資料處理篇
如何運用SAS EM進行變數處理與衍生變數產生(下)

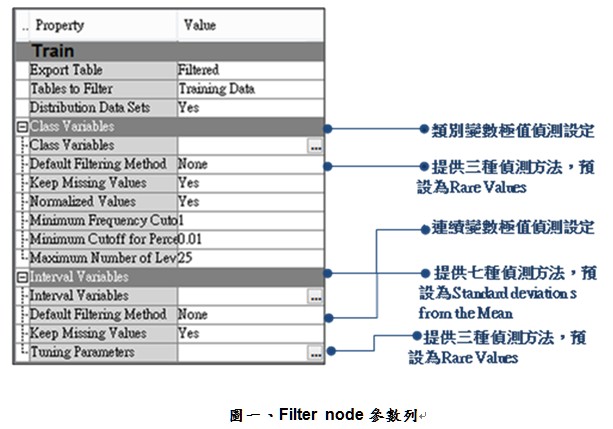
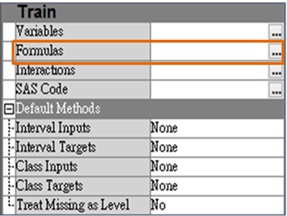
Transform Variables node變數轉換的案例情境說明 延續『如何運用SAS EM進行變數處理與衍生變數產生(中)』文章說明 4. 利用「Formula衍生變數編輯區」進行衍生變數處理 【情境說明】 -產生衍生變數公式編輯計算逾期週期 -運用SAS 運算函數進行變數轉換 step1. 點選參數列內的「Formulas」選項,進入衍生變數編輯區進行衍生變數處理。 圖一、Transform Variables Node參數列 step2. 點選「Formula衍生變數編輯區」視窗左上列的 (新增衍生變數鈕) 列內的「Formulas」選項,進入衍生變數編輯區進行衍生變數處理。 圖二、Formula衍生變數編輯區 step3. 點選「Build...」進入「Expression Builder」衍生變數公式編輯區。除了簡單的四則運算式編輯外,在編輯區下方提供各類運算函式,以利分析者進行進階演算式產出。 位於函數區旁的另一個頁籤,則完整列出原始資料集的變數清單,分析者無須記憶變數名稱,可透過點選拖曳方式將進階處理的變數投放入編輯區。 圖三、Formula衍生變數編輯區--新增變數 step4. 產生衍生變數一:「Delinq_Freq逾期週期」,衍生變數公式:IMP_CLAGE(貸款往來期間)/IMP_DELINQ (逾期次數)。 從「Variables List原始變數列表區」選取變數IMP_CLAGE及IMP_DELINQ,點選「Insert」將欲處理之變數置放於衍生變數公式編輯區進行上述公式編輯。 圖四、Formula衍生變數編輯區--變數公式編輯與變數命名 step5. 點選「OK」,完成衍生變數新增。 step6. 產生衍生變數二:「LOG_YOJ工作年資對數化」,衍生變數公式:LOG (IMP_YOJ)。 重複Step2、Step3 進行衍生變數新增程序,從「Functions函數區」選取 Log