A common question on SAS discussion forums is how to use SAS to generate random ID values. The use case is to generate a set of random strings to assign to patients in a clinical study. If you assign each patient a unique ID and delete the patients' names, you can preserve the patients' privacy during data analysis.
A common requirement is that the strings be unique. This presents a potential problem. In a set of random values, duplicate values are expected. Think about rolling a six-sided die several times: you would expect to see a duplicate value appear after a few rolls. Even for a larger set of possible values, duplicates arise surprisingly often. For example, if a room contains 23 people, the Birthday Paradox shows that it is likely that two people in the room have the same birthday!
If you generate N random numbers independently, you will likely encounter duplicates. There are several ways to use SAS to achieve both randomness and unique values. Perhaps the easiest way is to start with a long list of unique values, then randomly select N of these values. You can do the selection in either of two ways:
- Generate a random permutation of these values. Assign the first N permuted values to the subjects.
- Use sampling without replacement to select N values from the long list.
A third way to obtain random strings without duplicates is to use a SAS/IML program.
This article shows how to use SAS to generate random four-character strings. You can use the strings as IDs for subjects in a study that requires hiding the identity of the subjects. The article also discusses an important consideration: some four-character strings are uncomplimentary or obscene. I show how to remove vulgar strings from the list of four-character strings so that no patient is assigned an ID such as 'SCUM' or 'SPAZ'.
A mapping between strings and integers
I have previously shown that you can associate each string of English characters with a positive integer. For most applications, it suffices to consider four-digit strings because there are 264 = 456,976 strings that contains four English characters from the set {A, B, C, ..., Z}. Thus, I will use four-character strings in this article. (If you use five-character strings, you can assign up to 11,881,376 unique IDs.)
The following SAS DATA step outputs the integers 0 through 264-1. For each integer, the program also creates a four-character string. Small integers are padded with "leading zeros," so that the integers 0, 1, 2, ..., 456975, are associated with the base 26 strings AAAA, AAAB, AAAC, ..., ZZZZ. See the previous article to understand how the program works.
/* Step 1: Generate all integers in the range [0, 26^k -1] for k=4. See https://blogs.sas.com/content/iml/2022/09/14/base-26-integer-string.html Thanks to KSharp for the suggestion to use the RANK and BYTE functions: rank('A') = 65 in ASCII order byte(rank('A') + j) is the ASCII character for the j_th capital letter, j=0,1,...,25 */ %let nChar = 4; /* number of characters in base 26 string */ data AllIDs; array c[0:%eval(&nChar-1)] _temporary_ ; /* integer coefficients c[0], c[1], ... */ length ID $&nChar; /* string for base b */ b = 26; /* base b = 26 */ offset = rank('A'); /* = 65 for ASCII order */ do nID = 0 to b**&nChar - 1; /* compute the coefficients that represent nID in Base b */ y = nID; do k = 0 to &nChar - 1; c[k] = mod(y, b); /* remainder when r is divided by b */ y = floor(y / b); /* whole part of division */ substr(ID,&nChar-k,1) = byte(offset+c[k]); /* represent coefficients as string */ end; /* Some strings are vulgar. Exclude strings on the denylist. */ if ID not in ( 'CRAP','DAMN','DUMB','HELL','PUKE','SCUM','SLUT','SPAZ' /* add F**K, S**T, etc */ ) then output; end; drop b offset y k; run; |
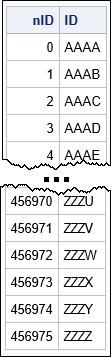
The table shows the first few and the last few observations in the data set. The ID column contains all four-character strings of English letters, except for words on a denylist. The list of objectionable words can be quite long, so I included only a few words as an example. I left out the F-bomb, other vulgar terms, and racist slurs. The appendix contains a more complete denylist of four-letter words.
Random permutation of the complete list
The first step created a list of unique four-character ID values. The second step is to randomly select N elements from this list, where N is the number of subjects in your study that need a random ID. This section shows how to perform random selection by permuting the entire list and selecting the first N rows of the permuted data.
The following DATA step generates a random uniform number for each ID value. A call to PROC SORT then sorts the data by the random values. The resulting data set, RANDPERM, has randomly ordered ID values.
/* Option 1: Generate a random permutation of the IDs */ data RandPerm; set AllIDs; call streaminit(12345); _u = rand("uniform"); run; /* sort by the random variate */ proc sort data=RandPerm; by _u; run; /* proc print data=RandPerm(obs=10) noobs; var nID ID; run; */ |
You can use PROC PRINT to see that the ID values are randomly ordered. Because we started with a list of unique values, the permuted IDs are also unique.
You can now merge the first N random IDs with your data. For example, suppose I want to assign an ID to each student in the Sashelp.Class data set. The following program counts how many subjects (N) are in the data, and merges the first N random IDs with the data:
/* Count how many rows (N) are in the input data set */ %let dsName = sashelp.class; proc sql noprint; select count(*) into :N from &DSName; quit; data All; merge &DSName RandPerm(keep=ID obs=&N); run; proc print data=All(obs=8) noobs label; var ID Name _NUMERIC_; run; |
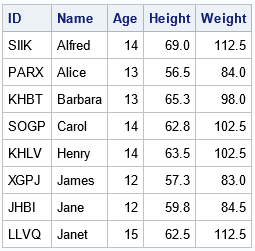
The output shows that each student is assigned a random four-character ID.
Use PROC SURVEYSELECT to select IDs
The previous section uses only Base SAS routines: The DATA step and PROC SQL. An alternative approach is to extract N random IDs by using PROC SURVEYSELECT in SAS/STAT software. In this approach, you do not need to generate random numbers and manually sort the IDs. Instead, you extract the random values by using PROC SURVEYSELECT. As of SAS 9.4 M5, the SURVEYSELECT procedure supports the OUTRANDOM option, which causes the selected items in a simple random sample to be randomly permuted after they are selected. Thus, an easier way to assign random IDs is to count the number of subjects, randomly select that many ID values from the (unsorted) set of all IDs, and then merge the results:
/* Option 2: Extract random IDs and merge */ %let dsName = sashelp.class; proc sql noprint; select count(*) into :N from &DSName; quit; proc surveyselect data=AllIDs out=RandPerm noprint seed=54321 method=srs /* sample w/o replacement */ OUTRANDOM /* SAS 9.4M5 supports the OUTRANDOM option */ sampsize=&N; /* number of observations in sample */ run; data All; merge &DSName RandPerm(keep=ID); run; proc print data=All(obs=8) noobs label; var ID Name _NUMERIC_; run; |
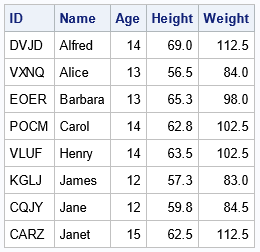
The table shows the ID values that were assigned to the first few subjects.
A SAS/IML method
Both previous methods assign random strings of letters to subjects. However, I want to mention a third alternative because it is so compact. You can write a SAS/IML program that performs the following steps:
- Create a vector that contains the 26 English letters.
- Use the EXPANDGRID function to create a matrix that contains all four-character combinations of letters. Concatenate those letters into strings.
- Optionally, remove objectional strings. You can use the ELEMENT function to identify the location of strings on a denylist.
- Use the SAMPLE function to generate a random sample (without replacement).
As usual, the SAS/IML version is very compact. It requires about a dozen lines of code to generate the IDs and write them to a data set for merging with the subject data:
/* Generate N random 4-character strings (remove words on denylist) */ proc iml; letters = 'A':'Z'; /* all English letters */ L4 = expandgrid(letters, letters, letters, letters); /* 26^4 combinations */ strings = rowcat(L4); /* concatenate into strings */ free L4; /* done with matrix; delete */ deny = {'CRAP','DAMN','DUMB','HELL','PUKE','SCUM','SLUT','SPAZ'}; /* add F**K, S**T, etc*/ idx = loc( ^element(strings, deny) ); /* indices of strings NOT on denylist */ ALLID = strings[idx]; call randseed(1234); ID = sample(strings, &N, "WOR"); /* random sample without replacement */ create RandPerm var "ID"; append; close; /* write IDs to data set */ QUIT; /* merge data and random ID values */ data All; merge &DSName RandPerm; run; proc print data=All(obs=8) noobs label; var ID Name _NUMERIC_; run; |
Summary
This article shows how to assign a random string value to subjects in an experiment. The best way to do this is to start with a set of unique strings. Make sure there are no objectionable words in the set! Then you can extract a random set of N strings by permuting the set or by using PROC SURVEYSELECT to perform simple random sampling (SRS). In the SAS/IML language, you can generate all strings and extract a random subset by using only a dozen lines of code.
In a DATA step, I used base 26 to generate the list of all four-character strings. By changing the definition of the nChar macro variable, this program also works for character strings of other lengths. If you set the macro to the value k, the program will generate 26k strings of length k.
Of the three methods, the first (DATA step and PROC SORT) is the simplest. It can also easily handle new subjects who are added to the study after the initial assignment of IDs. You can simply assign the next unused random IDs to the new subjects.
Appendix: A denylist of four-letter words
This appendix shows a list of objectionable words. You do not want to assign a patient ID that is obscene, profane, insulting, racist, sexist, or crude. I used several web pages to compile a list of four-letter words that some people might find objectionable. You can use an IF-THEN statement to block the following list four-letter English words:
/* some words on this list are from https://www.wired.com/2016/09/science-swear-words-warning-nsfw-af/ https://en.everybodywiki.com/List_of_profane_words */ if ID not in ( 'ANAL','ANUS','ARSE','BOOB','BUNG','BUTT','CLIT','COCK','COON','CRAP', 'CUMS','CUNT','DAMN','DICK','DONG','DUMB','DUMP','DYKE','FAGS','FUCK', 'GOOK','HEBE','HELL','HOMO','JEEZ','JERK','JISM','JIZZ','JUGS','KIKE', 'KNOB','KUNT','MICK','MILF','MOFO','MONG','MUFF','NADS','PAKI','PISS', 'POON','POOP','PORN','PUBE','PUKE','PUSS','PUTO','QUIM','SCUM','SHAG', 'SHAT','SHIT','SLAG','SLUT','SMEG','SPAZ','SPIC','SUCK','TARD','THOT', 'TOSS','TURD','TWIT','TWAT','WANK','WANG' ) then output; |

2 Comments
Thank you.
Sometimes it does get a little more difficult. Namely when the IDs have to conform to a certain pattern.
Here in Europe, not all social security numbers are valid and the same for account numbers and bank card numbers. They have to comply with certain arithmetic rules.
Randomly generating such IDs requires one more step.
Yes. Bank accounts and credit card numbers often include nonrandom numbers that associate the account with a financial institution and also incorporate checksums. This article generates subject IDs, not simulated account numbers.