In the previous blog on CLASS variables, we developed the idea of creating design variables and examined GLM and reference coding. Consider our previous scenario of modeling the average amount spent on a credit card (SPEND) as a function of the variable INCOME (which has three levels: Low, Medium, and High). We have already added our design variables (Low, Medium, and High) to our simple data set:
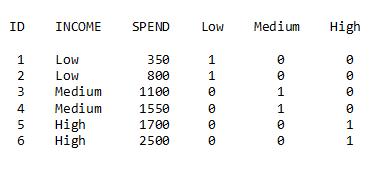
In the first blog on class variables in models, we previously used High as the reference level for our call to PROC REG, and got the following estimates for average amount spent on the credit card: Low income - 525; Medium income - 1325; and High income - 2100.
We can choose another reference level, by putting either Low or Medium last on the MODEL statement (or excluding one of them from the statement) in our call to PROC REG. The parameter estimates will change, but the average SPEND amounts will be the same.
Example: using Low as the reference level: (we'll put it last on the MODEL statement, but we could also omit it from the statement):
proc reg data=spend2; model spend= medium high low; run; |
The Intercept (575) now represents the average SPEND amount for the reference level Low. The average SPEND amount for Medium income is 575+750=1325 and for High income is 575+1575=2100. Even though the individual parameter estimates differ, these are the same average SPEND amounts obtained using High as the reference level.
Example: using Medium as the reference level:
proc reg data=spend2; model spend=low high medium; run; |
The Intercept (1325) now represents the average SPEND amount for Medium income; the average SPEND amount for Low is 1325-750=575, and for High it is 1325+775=2100.
When we choose different reference levels, the average spend amount will be the same; however, the parameter estimates will differ because we are using different reference levels.
If we don’t want to create our own design variables and we like the GLM coding scheme, PROC GLM with a CLASS statement can do the work for us. Putting INCOME on the CLASS statement will create design variables using GLM coding. The levels of INCOME will be sorted alphanumerically as High, Low, Medium and the last level will be the reference level. As a bonus, the LSMEANS statement shown below will give us the average SPEND amounts.
proc glm data=spend2; class income; model spend=income / solution; lsmeans income; run; |
The parameter estimates shown above match those from PROC REG using Medium as the reference level. The NOTE below the parameter estimate table sounds ominous, but its purpose is to advise us that levels other than Medium could be used as the reference level.

The Least Squares Means output provides the average SPEND amounts for our three INCOME categories; these values match our estimates obtained from PROC REG, as expected.
Another coding scheme, known as ‘Effect Coding’ or ‘Deviation from the Mean Coding’ can be used to create design variables…we’ll discuss that in the next installment of ‘Those Pesky CLASS Variables.’

1 Comment
Pingback: Tell Me about those Pesky CLASS Variables, Part 3: Effect Coding - The SAS Training Post