To demonstrate the power of text mining and the insights it can uncover, I used SAS Text Mining technologies to extract the underlying key topics of the children's classic Alice in Wonderland. I want to show you what Alice in Wonderland can tell us about both human intelligence and artificial intelligence (AI). As you'll see, one of the world’s best-known children’s books might not be a book just for children.
Information retrieval
First, let’s define information extraction. Information extraction is about getting semantic information, sense and meaning, out of documents. And the goal is twofold:
- Organize information so that it is useful to people.
- Put information in a semantically precise form that allows further inferences to be made by machine learning algorithms.
In our case, the documents are the different chapters and paragraphs of Alice in Wonderland. Practically, we convert the qualitative and flat text information into a matrix representation. We calculate the frequency of each of the relevant terms in each chapter, and that gives us a term by document matrix. We can then use this table:
- As a basis for a hierarchical network representation of the information in this book.
- As a basis to calculate how frequently terms occur together per chapter, per paragraph.
Concept associations and hierarchies
Think of the way human memory works. We detect things and events that often occur together and these things get associated in our mind. This is exactly what we want to achieve with text mining. We want a method for automatically determining the associations between concepts in texts based on the co-occurrence of words and topics.
This approach is based primarily on a bag-of-words method, where the basic assumption is that we can extract meaningful information out of a text by counting words and topics in this text and by understanding how these words are syntactically (structurally) related to each other in regard to the laws of grammar.
Concepts associations are measured as the conditional reading chance. Two concepts are linked if they occur together frequently enough in the different chapters and paragraphs of Alice in Wonderland. In other words, our “concept link” visualization includes associations if the confidence of those association rules is high-enough.

The text mining process
Figure 1 below gives us an example of a text mining process workflow combining both descriptive and predictive tasks.
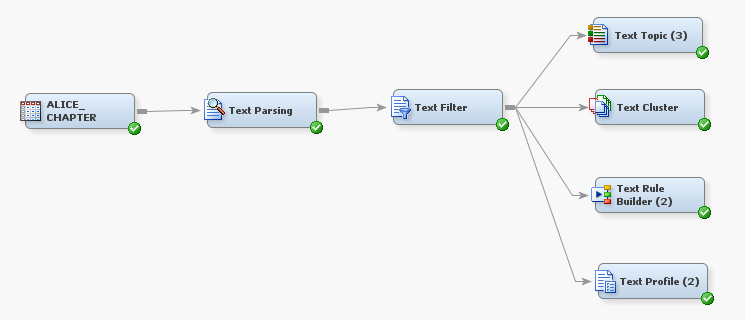
First, we start by parsing Alice in Wonderland in order to quantify information about the terms that are contained therein. In fact, we apply natural language processing and parse these big blocks of text into individual tokens.
We typically group together variants of each word underneath its parent term. We group together synonyms and we also detect parts of speech. Here we choose to ignore all terms that are not nouns, verbs or adjectives (e.g. prepositions, adverbs …).
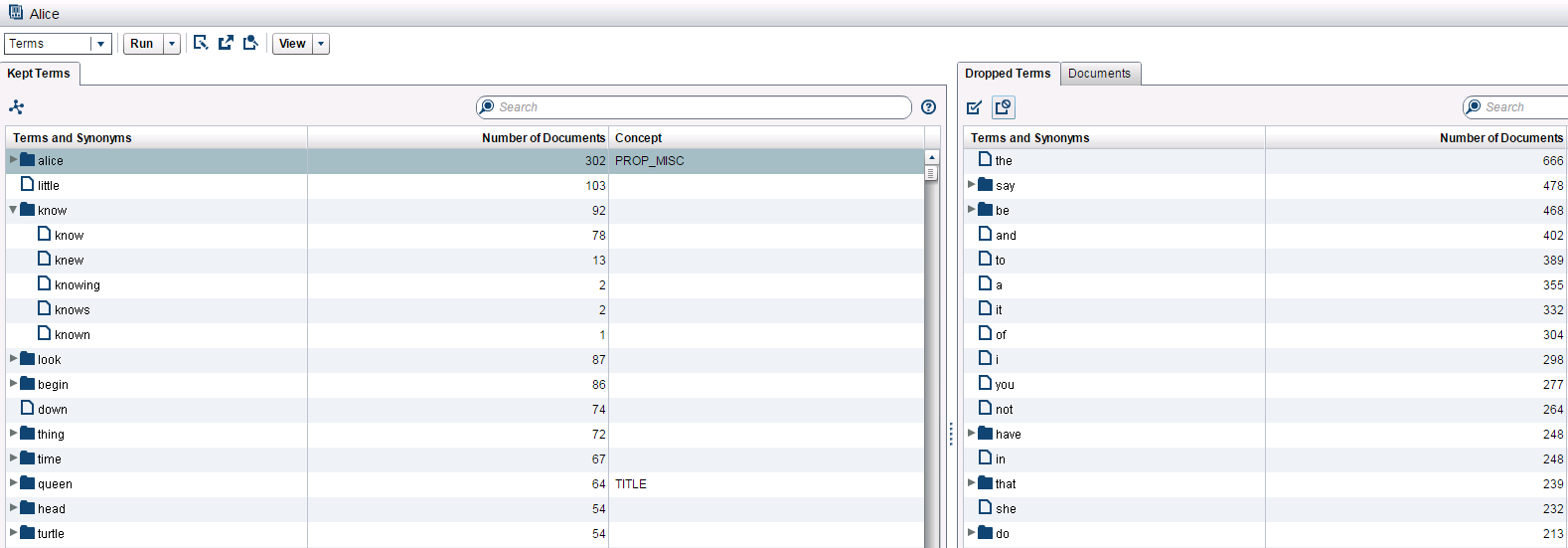
For example, if I expand the term “know” (see Figure 2 below), I can see that different forms of the word are included under the parent term and are treated as synonyms for the purposes of topic analysis. The frequency counts to the right quickly show me which surface forms are being mentioned more or less often.
Of course, we can see that many terms may not be applicable or meaningful. So, we need to filter these terms to further reduce the total number of parsed terms or documents that are analyzed. To do so we use the text filter node, and we use weightings properties to allow us to vary the importance of terms based on corrected or weighted frequencies.
On the one hand, we’re interested in removing terms with very high frequencies like ‘to be’ or ‘to say.’ Terms that don’t carry any relevant meaning and are, in fact, noise for our analysis. In our example, we use the inverse document frequency method. This method gives greater weight to terms that occur infrequently in the document collection. Using frequencies only do not give enough weight to the more meaningful terms.
We can also interactively drop and un-drop terms in the environment illustrated on the above screenshot from SAS Contextual Analysis. The resulting reduced data set can be orders of magnitude smaller than the one that represents the original collection.
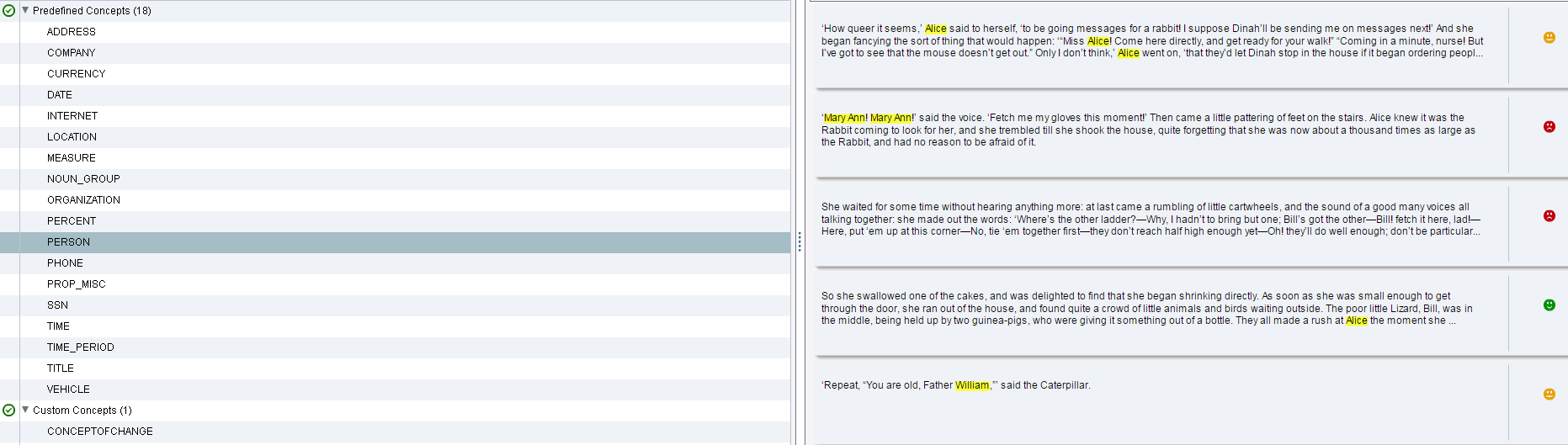
We also extract entities such as persons, places, addresses, dates. The following screenshot in Figure 3 below shows how characters are automatically detected in the book and how we automatically associate a first sentiment to each of the scenes where they appear. Sentiment might become negative when Alice is afraid for example.
Alice and human intelligence: Classification
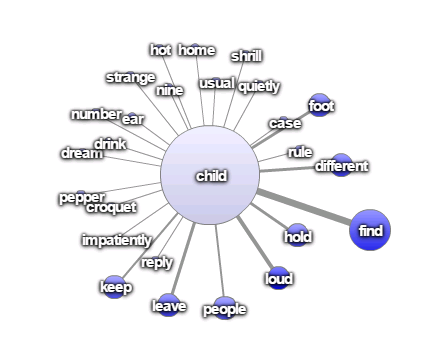
So, we link and visualize concepts by filtering the statistically relevant associations between them. We start with first-level relationships or direct associations: Notice how ‘child’ and ‘find’ are strongly associated in the following term map in Figure 4 below:
But we’re also interested in the ‘friends of friends’ of our concepts or multilevel relationships. See below how Alice is associated with ‘large’ & ‘grow’ & ‘drink’ & ‘eat’ & ‘bottle’ in the concepts-linking graph in Figure 5 below.
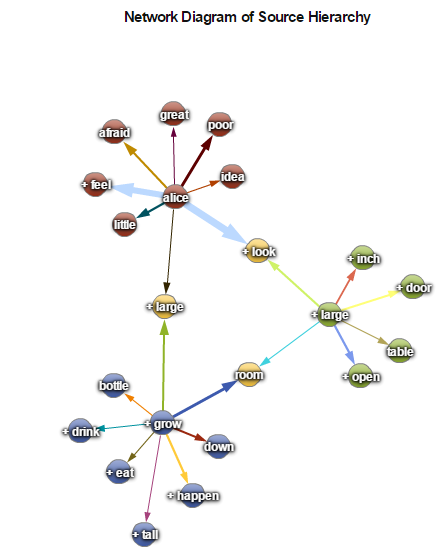
We uncover that Alice is in fact trying to figure out how things work in Wonderland. Even in this fantasy world, there is a certain way of how things work, so she generates solutions, trials, and she tests them.
Alice, as a child, is obsessed with rules; she wants to find the rules of wonderland, she's always asking: "what are the rules?"; "how does this work?"; "what's happening?"; "how do I change size?"; "how do I interact?"; "how does this tea party work?"; "what are the rules of the court?"
So, by every exposure to the different aspects of this world, she's learning how things work and how they work differently from the everyday world. What’s seemingly nonsense, isn’t; Wonderland just doesn't work the way our world does, and Alice must develop some common sense about it.
Our associative networks of concepts give us a simplified representation of the “inner language” that Alice is building -- not the language with which she communicates, but the language with which she thinks. This inner language is closely related to the language with which we, humans, communicate but is somehow its pre-requisite. We first needed this representation of our world to be able to exchange information and concepts.
Transition
In a complex world, those libraries of associations grow exponentially the more we interact with the world. And if they help us to form mental pictures and expect associations, we need to manage them efficiently. We need mechanisms to efficiently navigate within such large maps of the reality, and we need the ability to query those maps.
Working from the top down, we can generate and test our own multidimensional concepts. We want to build some intelligence on top of our low-level associations. Because we know that the trouble with modeling the world in our heads with such low-level associations, is that thinking about everything there is in the world, including every single parameter, is just too much. Alice has the same issue.
So, the way we humans think is mostly articulated on the idea that:
"change leads to change”
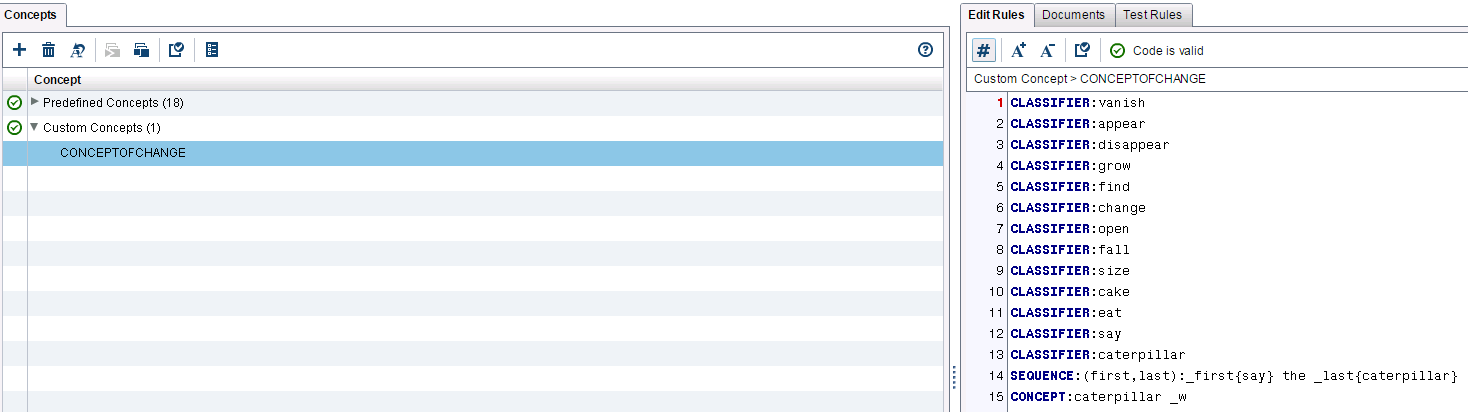
That's why we generate a custom concept with SAS Contextual Analysis with a heavy emphasis on this notion of transition: What action leads to what consequences. This vocabulary includes notions such as: decrease, increase, change, appear, and disappear.
In Wonderland and in the real world, we constantly speak in those terms. Each one is heavily connected with vision, and with the way Alice and ourselves experience the world. The screenshot in Figure 6 below shows this custom concepts panel that acts as a code editing interface, with the concept taxonomy on the left, and a place to enter in and validate rules on the right. We have those multi-dimensional filters available to better capture the rules of change in Wonderland.
Text clustering and text topics
Another way to enrich our knowledge about the hidden associations and the peculiar reality of Wonderland is to use a bottom-up approach. There as well, we want to discover higher-level topics or clusters that are collections of terms that describe and characterize a main theme or idea. And we are now able to categorize terms into different categories and to see how different/distant the different clusters are from each other.
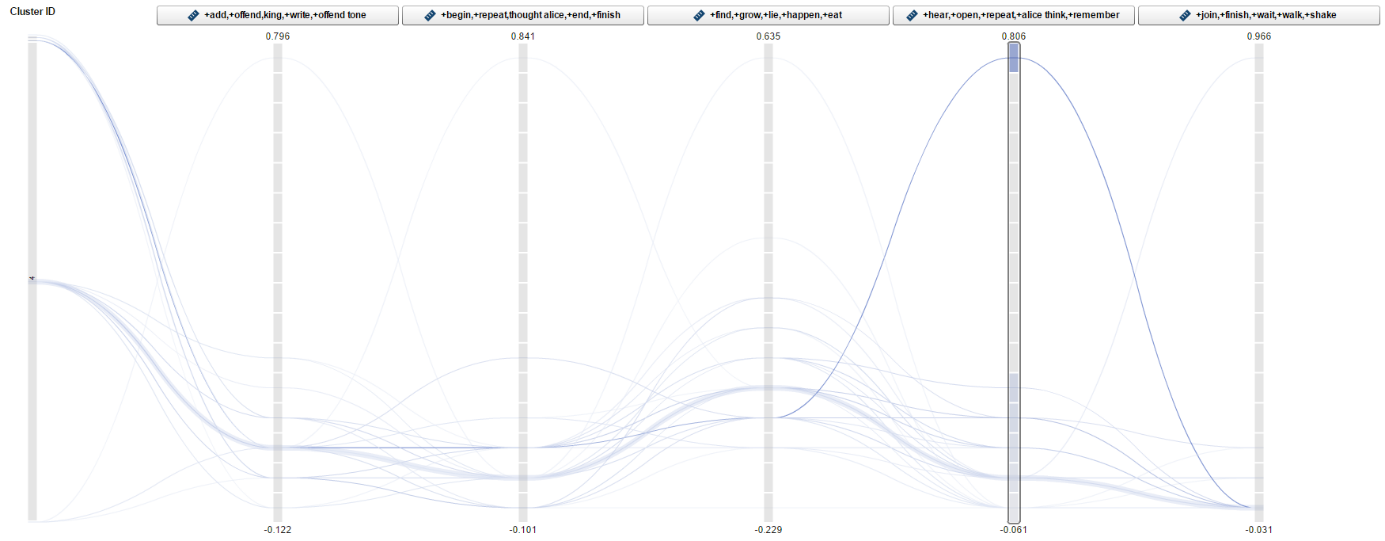
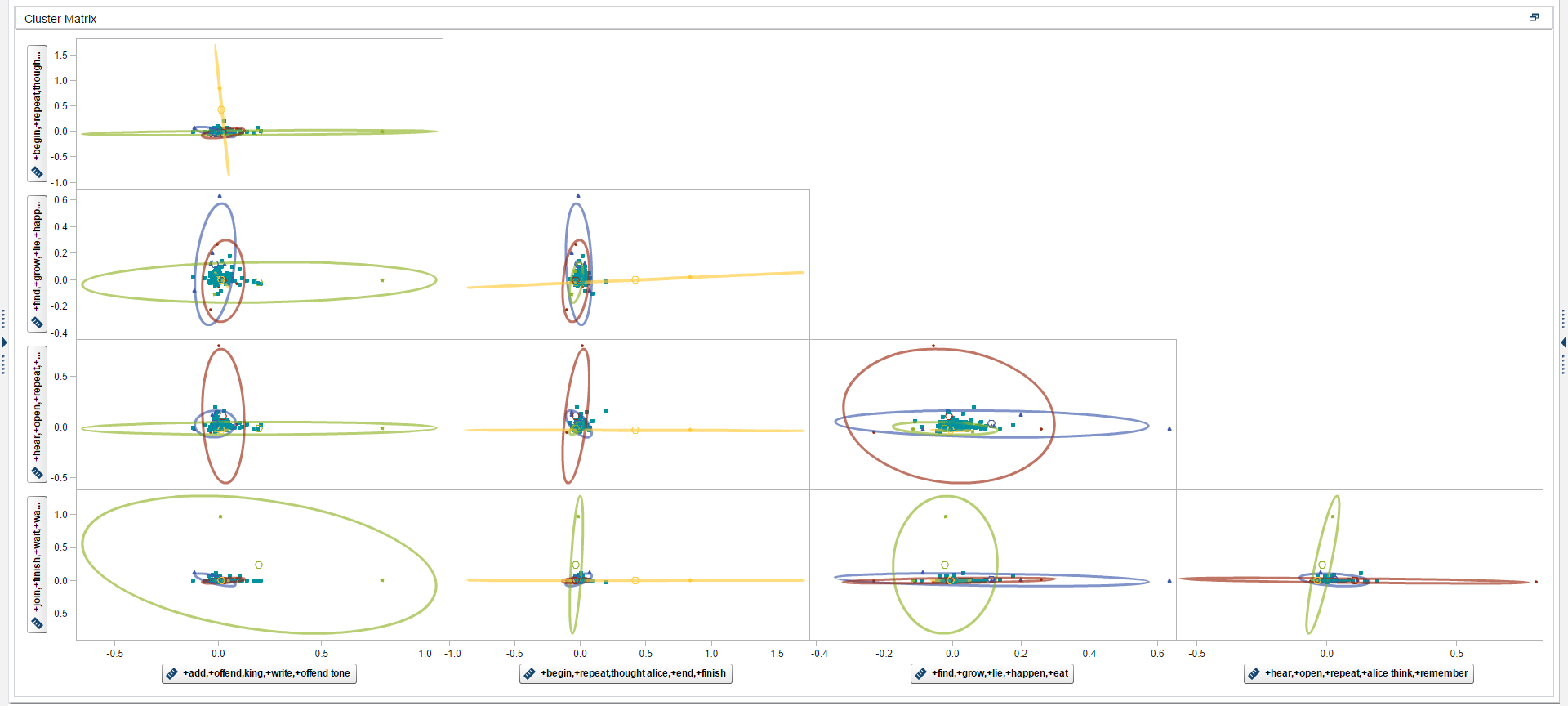
With the text cluster node, we cluster the chapter of Alice in Wonderland into disjoint sets of documents and reports on the descriptive terms for those clusters. We use a hierarchical clustering algorithm that groups clusters into a tree hierarchy. It relies on the singular value decomposition (SVD) to transform the original weighted, term-document frequency matrix into a dense but low dimensional representation.
A text cluster works much like a cluster analysis in multivariate statistics. See some of the results in Figures 7 and 8 below:
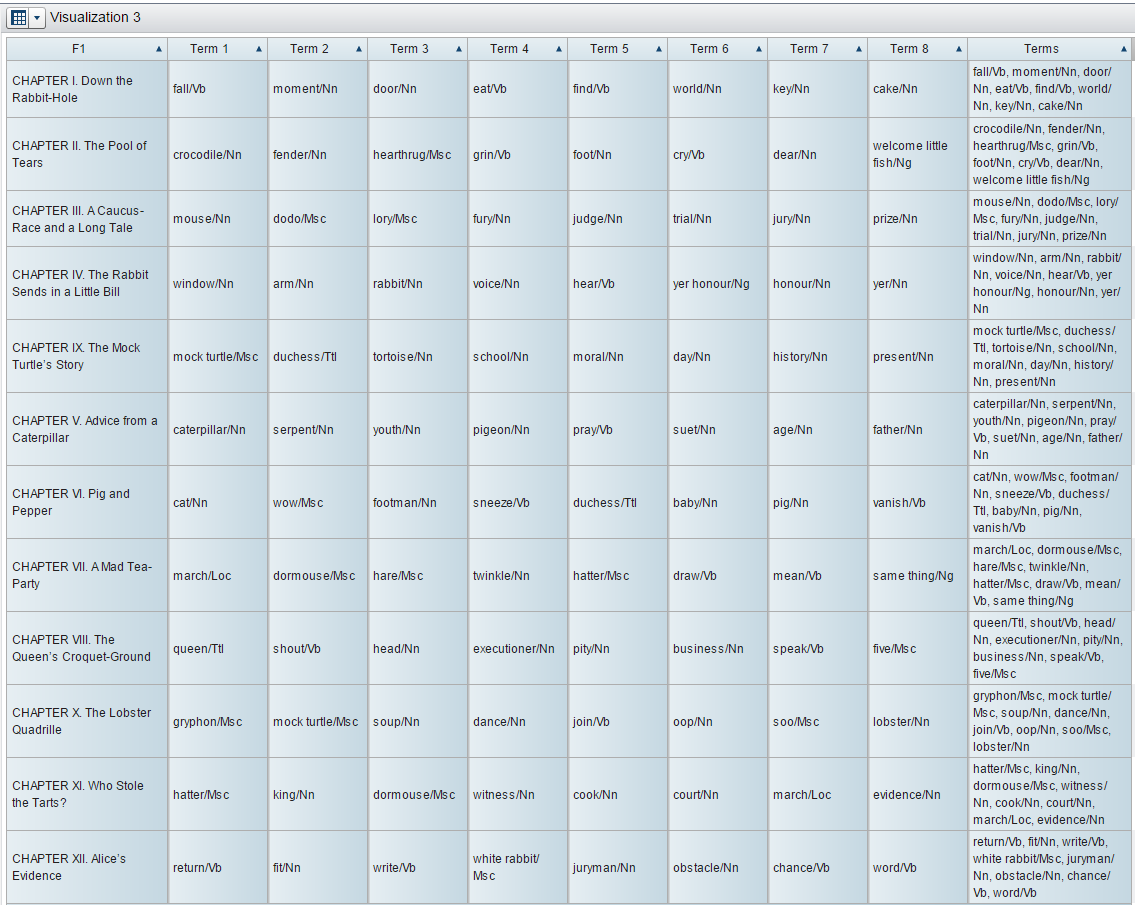
In addition, we can also build a predictive model. We can, for example, profile a target variable that would represent each chapter of the book using terms found in the documents. For each level of this target variable, or each chapter, the node outputs a list of terms from the collection that characterizes or describes that chapter (see Figure 9 below).
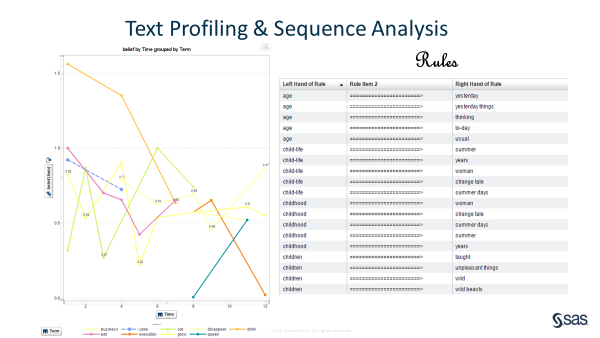
We can also use the chapters as a time variable, to see how to predict which terms are the most likely to describe a chapter and see how this (Bayesian) belief evolves with time through the different chapters. See the left part of Figure 10 below. We can also run some association analysis, much like market basket analysis, to build some new communities of associated words and discover new rules, new associations in Wonderland.
Generate and test strategy
Now this book of course is often seen as a children's work. However, Lewis Carroll’s Alice in Wonderland was actually published a few years after Darwin’s Origin of Species, and many people have argued that this work has been influenced by Darwinian thinking and his natural selection theory.
Think of the way Alice built intelligence. Think of the way evolution built intelligence. Both use a generate and test strategy. What it tells us is that intelligence is an epiphenomenon of the process of being in the world. Intelligence is not to be literally programmed in, it emerges from interactions. Intelligence emerges from the interaction of organs, senses, and behaviors. It emerges from the interaction between individuals that learn from each other.
In the same way as Alice generates solutions and tests them in Wonderland, evolution, with each new generation, tests new solutions. Evolution generates and tests new species and new individuals. Some fail, some succeed. This learning process can happen slowly, like with the evolution of most of the species where learning happens via small adaptive shifts through thousands of generations.
Humans learn exponentially fast because we have this ability to grow those semantics networks with new concepts we invent. So, we have those associative networks that we can learn bottom-up and that we are also able to enrich top-down. We can generate and test our own concepts.
Every time you try to write a piece of software, you will likely need artificial intelligence to make your computer software smart. And every time you try to write a piece of software used by humans in an interactive way and that makes humans smarter, you’ll need text analytics.
That is really co-artificial intelligence, helping humans in their daily life, with tons of applications. Think of AI crawling the web and understanding the web, and assisting you in answering your questions. Or think of AI understanding the words you just typed in, or the question you just asked, in any language. Or AI finding the best possible answer based on an always more powerful representation of the human knowledge accumulated on the web, thanks to better text analytics.
And to learn from textual data exponentially fast with text mining, you best combine the bottom-up and the top-down learning approach that we humans are so good at. These are, respectively, the statistical approach and the linguistic approach within text analytics.
SAS excels in both and combines them in solutions like SAS Contextual Analysis. Learn more by reading this paper from SAS Global Forum 2017: Exploring the Art and Science of SAS Text Analytics.
