"Our corporate data is growing at a rate of 27% each year and we expect that to increase. It’s just getting too expensive to extend and maintain our data warehouse.”
“Don’t talk to us about our ‘big’ data. We’re having enough trouble getting our ‘small’ data processed and analyzed in a timely manner. First things first.”
“We have to keep our data for 7 years for compliance reasons, but we’d love to store and analyze decades of data - without breaking the machine and the bank.”
Do any of these scenarios ring a bell? If so, Hadoop may be able to help. In this 5-part blog series, Big Data Cheat Sheet on Hadoop, we’re taking a look at five big data questions from the perspective of a marketer. This post answers the second question in the series to help marketers understand how these big data technologies are impacting (or can impact) the customer experience, and what you can do to take advantage of this data playground.
Question 2: Why do we need Hadoop if we’re not doing big data?
Contrary to popular belief, Hadoop is not just for big data. (For purposes of this discussion, big data simply refers to data that doesn't fit comfortably – or at all – into your existing relational systems.) Granted, Hadoop was originally developed to address the big data needs of web/media companies, but today, it's being used around the world to address a wider set of data needs, big and small, by practically every industry.
In my white paper, The Non-Geek’s Big Data Playbook: Hadoop and the Enterprise Data Warehouse, I propose six common Hadoop use cases—three of which don’t require “big” data at all to take full advantage of Hadoop:
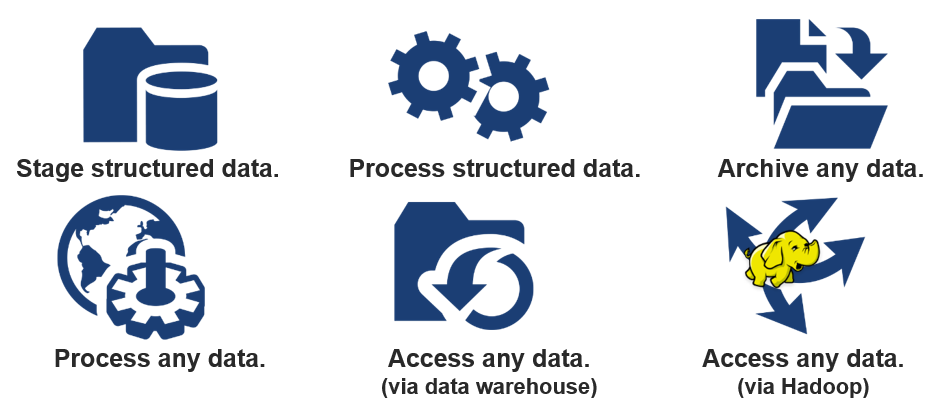
Here’s a brief summary of each use case:
- Stage structured data. Use Hadoop as a data staging platform for your data warehouse.
What if you used Hadoop to process and transform your operational data before loading it into your data warehouse? The bonus is that because of the low cost of Hadoop storage, you could store both versions of the data in Hadoop: the raw, native data and the transformed data. Your data would now all be in one place, making it easier to manage, re-process, and analyze at a later date.
- Process structured data. Use Hadoop to update data in your data warehouse and/or operational systems.
Instead of using costly data warehouse resources to update data in the warehouse, why not send the necessary data to Hadoop, let Hadoop do its thing, and then send the updated data back to the warehouse? This use case not only applies to processing your warehouse data, but also data in any of your operational or analytical systems. Take advantage of Hadoop’s low-cost processing power so that your relational systems are freed up to do what they do best.
- Archive all data. Use Hadoop to archive all your data on-premises or in the cloud.
Since Hadoop runs on commodity hardware that scales easily and quickly, organizations can now store and archive a lot more data at a much lower cost. For example, what if you didn’t have to destroy data after its regulatory life to save on storage costs? What if you could easily and cost-effectively keep all your data? Or maybe it’s not just about keeping the data on-hand, but rather, being able to analyze more data. Why limit your analysis to the last three, five or seven years when you can easily store and analyze decades of data? Isn't this a data geek’s paradise?
- Process any data. Use Hadoop to take advantage of data that’s currently unavailable in your enterprise data warehouse ecosystem.
This use case focuses on two categories of data: (1) structured data sources that have not been integrated into your data warehouse and (2) unstructured and semi-unstructured data sources. More generally, it’s any data that’s currently not part of your warehouse ecosystem that could be providing additional insight into your customers, products and services. Because Hadoop can store and process any data, it can pick up the slack for data that your data warehouse cannot or doesn’t handle well.
- Access any data (via data warehouse). Use Hadoop to extend your data warehouse and keep it at the center of your organization’s data universe.
This use case is geared towards companies that want to keep the enterprise data warehouse as the de facto system of record—at least for now. As a complementary component, Hadoop can be used to process and integrate any type of data—structured, semi-structured, and unstructured—and load what is needed into the data warehouse. This allows companies to continue using their current BI/analytics tools with their enterprise data warehouse ecosystem.
- Access any data (via Hadoop). Use Hadoop as the landing platform for all data and exploit the strengths of both the data warehouse and Hadoop.
As mentioned earlier, one advantage of capturing data in Hadoop is that it can be stored in its raw, native state. It does not need to be formatted upfront as with traditional, structured data; it can be formatted at the time of the data request. This use case most closely supports the concept of using Hadoop as a “data lake”—which is a discussion/debate I had recently with a colleague in another forum.
Key takeaways for marketers
Don’t make the mistake of believing that Hadoop is synonymous with big data—because it’s not. It is, however, one of the more popular big data technologies out there that you can use even if you don’t have big data—as pointed out in the first three use cases above. But it’s not just about the technology - this is about enabling you to understand technology enough to understand how it relates to your focus on the customer experience.
Hadoop is here to stay and it’s ready to “play” with your enterprise data warehouse. Download my Non-Geek’s Big Data Playbook to help you figure out which use cases make sense for your organization. This playbook was written for the technologically-savvy business professional who prefers pictures to words, simplicity to complexity, and briefer explanations to longer ones. If this describes you, then what are you waiting for?
This is the 2nd post in a 5-part series, "Big Data Cheat Sheet on Hadoop." This spin-off series for marketers was inspired by a popular big data presentation I delivered to executives and senior management at a recent SAS Global Forum Executive Conference.
Editor’s note:
If you did not read the first post in this series, I encourage you to read that one as well. Tamara's goal with this series is to enable you to have an informed view of how this area of technology can support your strategy. Armed with these perspectives, hopefully you can partner even more closely with I.T. and operations to deliver the best possible customer experience.
Once you're comfortable with Hadoop and want to delve deeper into analytically-driven marketing solutions, start with our Customer Intelligence home page at: www.sas.com/customerjourney. And as always, thank you for following!

2 Comments
Pingback: Marketers ask: Is Hadoop enterprise-ready? - Customer Analytics
Pingback: Marketers Ask: Isn’t a Data Lake Just the Data Warehouse Revisited? | The Cyberista Says