如何確認您的 EG 版本

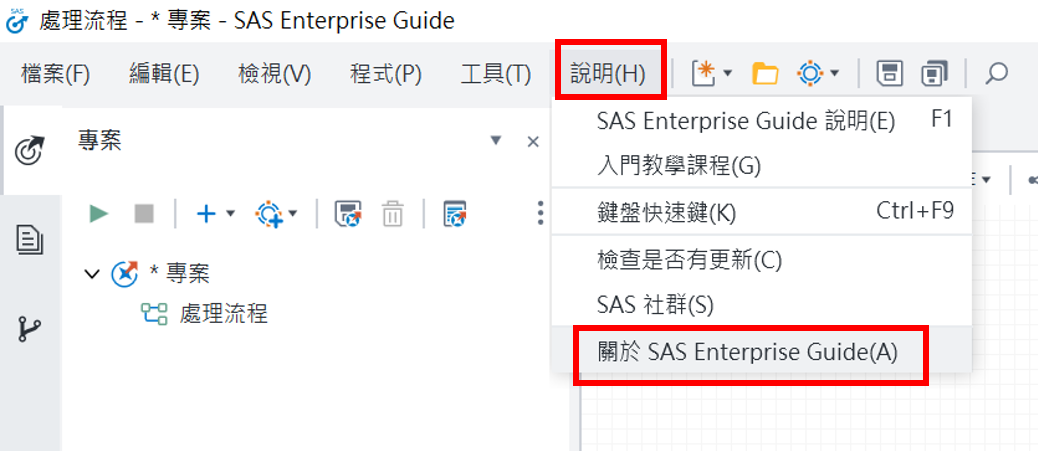
Q: 如何確認您電腦中的 SAS EG 版本? A: 請開啟EG,點選上方【說明】>【關於SAS Enterprise Guide】即可看到 SAS EG 版本

Q: 如何確認您電腦中的 SAS EG 版本? A: 請開啟EG,點選上方【說明】>【關於SAS Enterprise Guide】即可看到 SAS EG 版本
Q: SAS EG 8.1/ 8.2 在執行羅吉斯迴歸指派應變數時,當機無法執行怎麼辦? A: (1) 請安裝修復此功能的 hotfix (2) 或是直接將EG版本更新至 SAS EG Update5以上版本 (8.2.5.1277) 安裝修復此功能的 hotfix 請至 https://tshf.sas.com/techsup/download/hotfix/HF2/G5J.html#65398 下載 hotfix 若您的電腦為32位元,請下載此檔案: Download: G5J005wn.zip 若您的電腦為64位元,請下載此檔案: Download: G5J005x6.zip 參考 安裝 SAS Hot Fix 步驟 文章安裝hotfix 直接將EG版本更新至 SAS EG Update5以上版本 (8.2.5.1277) 請依 此網頁指示 更新SAS EG 版本
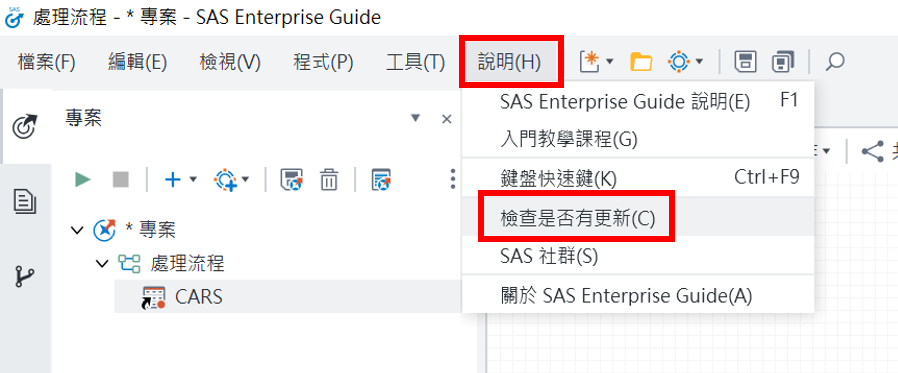
Q: 如何更新 SAS EG? A: 確認目前SAS EG 版本-請參考文章: 如何確認您的 EG 版本 若您是 EG 7 希望 更新為 EG 8 須完整移除電腦中的 SAS 軟體,在向學校軟體保管單位 (如資訊處/電算中心/計算機網路中心/採購系所)取得最新軟體後安裝 若您是EG 8.1 希望更新為 EG 8.2 或8.3 請開啟EG,點選上方【說明】>【檢查是否有更新】>【關閉並安裝】>跑完流程後點選【完成】即可 *若您欲更新到8.3以上,請務必先依 此網頁連結 更新 AutoUpdate檔案