決策樹的應用
決策樹的應用多是建立預測分類模型,應用產業層面包含:資料庫行銷的回應模型,找出對行銷活動有回應的客戶特徵與回應名單、交叉銷售尋找潛力客群、流失預測模型,找出客戶可能流失的原因與型態(pattern),提前進行客戶挽留、信用風險危機預警模型、詐欺偵測、製造業生產線良率的監控、在雷達信號分析、遠距感應、醫學診斷、專家系統、語音辨識,生物資訊及許多其它的領域。
這一期則告訴各位決策樹也可以當作分群方法。常見的分群方法有K-Means、SOM、Hierarchical cluster等方法,與各位分享利用SAS EM決策樹讓各位多了一種分群方法的選擇。
運用SAS EM決策樹進行分群分析
本範例資料情境為某銀行想針對既有貸款戶,針對其進件申請時的資料,進行客戶分群。分析人員想要從資金需求與資產狀況等角度來進行分群,因此選擇投入的分群變數有:CHILDREN(家中扶養孩子數)、INCOME(所得)、NMBLOAN(銀行貸款數)、PERS_H(家中人口數)、RESID(房屋自有狀況)。
第一步、匯入分析資料,決定變數角色。
將要進行分群分析的投入變數的變數角色設為Input,其他自變數則設為Reject。因此,CHILDREN(家中扶養孩子數)、INCOME(所得)、NMBLOAN(銀行貸款數)、PERS_H(家中人口數)、RESID(房屋自有狀況)等變數因為欲分群變數,故須將這些變數角色設為Input。

第二步、運用SAS EM決策樹進行分群分析。
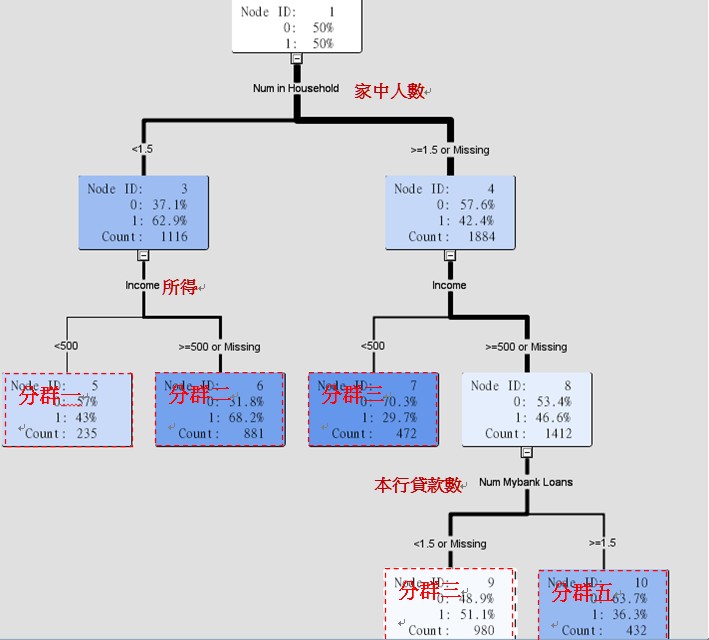
使用決策樹分析目的不在建立預測模型,故模型準度並非此處分析的目標,而是找出大致分群的結果。分群群數不能過多,否則難以管理與做最適命名。最終我們選擇下圖產生的五條預測規則決策樹分析結果,每一條預測規則即可視為是一個分群,因此我們初步針對既有貸款客戶區隔出五個差異分群。
產出分群後,下一步我們需要針對各分群的特徵值,進行分群命名。但初步透過決策樹所產生的各分群差異特徵值,主要有PERS_H(家中人口數)、INCOME(所得)以及NMBLOAN(銀行貸款數),若依這三大差異特徵值來進行群集命名,可參照的訊息可能有限。要怎麼補足在分群命名上資訊不足的問題?我們透過輔助觀察變數來加強命名說明。
所謂輔助觀察變數即是不為分群變數,不影響分群結果。輔助觀察變數雖不放入分群,但仍為分析研究人員想要在跨分群間比較的變數,因此僅就觀察比較,並可增加分群特徵的豐富性。
第三步、串接Segment Profile分群報表節點,產生分群報告。

由上圖,運用決策樹產生分群,最後再結合SAS EM的Segment Profile分群報表節點,產生群集報告。多數人在進行群集命名大都依各特徵差異變數的平均值來做跨群間的差異比較,用平均數比較來做命名資訊參照,容易造成一些資訊偏差的風險,尤其是特徵資料的分布呈右偏或左偏分布,此時平均數容易受資料分布中的相對極端值的影響,而失去母體代表性。
Segment Profile分群報表節點的特色為可在單一圖表裡,同時呈現母體和該分群在特定特徵變數的直方圖分布比較,快速地解讀分群與母體的特徵差異,而非僅就平均值來比較。與Segment Profile串接的分析節點,在匯入的資料角色裡必須要有一個變數角色為Segment,如上模型流程圖,決策樹產出的每一條預測規則樹葉節點(Leaf Node),在SAS EM預設的角色設定即為Segment,因此後續流程直接串接Segment Profile,便可直接產生集群報表。
第四步、設定輔助觀察變數,增加分群報表資訊豐富性,以利分群命名。
在Segment Profile變數設定裡,將想要在分群報表呈現的輔助觀察變數在Report裡設為Yes。

Segment Profile所產生的分群分布圖(如下圖),提供分析者更易於分析與解讀分群特色與差異,有利分群命名與管理。本期運用決策樹進行分群分析,並介紹結合Segment Profile產生完整的分群報表,教各位輔助觀察變數的應用,希望各位讀者能夠真正受用!

Tags
