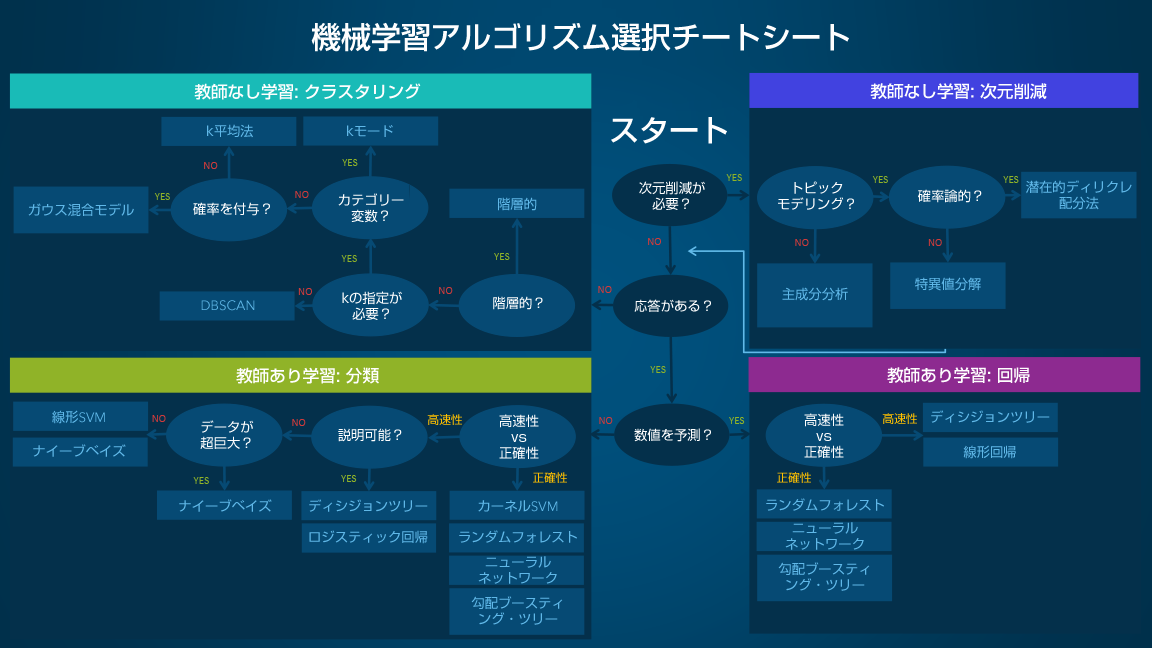

この記事はSAS Institute Japanが翻訳および編集したもので、もともとはHui Liによって執筆されました。元記事はこちらです(英語)。 この記事では、関心対象の課題に適した機械学習アルゴリズムを特定・適用する方法を知りたいと考えている初級~中級レベルのデータ・サイエンティストや分析担当者を主な対象者としたガイド資料を紹介し、関連の基本知識をまとめます。 幅広い機械学習アルゴリズムに直面した初心者が問いかける典型的な疑問は、「どのアルゴリズムを使えばよいのか?」です。この疑問への答えは、以下を含む数多くの要因に左右されます。 データの規模、品質、性質 利用できる計算時間 タスクの緊急性 データの利用目的(そのデータで何をしたいのか?) 経験豊富なデータ・サイエンティストでも、どのアルゴリズムが最も優れたパフォーマンスを示すかは、複数の異なるアルゴリズムを試してみなければ判断できません。本稿の目的は、特定の状況にのみ有効なアプローチを紹介することではなく、「最初に試すべきアルゴリズム」を何らかの明確な要因にもとづいて判断する方法についてガイダンスを示すことです。 機械学習アルゴリズム選択チートシート この機械学習アルゴリズム選択チートシートは、幅広い機械学習アルゴリズムの中から特定の課題に最適なアルゴリズムを見つけ出すために役立ちます。以下では、このシートの使い方と主要な基礎知識をひと通り説明します。 なお、このチートシートは初心者レベルのデータ・サイエンティストや分析担当者を対象としているため、推奨されるアルゴリズムの妥当性に関する議論は省いてあります。 このシートで推奨されているアルゴリズムは、複数のデータ・サイエンティストと機械学習の専門家・開発者から得られたフィードバックやヒントを取りまとめた結果です。推奨アルゴリズムについて合意に至っていない事項もいくつか残っており、そうした事項については、共通認識に光を当てながら相違点のすり合わせを図っているところです。 利用可能な手法をより包括的に網羅できるように、手元のライブラリが拡充され次第、新たなアルゴリズムを追加していく予定です。 チートシートの使い方 このシートは一般的なフローチャートであり、パス(楕円形)とアルゴリズム(長方形)が配置されています。各パスでYES/NO、または高速性/正確性を選びながら最終的に到達したものが推奨アルゴリズムとなります。いくつか例を挙げましょう。 次元削減を実行したいものの、トピック・モデリングを行う必要がない場合は、主成分分析を使うことになります。 次元削減が不要で、応答があり、数値を予測する場合で、高速性を重視するときには、デシジョン・ツリー(決定木)または線形回帰を使います。 次元削減が不要で、応答がない場合で、階層構造の結果が必要なときには、階層的クラスタリングを使います。 場合によっては、複数の分岐に当てはまることもあれば、どの分岐にも完璧には当てはまらないこともあるでしょう。なお、利用上の重要な注意点として、このシートは、あくまでも基本的な推奨アルゴリズムに到達できることを意図しているため、推奨されたアルゴリズムが必ずしも最適なアルゴリズムでない場合もあります。多くのデータ・サイエンティストが、「最適なアルゴリズムを見つける最も確実な方法は、候補のアルゴリズムを全て試してみることだ」と指摘しています。 機械学習アルゴリズムのタイプ このセクションでは、機械学習の最も一般的なタイプを取り上げ、概要を示します。これらのカテゴリーについて十分な知識があり、具体的なアルゴリズムの話題に進みたい場合は、このセクションを飛ばし、2つ先のセクション「各種アルゴリズムの概要と用途」に進んでいただいてかまいません。 教師あり学習 教師あり学習アルゴリズムは、実例のセット(入力データと出力結果)を基に予測を行います。例えば、過去の販売データを用いて将来の価格を推定することができます。教師あり学習では、ラベル付きのトレーニング用データからなる入力変数と、それに対応する望ましい出力変数があります。アルゴリズムはトレーニング用データを分析し、入力を出力にマッピングする関数を学習します。この関数は、トレーニング用データにおける入力/出力の関係を一般化することによって推定されます。この関数に新しい未知の入力データを与えると、それに対応する出力が算出され、その出力が未知の状況における結果の予測値となります。 分類:データを用いてカテゴリー変数を予測する場合、教師あり学習は「分類」と呼ばれます。これは例えば、画像にラベルや標識(例:犬または猫)を割り当てるようなケースです。ラベルが2つしかない場合は「2値(バイナリ)分類」、3つ以上のラベルがある場合は「マルチクラス分類」と呼ばれます。 回帰:連続値を予測する場合、その教師あり学習は「回帰問題」となります。 予測:過去と現在のデータを基に将来を予測するプロセスであり、最も一般的な用途は傾向分析です。具体例として一般的なのは、当年度および過去数年の販売実績を基に次年度の販売額を推定することです。 半教師あり学習 教師あり学習を行う上での課題は、ラベル付きデータの準備に多大な費用と時間がかかりかねないことです。ラベル付きデータが限られている場合には、ラベルなしの実例データを用いて教師あり学習を強化することができます。これを行う場合は、機械にとって完全な「教師あり」ではなくなるため、「半教師あり」と呼ばれます。半教師あり学習では、ラベルなしの実例データと少量のラベル付きデータを使用することで、学習精度の向上を図ります。 教師なし学習 教師なし学習を実行する場合、機械にはラベルなしのデータのみが与えられます。学習の目的は、クラスタリング構造、低次元の多様体、スパース(疎)ツリーおよびグラフなど、データの基底をなす固有パターンを発見することです。 クラスタリング:あるグループ(=クラスター)内の実例データ群が、その他のグループ内の実例データ群との間と比べ、(所定の基準に関して)高い類似性を示すような形で、実例データセットをグループ化します。この手法は、データセット全体を複数のグループにセグメント化する目的でよく使われます。グラスタリングの実行後に各グループ内で分析を実行すると、固有パターンを容易に発見できることが多々あります。 次元削減:検討の対象とする変数の数を減らします。多くの用途では、生データに極めて多次元の特徴が含まれており、一部の特徴は目的のタスクに対して冗長または無関係です。次元削減は、データに潜む真の関係性を発見するために役立ちます。 強化学習 強化学習は、環境からのフィードバックを基に「エージェント」(課題解決の主体者。例:ゲームのプレイヤー)の行動を分析および最適化します。機械は、取るべきアクションの選択肢を事前に教えられるのではなく、どのようなアクションが最大の報酬(例:ゲームのスコア)を生み出すかを発見するために、さまざまなシナリオを試行します。他の手法には見られない強化学習ならではの特徴は「試行錯誤」と「遅延報酬」です。 アルゴリズム選択時の考慮事項 アルゴリズムを選択する際は、正確性、トレーニング時間、使いやすさという3つの側面を常に考慮する必要があります。多くのユーザーは正確性を第一に考えますが、初心者は自分が最もよく知っているアルゴリズムに意識が向きがちです。 データセットが与えられたとき最初に考える必要があるのは、どのような結果になるにせよ、何らかの結果を得る方法です。初心者は、導入しやすく結果が素早く得られるアルゴリズムを選ぶ傾向がありますが、分析プロセスの最初の段階ではそれで問題ありません。まずは、何らかの結果を得て、データの概要を把握することを優先します。その後、データに対する理解を深め、結果をさらに改善することを目指し、より高度なアルゴリズムを試すことに時間を費やせばよいのです。 ただしこの段階でも、最高の正確性を示した手法が必ずしもその課題に最適なアルゴリズムであるとは限りません。通常、アルゴリズムから本来の最高パフォーマンスを引き出すためには、慎重なチューニングと広範囲のトレーニングが必要になるからです。 各種アルゴリズムの概要と用途 個別のアルゴリズムについて知識を深めることは、得られる結果と使い方を理解するために役立ちます。以下では、チートシートに掲載されている中でも最も基本的なアルゴリズムの詳細と、それらを使用すべき状況に関するヒントをまとめます。 線形回帰とロジスティック回帰 線形回帰は、連続従属変数 (y) と1つ以上の予測変数 (X) との関係をモデリングするためのアプローチです。この場合、(y) と