Ask any data warehouse architect what is driving the “big data” craze and he’ll tell you it has to do with the cost of storage and the advancements in distributed computing and most likely will mention Hadoop. Most enterprise data warehouses are constrained by cost and scalability of relational databases.
The simple fact is that most databases were designed to deal with data measured in the hundreds of gigabytes to a few terabytes they weren’t prepared or designed to handle the structural and computational demands of the analytic community. For example, many relational databases have a hard limit on the number of columns and the width of result sets generally between 255 and 1,000 variables however many RDMS still only support 255 columns.
To further put it into perspective, I was recently working on an analytic dataset where phrase counts were combined with customer response history, the very wide data set (but typical) had nearly 5000 columns, to build a predictive model I still need to figure out which of those columns are likely to be predictive. And that is where the iterative and exploratory nature of data mining is at odds with traditional database technology. This is yet another reason why people are turning to storage alternatives like Hadoop.
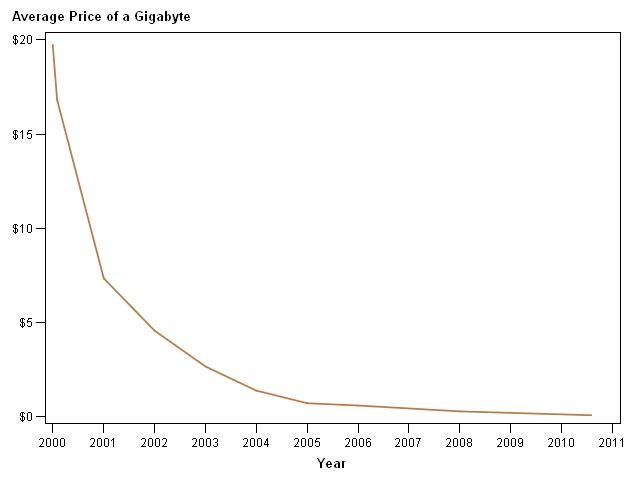
Let’s take a look at cost of storage. I pulled some data from Historical Notes about the Cost of Hard Drive Storage Space. The cost of a Gigabyte of storage has dropped from around $19 - 16 in 2000 to less than $0.07 today.
Part of the Hadoop equation is about the economics of storage. In some ways (and if you drink the cool aide), Hadoop storage is nearly free. The other part of the Hadoop equation is the lack of limitations (and features) that relational databases have. For example, if you want to mash structured and semi-structured data with binary data together, you can do it. If you want to make really wide data sets with thousands of variables, you can do it. Some can argue that Hadoop doesn’t do this, that, or the other easily -- and they are probably right -- but the fact is that for extreme data challenges (see I’m trying not to use the Big Data term), Hadoop is a great fit.
Let’s get real however…
Based on the average cost per terabyte of compute capacity of a pre-packaged Hadoop system, Hadoop is easily 10x cheaper for comparable computing capacity over traditional data warehouse appliance systems; however it doesn’t tell the whole cost of computing story.
The fixed cost of hardware is just one factor to consider and like most choices in life there is a tradeoff to be made. Usability is one aspect of Hadoop; it isn’t for everyone. Another aspect is talent acquisition. Today, Hadoop administrators and map reduce developers come priced at a premium – assuming you can find one. There is a dearth of Hadoop savvy talent out there that many of the distribution providers are trying to address with training. While training is a good start, there is no better teacher like experience; and that unfortunately takes time.

3 Comments
Great post Mike!
I also agree with you that the real story behind Hadoop is Cost and Flexibility, often hidden behind the noisy discussions around volume and social media content.
In many ways, the Hadoop story itself is a classic open source story!
Two of the key initial drivers for the first open source movements were also cost, and flexibility.
Cost because open source software like Linux was basically free, flexibility because having access to the source code means you can port it to any hardware platform and practically do anything you want with it (including powering your playstation!)
Linux also took years to go main stream due to lack of skilled personnel and corporate support, I guess Hadoop is history repeating itself.
Pingback: This week in blogs: SAS ODS, Hadoop and hangovers - SAS Voices
Pingback: IT considerations for analytics in 2012