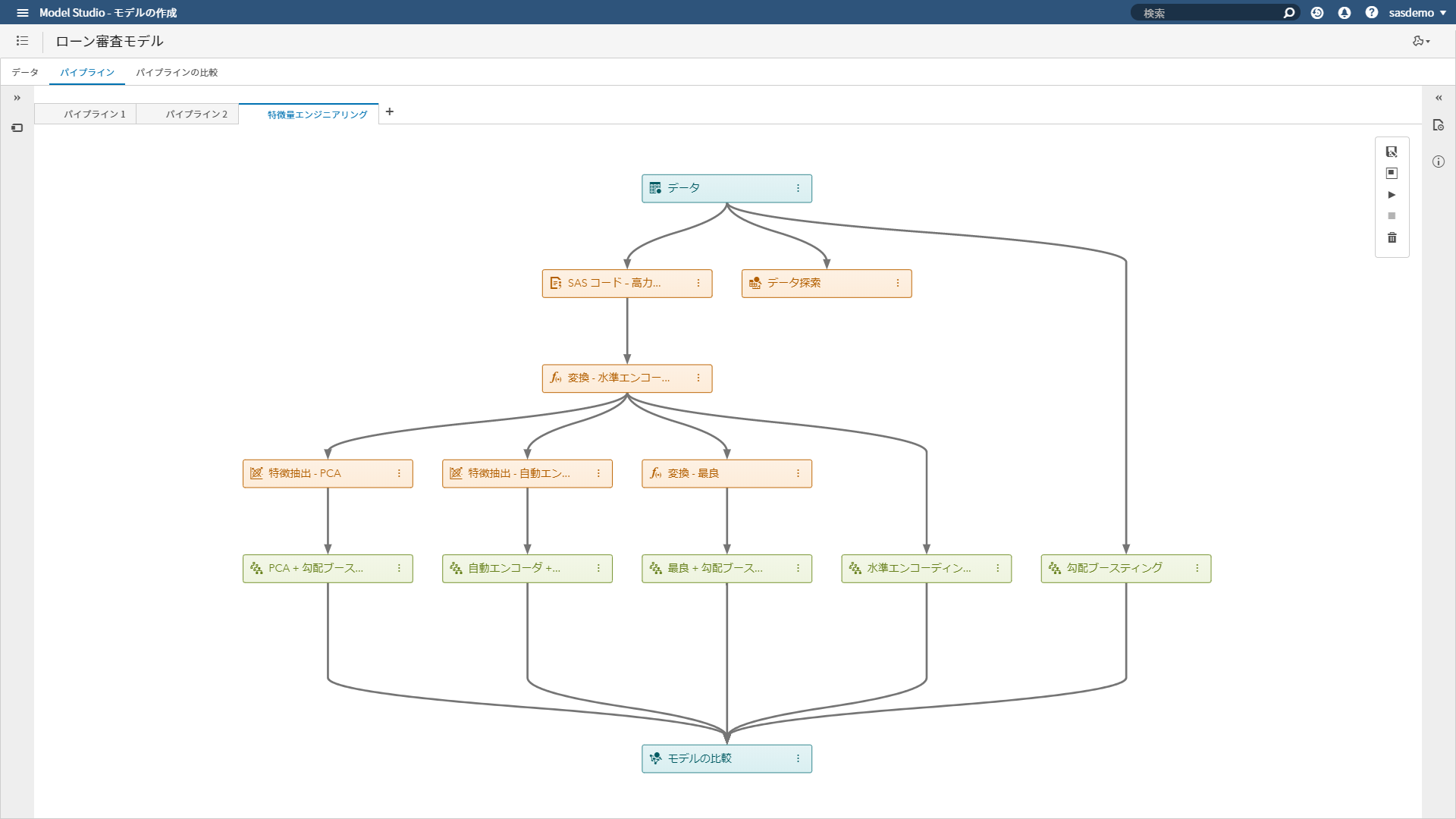

ビジュアルパイプラインで予測モデル生成(テンプレート使用編)では、SAS ViyaのModel Studioを使用し、標準で実装されているパイプラインのテンプレートを使用して、予測モデルを自動生成する手順を紹介しました。 今回は、標準実装のテンプレートに含まれている、「自動特徴量エンジニアリングテンプレート」を紹介します。 「特徴」=入力=変数(独立変数、説明変数)であり、 特徴量エンジニアリングとは、予測モデルの精度を高めるために、学習用の生データに基づき、特徴を変換したり、抽出したり、選択したり、新たな特徴を作り出す行為です。 以下は、特徴量エンジニアリングの例です。 ・郵便番号などの高カーディナリティ名義変数のエンコーディング(数値化) ・間隔尺度の変数の正規化、ビニング、ログ変換 ・欠損パターンに基づく変換 ・オートエンコーダー、主成分分析(PCA)、t-SNE、特異値分解(SVD)などの次元削減 ・季節的な傾向を把握するために、日付変数を別々の変数に分解して曜日と月と年の新しい変数を作成 より良い「特徴」を作り出し、選択することで、予測モデルの精度が向上するだけでなく、モデルを単純化し、モデル解釈可能性を高めるのにも役立ちます。 しかし、従来、予測モデリングのプロセスにおいて、データサイエンティストは、その多くの時間を特徴量エンジニアリングに費やしてきました。しかも、特徴量エンジニアリングの良し悪しは、データサイエンティストのスキルに大きく依存してしまいます。 こうした課題に対処するために、SAS Viyaでは、自動特徴量エンジニアリングテンプレートを提供しています。このテンプレートを使用することで、特別なスキルを必要とせず、特徴量エンジニアリングにかける時間を短縮し、より精度の高い予測モデル生成が可能になります。 以下が、SAS ViyaのModel Studioに実装されている「自動特徴量エンジニアリングテンプレート」です。 このテンプレートは、大きく3つのステップで構成されています。 高カーディナリティ変数に対するエンコーディング(数値化) 最良変換、PCA / SVD、オートエンコーダーを使用して新たな特徴を作成 特徴エンジニアリング未/済みデータに基づく予測モデルの精度比較 ステップ1.高カーディナリティ変数に対するエンコーディング(数値化) このステップの最初のノードは、「SASコード高カーディナリティ」という名のSASコードノードです。 SASコードノードを使用することで、SASプログラムをパイプラインに組み込むことができます。 このノードを選択し、右側画面内でコードエディタ:「開く」をクリックすると、その内容を確認できます。 このSASコードノードでは、最初に、20〜1,000レベルのカーディナリティの高い変数(固有値が多すぎる名義変数)を識別します。minlevelsとmaxlevelsの値を更新することで、この範囲を簡単に変更することもできます。次に、数値変換(TRANSFORM = LEVELENCODE)を指定し、これらの変数に対してのみレベル(水準)エンコーディングを行います。実際に変換を行うためには、「データマイニングの前処理」にある「変換」ノードを実行する必要があるため、「変換」ノードが接続されています。 レベルエンコーディングでは、名義を数値に変換します。これは、カーディナリティの高い変数を扱う場合に特に便利です。これらの変数は、ほとんどの機械学習アルゴリズムにおいてコンピューティングリソースの負荷をあげてしまうことが多いからです。最初に名義変数のレベルをアルファベット順に並べ替え、各レベルに昇順に数字(1から始まる)を割り当てます。 ステップ2.最良変換、PCA / SVD、オートエンコーダーを使用して新たな特徴を作成 ステップ2では、以下の3つの異なる自動特徴量エンジニアリング手法が適用されます。 変換-最良(Best):このノードは、「データマイニングの前処理」にある「変換」ノードを使用して、すべての間隔変数に対して「最良(Best)」の変換を行います。この方法では、各間隔変数に対して、ランク付け基準(ターゲットとの相関など)に基づいて、単一変数の変換(逆変換、標準化、センタリング、ログ変換など)を比較し、最も高いランク付けを持つ変換を選択します。 特徴抽出- PCA:このノードは、「データマイニングの前処理」にある「特徴抽出」ノードを使用して、間隔入力変数に対する自動特徴抽出手法として「自動」を指定しています。「自動」では、間隔入力変数の総数が500以下の場合は、主成分分析(PCA)が適用され、それ以外の場合は、特異値分解(SVD)が適用されます。 特徴抽出-自動エンコーダ:このノードでは、オートエンコーダを用いて特徴抽出を行います。この手法では、特徴抽出にすべての入力変数(間隔と名義)を使用します。オートエンコーダーは、入力データを再構成するために使用できる特徴のセットを学習することを目的とした教師なし学習技術です。手短に言えば、ニューラルネットワークは、ターゲット(出力)ニューロンを入力ニューロンと等しく設定することによって訓練されるものです。 このノードでは、中間隠れ層が10に設定されているので、10個の新しい特徴が作成されます。 ステップ3.特徴エンジニアリング未/済みデータに基づく予測モデルの精度比較 最後のステップでは、勾配ブースティングを用いた5つの異なる予測モデルが生成されます。 ・高カーディナリティー変数のレベルエンコーディング+特徴抽出(PCA)を施したデータに基づくモデル ・高カーディナリティー変数のレベルエンコーディング+特徴抽出(オートエンコーダー)を施したデータに基づくモデル ・高カーディナリティー変数のレベルエンコーディング+変換-最良を施したデータに基づくモデル ・高カーディナリティー変数のレベルエンコーディングを施したデータに基づくモデル ・元のデータ(特徴量エンジアリングを施していない)に基づくモデル 5つのモデルを生成後、パフォーマンスを比較します。勾配ブースティングは、非常に効果的な教師あり学習アルゴリズムであり、予測精度の面で他のアルゴリズムより優れていることが多いため、使用しています。