 When I teach my Data Cleaning course, the last topic I cover in the two-day course is SAS Integrity Constraints. I find that most of the students, who are usually quite advanced programmers, have never heard of Integrity Constraints (abbreviated ICs). I decided a short discussion on this topic would be useful.
When I teach my Data Cleaning course, the last topic I cover in the two-day course is SAS Integrity Constraints. I find that most of the students, who are usually quite advanced programmers, have never heard of Integrity Constraints (abbreviated ICs). I decided a short discussion on this topic would be useful.
Integrity Constraints are rules about your data, such as values for gender must be 'F' or 'M' or that values for heart rate must be between 40 and 100. You can create these ICs using PROC DATASETS. The ICs are stored as part of the data descriptor along with the other information you see when you run PROC CONTENTS. Once you have created these constraints and you try to add new data to an error free data set, the constraints will prevent any data that violates the constraints from being added to your existing data set. Let's look at an example:
Suppose you have a data set called Health with variables Subj, Gender, and Heart_Rate. You can run the program below to create this data set:
data Health; length Subj $ 3 Gender $ 1; input Subj Gender Heart_Rate; datalines; 001 M 68 002 F 72 003 M 78 ; |
Here is a listing:
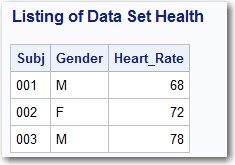
Suppose you want to create the following IC rules:
- Subj is unique and non-missing
- Gender must be 'F' or 'M'
- Heart_Rate must be between 40 and 100
You can use PROC DATASETS to create ICs that follow these rules, as follows:
proc datasets; modify Health; ic create Subj_Chk = primary key(Subj); ic create Gender_Chk = check (where=(Gender in ('F','M'))); ic create HR_Chk = check (where=(Heart_Rate ge 40 and Heart_Rate le 100)); quit; |
Each of the constraints you create are given a name (conforming to the same naming rules as SAS variables). A primary key constraints requires that values for this variable be unique and non-missing. The other two constraints in this example are called Check constraints and you simply write a WHERE clause to define your rule.
Here is a portion of the SAS Log when you run this procedure:
Member File # Name Type Size Last Modified 1 HEALTH DATA 131072 05/13/2017 15:29:46 57 modify Health; 58 ic create Subj_Chk = primary key(Subj); NOTE: Integrity constraint Subj_Chk defined. 59 ic create Gender_Chk = check (where=(Gender in ('F','M'))); NOTE: Integrity constraint Gender_Chk defined. 60 ic create HR_Chk = check (where=(Heart_Rate ge 40 and Heart_Rate 60 ! le 100)); NOTE: Integrity constraint HR_Chk defined. 61 quit; |
Let's try to add some data that violates one or more of these constraints:
data New; length Subj $ 3 Gender $ 1; input Subj Gender Heart_Rate; *Note: data errors are shown in red; datalines; 004 x 55 001 M 80 005 F 110 006 M 66 ; proc append base=Health data=New; run; |
Let's look at part of the log:
NOTE: Appending WORK.NEW to WORK.HEALTH. WARNING: Add/Update failed for data set WORK.HEALTH because data value(s) do not comply with integrity constraint Subj_Chk, 1 observations rejected. WARNING: Add/Update failed for data set WORK.HEALTH because data value(s) do not comply with integrity constraint HR_Chk, 1 observations rejected. WARNING: Add/Update failed for data set WORK.HEALTH because data value(s) do not comply with integrity constraint Gender_Chk, 1 observations rejected. NOTE: There were 4 observations read from the data set WORK.NEW. NOTE: 1 observations added. NOTE: The data set WORK.HEALTH has 4 observations and 3 variables. |
Looking at this log, you see that one observation with Subj = '001' was not added because Subj must be unique and non-missing; One observation had a value of Heart_Rate outside the valid range; One observation had an invalid value for Gender.
This was a very simplified example of Integrity Constraints—the actual use of these constraints can be a bit more complicated. You will also want to create an Audit Trail data set that shows which observations were added, which observations were not added, and the reason for the failure to add an observation.
Please check the SAS documentation or (even better, at least for me), buy a copy of my new book, Cody's Data Cleaning Techniques Using SAS, 3rd edition, that covers this topic.






2 Comments
Hi Ron,
I have your second edition Learning SAS By Example: A Programmer's Guide.
I want to move on to your Data Cleaning book, your Biostatistics book, and your SAS Statistics book. Are there limits in what I can do with ONLY SAS UNIVERSITY EDITION when learning from these books?
Thanks,
Hi Marilyn.
There are NO limits placed on the SAS University Edition (such as number of variables or observations). You can run any program in my books using SAS UE. The ONLY change you may need to make is to place your data files in a folder called C:\SASUniversityEdition\Myfolders on your hard drive. That way you can access the data and programs from your virtual machine. I recommend VirtualBox (as does SAS). You can read data from anywhere on your hard drive if you set up shared folders. SAS has excellent documentation for how to do this but I would avoid it unless you have a lot of data sets in different places that you need to process. I discuss shared folders in my Biostatistics book. Please email me at ron.cody@gmail.com if you have other questions, or post to the blog.