bensutherland/)
Source: https://www.flickr.com/photos/bensutherland/205587168
License: Creative Commons Attribution 2.0 Generic (CC BY 2.0)

7 Comments
Hi;
Thanks for this useful post. Is there any method in SAS that we can drop unwanted names in a column that contains other information, so that we keep those information that we want and we drop only unwanted names?
Hi Behrouz,
Thanks for your comment. I'm not personally an expert in SAS Data Quality tools, so I'll ask a colleague to reply too, but your requirement sounds like one which would be well met by one of those tools. If I understand correctly, you are looking for something which can determine whether the each value in a column is a name or not, with a good degree of accuracy, and use the outcome of its row-by-row decision to either set a value in a new column that you can act on in a subsequent step, or to simply blank out the value (or drop the row) if the value is a name. You may be able to write some data step or proc sql code which implements one or two rules of your own to decide if the column contains a name or not, and for simple data, that might work fine. For example, if all the values are either names or phone numbers, and there are no other possibilities, then it is trivially easy to do yourself without any other tools. But if the column can contain values which are strings, and may contain one or two spaces or commas (or whatever other characters your name values can include), then it's harder, because a string may roughly resemble a name without being a name. In that case you would need something which recognises names in strings, based on knowing what likely names exist in your language and country. I think data cleansing step using a SAS Data Quality tool, and a Quality Knowledge Base (QKB) intended for the language and country that the data represents would likely be easier to implement and would work better.
Kind regards,
David
In this datastep:
data class_anon (drop=name salt_key);
length name_hashed salt_key $128;
set sashelp.class;
* In real use, you should store the salt key somewhere else than a
literal string in your code. Also, I had to break the hex value show
here across multiple lines go get it to render properly in WordPress -
it should all be one long string with no whitespace or line breaks;
salt_key = '9D91D63B23DB252EB9AD7EFE9A6E7120
8C139AEC1E721635E9EF8D39DF7D5AF5
5E707AD54E03631F130D3F87EA62AC8B
04209ED276317E12D17DE3CF9578D1B9';
name_hashed = %trim(put(sha256(cat(salt_key,strip(name))),hex128.));
run;
Why do you use %trim()?
If you want to trim, you should use trim(), not %trim()
To see what I mean, try to run this datastep and see that %trim() does not work as you expect, but trim() does:
data test;
a="xx ";
b=%trim(a)!!"x";
c=trim(a)!!"x";
run;
Pingback: Anonymization for analysts | SAS Users
Nice article for sure the hashing principle as it should not be able to be reverted.
Please adjust that with the pwencode hash function. Those hashed strings can be reverted. As external providers do not accept the SAS hash, SAS reverts that before sending that. There is no other explanation for that. It leaves you in the situation that when a pwencode string may be seen that related account could be compromised. It is more weird as the pwencoded strings can be copies and used tot get access without the need of knowing the real password.
Just another example you cannot trust "I have hashed, so no problem" claims.
Thanks for posting this interesting article. One very important consideration regarding anonymization and/or de-identification is that masking, or hashing, or encrypting the personally identifiable information (PII) is not generally accepted as sufficient within the biopharmaceutical industries in terms of preventing a downstream data consumer from gaining access to a participant's actual identity.
There are a variety of reasons for this, but, in general, de-identification and anonymization involve applying different rules to different types of data in order to reduce the risk of re-identification. This can include, for example, changing all date values while preserving the relative timings between patient data activities, selectively redacting sensitive information and more comprehensive and complex approaches.
The approach described in the original article is an important step in the process, but the reader should not walk away from the article with the expectation that a participant's privacy is sufficiently protected. The more comprehensive approach is described at http://www.d-wise.com/blur and may also be described in the author's proposed next article - "Anonymization for Analysts". I look forward to reading it.
Dave
Good points there Dave! I'd certainly agree that it's not enough protection for sensitive data to only hashing the personally-identifiable or otherwise sensitive information. You would also want to take care to store the data 'at rest' in a well-protected database or filesystem, with good access control, and to transmit data 'in motion' over either an encrypted network connection (e.g. SFTP, HTTPS/SSL/TLS) or transfer it over a VPN connection. I've seen architectures where someone used both SSL/TLS and a VPN to transfer data, which is perhaps overkill. And it's always worth asking yourself why you need to store the data at all - the safest way to make sure you are never at fault for inadequately protecting someone's credit card number or sensitive medical history is to not hold it in the first place. Only store it if you absolutely have to.
I hadn't come across d-wise's products before (having not worked in the biopharmaceutical or life sciences industries). Very interesting - thank you for sharing that link!
David