About once a month, a customer approaches SAS and asks a question of significance. By "significance", I don't necessarily mean "of great importance", but instead I mean "of how SAS handles large numbers, or floating-point values with many significant digits".
In response, we always first ask why they asked. This is not just a ploy to buy ourselves time. Often we learn that the customer has a legacy database system that represents some value as a very long series of digits. He wants to know if SAS can preserve the integrity of that value. Drilling in, we discover that the value represents something like a customer ID or account number, and no math will be performed using the value. In that case, the answer is easy: read it into SAS as a character value (regardless of its original form), and all will be well.
For the cases where the number is a number and the customer expects to use it in calculations, we must then dust off our lesson about floating-point math. We cite IEEE standards. As we've seen in this blog, floating-point nuances are good for "stupid math tricks", but they can also cause confusion when two values that appear to be the same actually compare as different under equality tests.
If we're lucky, this approach of citing standards makes us sound so smart that the customer is satisfied with the answer (or is too intimidated to pursue more questioning). But sometimes (quite often, actually), the customer is smarter, and fires back with deeper questions about exponents, mantissas and hardware capabilities.
That's when we tap someone like Bill Brideson, a systems developer at SAS who not only knows much that there is to know about floating-point arithmetic standards, but who also knows how to use SAS to demonstrate these standards at work -- when you display, compare, add, divide, and multiply floating-point values in SAS programs.
The remainder of this post comes from Bill. It's a thorough (!) explanation that he provided for a customer who was concerned that when he read the value "122000015596951" from a database as a decimal, it compared differently to the same value when read as an integer. He also provides a SAS program (with lots of comments) to support the explanation, as well as the output from the program when it was run using the example value.
Executive Summary (from Bill Brideson)
- SAS fully exploits the hardware on which it runs to calculate correct and complete results using numbers of high precision and large magnitude.
- By rounding to 15 significant digits, the w.d format maps a range of base-2 values to each base-10 value. This is usually what you want, but not when you're digging into very small differences.
- Numeric operations in the DATA step use all of the range and precision supported by the hardware. This can be more than you had in mind, and includes more precision than the w.d format displays.
- SAS has a rich set of tools that the savvy SAS consultant can employ to diagnose unexpected behavior with floating-point numbers.
I wrote a SAS program that shows what SAS and the hardware actually do with floating-point numbers. The program has the details; I’ll try to keep those to a minimum here. I hope you find some of the techniques in the SAS program useful for tackling problems in the future. (If you’re not familiar with hexadecimal, have a quick look at http://en.wikipedia.org/wiki/Hexadecimal.)
How the heck does floating-point really work?
The first DATA step and the PROC PRINT output titled 1: Software Calculation of IEEE Floating-Point Values, Intel Format use SAS to decompose and re-assemble floating-point numbers. Don't read the program in detail unless you're interested in this sort of thing, but do have a quick look at http://en.wikipedia.org/wiki/IEEE_754-1985 which shows the components of the IEEE floating-point format.
To talk about whether SAS can handle "large" numbers, we have to talk in terms of the native floating-point format that SAS uses on Intel hardware. Different manufacturers use different floating-point formats. Here, though, we’ll just worry about Intel.
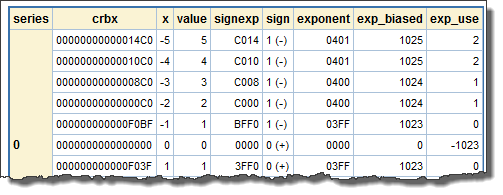
The columns of the PROC PRINT output are:
- crbx is the hexadecimal representation of the floating-point number as it is stored in memory and used in calculations.
- x is the same floating-point number, but printed using the w.d format.
- value is the result of decomposing and reconstructing the floating-point number. The algorithms in the DATA step are correct if x and value are equal.
- signexp is the sign and exponent portion of the floating-point number, extracted from the rightmost two bytes (four hexadecimal characters) of crbx and reordered so the bits read left-to-right in decreasing significance.
- sign shows the setting of the sign bit in the floating-point number.
- exponent shows the 11 exponent bits, right-justified. They’re a little hard to see in crbx and signexp.
- exp_biased is the decimal value of the exponent. The exponent doesn’t have its own sign bit, so biasing makes effectively negative exponents possible. See the code and the Wikipedia reference for details.
- exp_use is the decimal value of the exponent that is used to determine the value of the floating-point number. As you glance down the PROC PRINT output, notice how the exponent and mantissa change. (The mantissa is the first twelve and the fourteenth hexadecimal characters of crbx.)
The one-bit difference between the original values
The second DATA step assigns both of the customer's original values to variables in a DATA step and subtracts one from the other. The PROC PRINT output titled 2: The Two Original Values and Their Difference shows:
- x and crbx show the original value that evaluates to exactly an integer. x is the output of the w.d format, and crbx is the floating-point representation of x (shown in hexadecimal).
- y shows the original value that looked like an integer when displayed by the w.d format, and crby shows the floating-point representation of that value. The values of x and y look the same via the w.d format but, as crbx and crby show, the actual values of x and y are different.
- d shows the difference between x and y in base 10.
- crbd shows the difference between x and y in IEEE floating-point format. The hardware automatically normalizes numbers so that the value is positioned toward the most-significant mantissa bits. Here, no mantissa bits are set because the difference is exactly a power of 2 (see next bullet).
- signexp, exponent, exp_biased, and exp_use have the same meanings as above and show that the exponent is effectively -6. This value of exponent combined with the zero mantissa get us to the same value of d by a different route: 2**-6 is 1 divided by 2**6. In base 10, this is 1 divided by 64 = 1/64 = 0.015625.

Small, but real, differences that the w.d format does not show
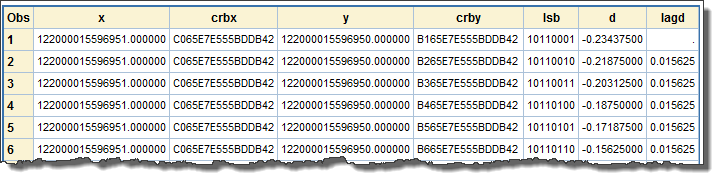
The customer could have had many different values that would have looked the same but compared unequal. The PROC PRINT output titled 3: Values Immediately Adjacent to the Customer’s Integer shows distinct values that display the same via the w.d format but are not, in fact, equal:
- x and crbx (decimal via the w.d format, and the floating-point format in hexadecimal, respectively) show the original value that evaluates to exactly an integer (again, x is displayed by the w.d format and w.d is the same value as shown in its floating-point representation).
- y (decimal, via w.d) and crby (floating-point, in hexadecimal) show values produced by the DATA step incrementing the mantissa one bit at a time. While the w.d format shows x and y to 15 significant decimal digits, crbx and crby show the actual floating-point values that the hardware uses, to all 52 bits of precision in the mantissa. This shows crby changing when the displayed value of y does not.
- lsb is the binary representation of the least-significant byte of the mantissa. Because Intel is byte-swapped and little-endian, crby can be hard to read; lsb makes it easier to see how the value increments by one bit each time. This value is the same as the first two hexadecimal characters of crby.
- d shows the difference between the value of y and the value of x on each observation, in base 10.
- lagd shows the difference between the value of d on the current observation and the value of d on the previous observation. This checks for consistent behavior.
How many bits get lost to rounding?
The next DATA step and the PROC PRINT output titled 4: Incrementing the Least-Significant of 15 Decimal Digits shows how many base-2 values occur between values that are rounded to 15 significant decimal digits:
- y and crby show the values that are being incremented by one. Here, the w.d format shows y changing value in base 10 because the change is within the 15 most significant digits.
- ls_12bits_hex extracts the least significant 12 bits of the mantissa for easier reading. These are shown in the first four hexadecimal characters of crby, but crby is hard to read anyway and especially so in a situation like this. The least-significant 12 bits are the only ones that change value through this series.
- ls_12bits_bin is the same value as ls_12bits_hex, but in binary. This shows more clearly which bit positions change value and which bit positions do not.
- d_10 is the base-10 difference between successive values in the least-significant bits of the mantissa. The ls_12bits_bin column shows clearly that the least-significant 6 bits of the mantissa never change; 2**6 is 64, so there are 64 possible base-2 values between each successive value of y.
- exp_use is decoded from y using the algorithm from the first step. Here, we’re looking for where the radix point belongs in the mantissa; in other words, where "1" is in the mantissa. The mantissa has 52 bits, so 52 – 46 tells us that there are six bits to the right of the radix point in these floating-point values. Combining this with the ls_12bits_bin column, it is clear that none of the bit positions that would represent a fractional value are changing.
- "Lowest 12 Bits Decoded" uses the algorithm from the first step to show that when just these bits of the mantissa are decoded, values are obtained that increase by one on each observation. The individual values are irrelevant because they’re just a piece of the mantissa, but the fact that they increment by one on each observation confirms the math from step 1.

What about actual math operations?
The PROC PRINT output titled 5: Results of Miscellaneous Math Operations show a few of the ways in which small differences between values can play out in calculations:
- operation shows the name of the operation that will be performed.
- x and crbx show the “exactly an integer” value (in decimal via w.d, and in floating-point via hexadecimal, respectively) that participates in the operation.
- y and crby (w.d and floating-point, like x and crbx) show the "integer plus 1/64 (least-significant mantissa bit)" value that participates in the operation.
- w and crbw (again, w.d and floating-point, respectively) show the result of the operation.
- d shows the difference between the results of the operation, and what the result would have been if both values participating in the operation had been x.
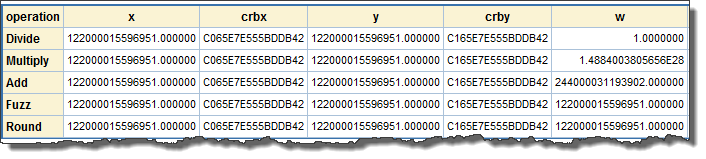
"Divide" shows that the w.d format displays the quotient (w) as 1.0, but crbw shows that the least-significant bit that was present in y is still present in the quotient (as it should be). While the quotient would not compare equal to 1.0, it would be displayed by the w.d format as 1.0 because the difference is 2.2E-16, which is less than 1E-15.
"Multiply" shows the result of multiplying 122,000,015,596,951.0 by 122,000,015,596,951.015625, and compares that result to multiplying 122,000,015,596,951.0 by itself. The difference is about 2.3E12, and 122,000,015,596,951.0 * 0.015625 = 1.9E12. This rounding error shows how a DATA step programmer can be surprised if they don't pay attention to the actual precision of values they use in calculations. Applying the round() function to operands before they’re used in a calculation can prevent this kind of problem.
"Add" shows that that least-significant bit got lost when the two values were added. The fourth hexadecimal character from the right of crbw shows that the value of the exponent increased by one (from D to E). This effectively shifted-out the least-significant bit of the mantissa. This could be an unexpected "rounding error."
"Fuzz" shows that the fuzz() function is useless to resolve nuisance differences in numbers of this magnitude because fuzz() only rounds values that are within 1E-12 of an integer. Since 0.015625 is much larger than 1E-12, fuzz() doesn’t round the non-integer value.
"Round" shows that round() does, however, turn a potentially problematic value into a nice, clean value.
Coming back up for air
Thank you to Bill for providing this tremendous detail. If you're a SAS programmer who is sometimes curious about numeric representation, this content should keep you chewing for a while. Here are a few other resources that you might find useful:
- Lengths and Formats: the long and short of it
- What's the difference between 0 and -0?
- Numerical precision in SAS software (SAS documentation)
- Numerical Precision 101 (SAS technical paper)
- Dealing with numerical representation error in SAS applications (SAS technical paper)
- Why .1 + .1 Might Not Equal .2 and Other Pitfalls of Floating-Point Arithmetic (SAS Global Forum paper by Clarke Thacher, SAS)

13 Comments
Great post. I don't think a lot of people know you can also create java objects in a SAS program, then call BigInt and BigDec classes for 32k (whatever the max length of a character var is) digits of precision.
Thanks Ajay. If you want to use SAS to see just how big of an "int" that SAS can handle, see this post about the CONSTANT function.
Bill should also mention which SAS functions are clean and which are rounding to integers.
Although documented in the full ref guide it was a surprise to me when I discovered that the Log functions certainly do this (round argument to integer if within 1x10 -12 of an integer.
You could argue that this means SAS does NOT support the full accuracy of the hardware.
Dave, you might want to review Clarke's paper on floating-point arithmetic in SAS. It contains more detail about specific functions, and illustrates some of the concepts with useful pictures as well.
Just a passing curiosity ... do you remember many moons ago (1994) when Intel had their Pentium FDIV bug that caused issues with floating point calculations? I've always wondered how that affected SAS software - more likely the calculations from SAS. I don't know if you have any "dirt" on that topic .. what version of SAS would have even been active then?
Tricia, you can't possibly be old enough to remember this. You must have dug up this nugget from the history books. That would have been SAS v6.10 or so. SAS v7 was under development, and the PC host group (Windows and OS/2) did add code to the system to detect and "fix" the FDIV error with a software patch. That code has long-since been removed.
Great article overall!
@Chris & Tricia, If Tricia isn't old enough to remember the Intel FDIV situation, I certainly am. Luckily I didn't have to pursue any code tricks to get around it, but I'm sure some folks did.
Precision and significance in FP calculations has always been quite interesting. As noted in the article, that is why SAS is rarely, if ever used, in accounting apps. An interesting case I ran into back in 98/99 was with importing data from an IBM DB2 data base into SAS - a DB2 decimal field consisting of four digits in the form yy.mm, where the integer portion represented a year and the decimal portion a month. The mm portion contained a value between 01 and 12. For some reason, any value where the month was 03 (i.e. 98.03) would appear to be February, even when written using a format of 5.2. Now I know the IBM main frame FP standard is not the same as the IEEE standard, and I would have liked to have had the time to pursue the why of this phenomenom at the time, but I never could get round to it. I was able to correct the situation by simply using the ROUND function, to two decimal places, when reading the data. In this particular case, the numbers are not very large or very small, so the behaviour of the platform seemed odd, though I am aware that base 16 FP representation as on the IBM MF has its own unique set of precision issues as compared to a base 10 system like Intel. Maybe Chris or Bill can shed some light on what was happening?
Peter, I can't say for certain what was happening, but I do know that we have had similar comments from other customers when bringing "decimal" data into SAS. The numbers look formatted the same, but then when you do calculations, the sums come out differently than they did on the source system -- due to the different floating-point standards. Does it matter? At best, floating-point numbers are a leaky abstraction (see blog post by John D. Cook). But the differences can be disquieting to those checking against legacy systems.
In your scenario, I suppose I would have advised reading the date value as character, and then parsing out the year and month values before converting to their unambiguous integer form. You can do that with SAS/ACCESS options to force certain variables to be read as CHAR. "Back in the day", the options might have been more limited.
Pingback: Myths about 64-bit computing on Windows - The SAS Dummy
Pingback: Jedi SAS Tricks: Finding Tattoine with DS2
Pingback: Format your data like a social media superstar - The SAS Dummy
Chris:
The explanation of signexp is as follows:
signexp is the sign and exponent portion of the floating-point number, extracted from the rightmost two bytes (four hexadecimal characters) of crbx and reordered so the bits read left-to-right in decreasing significance.
I think there is a minor error in the statement. Shouldn't it be "so the BYTES read left-to-right ..."? After all, the trailing 14C0 in crbx is being put in signexp as C014, i.e. within each byte, bit order is preserved (i.e. C0 is C0 and 14 is 14). If it were reverse ordered at the bit level, I believe it would be 0328.
Mark,
Thanks for the comment -- yes, I think you're correct. When we're looking at hex we're really examining the bytes, not the bits. I've updated the text accordingly. Thanks for pointing it out!