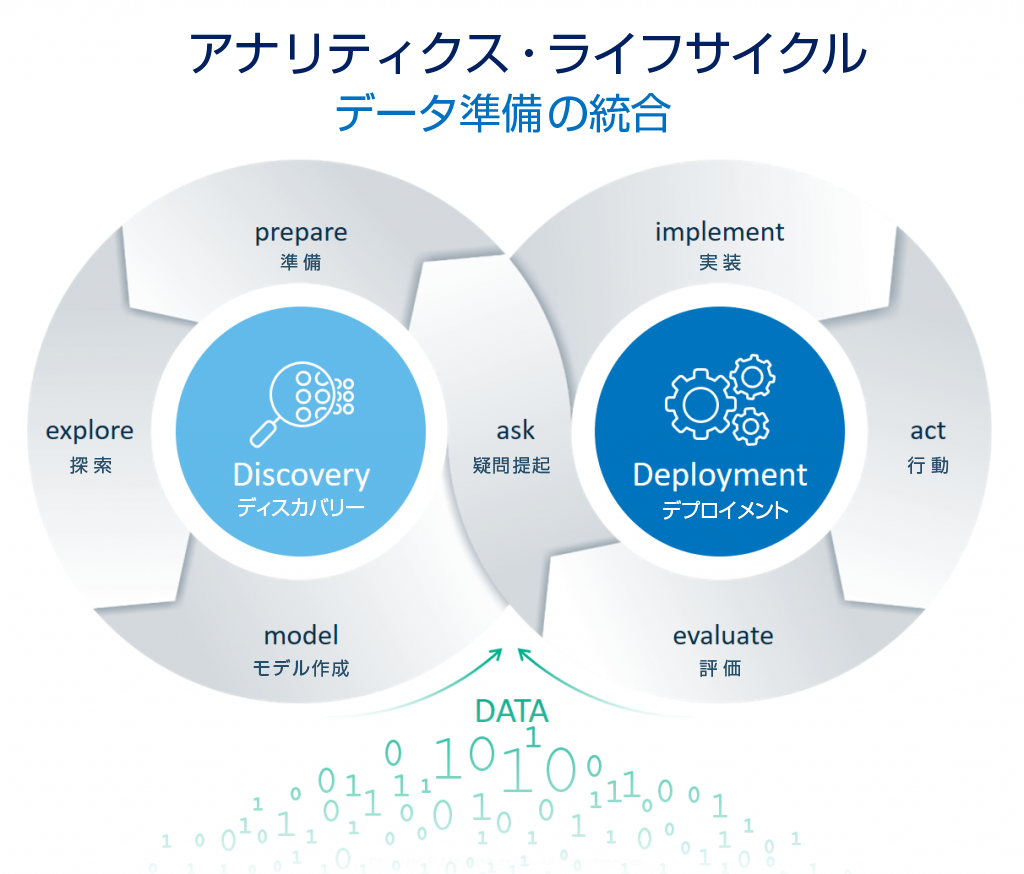
概要 第一回の「CASサーバーとSWATパッケージ」に続き、第二回としてCASのアクションセットの活用やCASサーバーへのデータ読み込みなどの基本操作の方法について紹介します。 アクションセットについて CASサーバー上での分析作業を開始する前に、“アクションセット”という重要な概念に関して紹介します。 アクションセットは、関連する機能を実行するアクションの論理的なグループです。 SAS Viyaでは、関数のことを「アクション」、関連する関数のグループを「アクションセット」と呼んでいます。アクションでは、サーバーのセットアップに関する情報を返したり、データをロードしたり、高度な分析を実行するなど、さまざまな処理を実行できます。 アクションセットを使ってみましょう それでは、サンプルコードを使いながら、SAS Viyaのアクションセットでデータの読み込みからプロットまでの一連の操作を説明します。 ・データの読み込み CASサーバーにデータを読み込むには二つの方法があります。一つはread.csv()でcsvファイルをRデータフレームの形で読み込んだ上で、as.casTable()を使用する方法です。この関数はデータをRのデータフレームからCASテーブルにアップロードすることができます。今回の例では金融関連のサンプルデータhmeqを使って紹介します。 library("swat") conn <- CAS(server, port, username, password, protocol = "http") hmeq_data <- read.csv(“hmeq.csv”) hmeq_cas <- as.casTable(conn, hmeq) もう一つはcas.read.csv()を使って、ローカルからファイルを読み込んで、そのままCASサーバーにアップロードする方法です。仕組みとしては、一つ目の方法と大きくは変わりません。 hmeq_cas <- cas.read.csv(conn, hmeq) as.casTable()或いはcas.read.csv()からの出力はCASTableオブジェクトです。その中に、接続情報、作成されたテーブルの名前、テーブルが作成されたcaslib(CASライブラリ)、およびその他の情報が含まれます。 Rのattributes()関数を使えば中身を確認できます。 attributes(hmeq_cas) $conn CAS(hostname=server, port=8777, username=user, session=ca2ed63c-0945-204b-b4f3-8f6e82b133c0, protocol=http) $tname [1] "IRIS" $caslib [1] "CASUSER(user)"