A popular DATA step programming technique frequently used by SAS users is the ability to identify the beginning and ending observation in by-groups. The way it works is whenever a BY statement is specified with a SET statement, two temporary variables are created in the Program Data Vector (PDV), FIRST.variable and LAST.variable, for each variable specified in a BY statement. These temporary variables contain a value of either 0 or 1, as shown below:
- variable = 0 indicates an observation is not the first observation in a BY group
- variable = 1 indicates an observation is the first observation in a BY group
- variable = 0 indicates an observation is not the last observation in a BY group
- variable = 1 indicates an observation is the last observation in a BY group
Although FIRST.variable and LAST.variable temporary variables are not automatically written to a SAS data set, once identified they can be used for special processing, reporting purposes, the creation of new variables, modification of existing variables, the structural change of a SAS data set, and more.
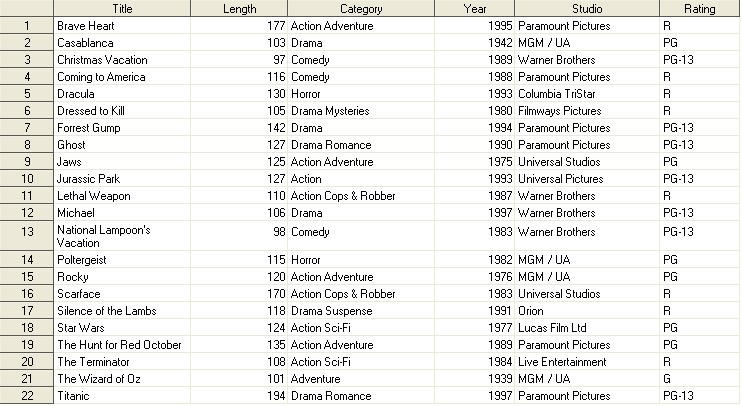
To illustrate this stalwart DATA step technique using the SQL procedure, a single table will be used, as shown below. The Movies table consists of six columns: Title, Category, Studio, and Rating are defined as character while Length and Year are defined as numeric.
MOVIES Table
As a longtime SAS user, I wanted a programming technique that could be used by PROC SQL users to emulate the DATA step’s FIRST., LAST., and By-group capabilities. Another important consideration was to have the technique operate similarly across operating systems and, if possible, with other vendor’s RDBMS SQL. The resulting technique uses an SQL subquery to identify the FIRST.row and LAST.row in each By-group.
Identifying FIRST.row in by-groups
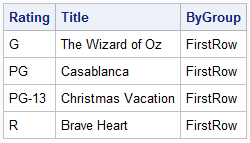
The FIRST.row technique, shown below, is constructed using an SQL subquery to identify the first, or beginning, row in each by-group. The process begins by producing a new table that contains the desired by-group order, physically sorting the rows in the MOVIES table in ascending order by the primary variable, RATING, and then in ascending order by the secondary variable, TITLE. Note: The outer query serves as a control group to ensure that processing takes place in the desired by-group order. Next, the MOVIES table is processed to evaluate the results of the MIN function specified in the inner most query (or subquery). The MIN function’s purpose is to capture the smallest (or minimum) value (for numeric variables), or minimum letter (for character variables) and use this value in the WHERE clause comparison. The previous operations are then repeated for each unique by-group in the MOVIES table.
/*************************************************************************/ /** ROUTINE.....: FIRST-BY-GROUP-ROW **/ /** PURPOSE.....: Identify the first (min) row in each by-group using a **/ /** subquery. **/ /*************************************************************************/ proc sql; create table first_bygroup_row as select rating, title, 'FirstRow' as ByGroup from movies M1 where title = (select MIN(title) from movies M2 where M1.rating = M2.rating) order by rating, title; |
FIRST.row Results
Identifying LAST.row in by-groups
The LAST.row technique, shown below, is constructed using an SQL subquery, with its purpose to identify the last, or ending, row in each by-group. The process begins by producing a new table that contains the desired by-groups, physically sorting the rows in the MOVIES table in ascending order by the primary variable, RATING, and then in ascending order by the secondary variable, TITLE. Note: The outer query serves as a control group to ensure that processing takes place in the desired by-group order. Next, the MOVIES table is processed to evaluate the results of the MAX function specified in the inner most query (or subquery). The MAX function’s purpose is to capture the maximum value (for numeric variables), or maximum letter (for character variables) and use this value in the WHERE clause comparison. The previous operations are then repeated for each unique by-group in the MOVIES table.
/************************************************************************/ /** ROUTINE.....: LAST-BY-GROUP-ROW **/ /** PURPOSE.....: Identify the last (max) row in each by-group using a **/ /** subquery. **/ /************************************************************************/ create table last_bygroup_row as select rating, title, 'LastRow' as ByGroup from movies M1 where title = (select MAX(title) from movies M2 where M1.rating = M2.rating) order by rating, title; quit; |
LAST.row Results

Further Considerations
The collating sequence for character variables under ASCII (UNIX, Windows, and OpenVMS) and EBCDIC (z/OS) are different. The default ASCII collating sequence sorts special characters and digits first, followed by uppercase letters, and finally lowercase letters. In contrast, the default EBCDIC collating sequence sorts special characters first, followed by lowercase letters, then uppercase letters, and digits last. Due to the encoding differences, users are encouraged to consult additional references on the topic of sort order and collating sequences.
Users may also want to consider using multi-threaded sorting for reducing the real time to completion for sort operations. New with SAS System 9, the SAS System option, THREADS, takes advantage of multi-threaded sorting which may be able to reduce CPU resources and costs.
For more information about the SQL procedure, check out Kirk Paul Lafler’s book, PROC SQL: Beyond the Basics Using SAS, Second Edition.
