What is a random number generator? What are the random-number generators in SAS, and how can you use them to generate random numbers from probability distributions? In SAS 9.4M5, you can use the STREAMINIT function to select from eight random-number generators (RNGs), including five new RNGs. After choosing an RNG, you can use the RAND function to obtain random values from probability distributions.
What is a random-number generator?
A random-number generator usually refers to a deterministic algorithm that generates uniformly distributed random numbers. The algorithm (sometimes called a pseudorandom-number generator, or PRNG) is initialized by an integer, called the seed, which sets the initial state of the PRNG. Each iteration of the algorithm produces a pseudorandom number and advances the internal state. The seed completely determines the sequence of random numbers. Although it is deterministic, a modern PRNG generates extremely long sequences of numbers whose statistical properties are virtually indistinguishable from a truly random uniform process.
An RNG can also refer to a hardware-based device (sometimes called a "truly random RNG") that samples from an entropy source, which is often thermal noise within the silicon of a computer chip. In the Intel implementation, the random entropy source is used to initialize a PRNG in the chip, which generates a short stream of pseudorandom values before resampling from the entropy source and repeating the process. A hardware-based RNG is not deterministic or reproducible.
An RNG generates uniformly distributed numbers. If you request random numbers from a nonuniform probability distribution (such as the normal or exponential distributions), SAS will automatically apply mathematical transformations that convert the uniform numbers into nonuniform random variates.
Using random numbers in the real world
In the real world, random numbers are used as the basis for statistical simulations. Financial analysts use simulations of the economy to evaluate the risk of a portfolio. Insurance companies use simulations of natural disasters to assess the impact on their customers. Government workers use simulations of population growth to predict the infrastructure and services that will be required by future generations. In all fields, data analysts generate random values for statistical sampling, bootstrap and resampling methods, Monte Carlo estimation, and data simulation.
For these techniques to be statistically valid, the values that are produced by statistical software must contain a high degree of randomness. The new random-number generators in SAS provide analysts with fast, high-quality, state-of-the-art random numbers.
New random-number generators in SAS
Prior to SAS 9.4M5, SAS supported the Mersenne twister random-number generator (introduced in SAS 9.1) and a hardware-based RNG (supported on Intel CPUs in SAS 9.4M3). SAS 9.4M5 introduces new random-number generators and new variants of the Mersenne twister, as follows:
- PCG: A 64-bit permuted congruential generator (O’Neill 2014) with good statistical properties.
- TF2: A 2x64-bit counter-based RNG that is based on the Threefish encryption function in the Random123 library (Salmon et al. 2011). The generator is also known as the 2x64 Threefry generator.
- TF4: A 4x64-bit counter-based RNG that is also known as the 4x64 Threefry generator.
- RDRAND: A hardware-based RNG (Intel, 2014) that is repeatedly reseeded by using random values from thermal noise in the chip. The RNG requires an Intel processor (Ivy Bridge and later) that supports the RDRAND instruction.
- MT1998: (deprecated) The original 1998 32-bit Mersenne twister algorithm (Matsumoto and Nishimura, 1998). This was the default RNG for the RAND function prior to SAS 9.4M3. For a small number of seed values (those exactly divisible by 8,192), this RNG does not produce a sufficiently random stream of numbers. Consequently, other RNGS are preferable.
- MTHYBRID: (default) A hybrid method that improves the MT1998 method by using the MT2002 initialization for seeds that are exactly divisible by 8,192. This is the default RNG, beginning with the SAS 9.4M3.
- MT2002: The 2002 32-bit Mersenne twister algorithm (Matsumoto and Nishimura 2002).
- MT64: A 64-bit version of the 2002 Mersenne twister algorithm.
Choose a random-number generator in SAS
In SAS, you can use the STREAMINIT subroutine to choose an RNG and to set the seed value. You can then use the RAND function to produce high-quality streams of random numbers for many common distributions. The first argument to the RAND function specifies the name of the distribution. Subsequent arguments specify parameters for the distribution.
If you want to use the default RNG (which is 'MTHYBRID'), you can specify only the seed. For example, the following DATA step initializes the default PRNG with the seed value 12345 and then generates five observations from the uniform distribution on (0,1) and from the standard normal distribution:
data RandMT(drop=i); call streaminit(12345); /* choose default RNG (MTHYBRID) and seed=12345 */ do i = 1 to 5; uMT = rand('Uniform'); /* generate random uniform: U ~ U(0,1) */ nMT = rand('Normal'); /* generate random normal: N ~ N(mu=0, sigma=1) */ output; end; run; |
If you want to choose a different RNG, you can specify the name of the RNG followed by the seed. For example, the following DATA step initializes the PCG method with the seed value 12345 and then generates five observations from the uniform and normal distributions:
data RandPCG(drop=i); call streaminit('PCG', 12345); /* SAS 9.4M5: choose PCG method, same seed */ do i = 1 to 5; uPCG = rand('Uniform'); nPCG = rand('Normal'); output; end; run; |
A hardware-based method is initialized by the entropy source, so you do not need to specify a seed value. For example, the following DATA step initializes the RDRAND method and then generates five observations. The three data sets are then merged and printed:
data RandHardware(drop=i); call streaminit('RDRAND'); /* SAS 9.4M3: Hardware method, no seed */ do i = 1 to 5; uHardware = rand('Uniform'); nHardware = rand('Normal'); output; end; run; data All; merge RandMT RandPCG RandHardware; run; title "Uniform Random Variates for Three RNGs"; proc print data=All noobs; var u:; run; title "Normal Random Variates for Three RNGs"; proc print data=All noobs; var n:; run; |
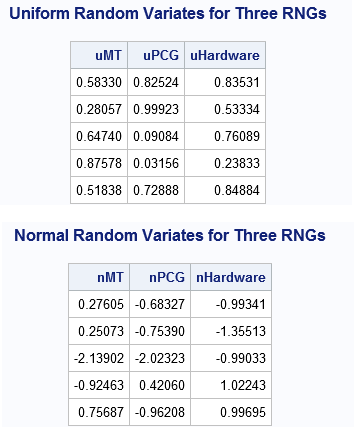
The output shows that each RNG generates a different sequence of numbers. If you run this program yourself, you will generate the same sequences for the first two columns (the MTHYBRID and PCG streams), but your numbers for the RDRAND RNG will be different. Each column of the first table is an independent random sample from the uniform distribution. Similarly, each column of the second table is an independent random sample from the standard normal distribution.
Summary
In SAS 9.4M5, you can choose from eight different random-number generators. You use the STREAMINIT function to select the RNG and use the RAND function to obtain random values. In a future blog post, I will compare the attributes of the different RNGs and discuss the advantages of each. I will also show how to use the new random-number generators to generate random numbers in parallel by running a DS2 program in multiple threads.
The information in this article is taken from my SAS Global Forum 2018 paper, "Tips and Techniques for Using the Random-Number Generators in SAS" (Sarle and Wicklin, 2018).
References
- Intel Corporation (2014). “Intel Digital Random Number Generator (DRNG) Software Implementation Guide.” Accessed December 23, 2017.
- Matsumoto, M., and Nishimura, T. (1998). “Mersenne Twister: A 623-Dimensionally Equidistributed Uniform Pseudorandom Number Generator.” ACM Transactions on Modeling and Computer Simulation 8:3–30.
- Matsumoto, M., and Nishimura, T. (2002). “Mersenne Twister with Improved Initialization.” Accessed April 10, 2015.
- O’Neill, M. E. (2014). "PCG: A Family of Simple Fast Space-Efficient Statistically Good Algorithms for Random Number Generation." Accessed December 23, 2017.
- Salmon, J. K., Moraes, M. A., Dror, R. O., and Shaw, D. E. (2011). “Parallel Random Numbers: As Easy as 1, 2, 3.” In SC ’11: 2011 International Conference for High Performance Computing, Networking, Storage and Analysis, p. 1–12.

16 Comments
Hi Rick!
Hi, Dane. Good to hear from you.
Hi Rick,
I am excited to try out the new random-number generators, and I wonder whether my system supporters thermal noise. We are still on SAS 9.4M4. While the old generators generally work well, I noticed some minor issues in some cases.
Thanks for the comment. You don't say which RNG you are using, but if you are using the VERY old RANUNI, RANNOR, ... series of functions, be sure to read the article "Six reasons you should stop using the RANUNI function to generate random numbers."
Hi Rick,
Thanks for this article. Could you suggest what is the best possible way of generating unique random numbers (i.e. without replacement)?
for example I want to generate 5000 unique random numbers (or IDs) to 5000 subjects.
I have been doing a do loop to check if the number exists in the array of already generated numbers. If the number exists, I regenerate it until it becomes unique.
I think this is not an efficient of generating unique random numbers. Any suggestions is highly appreciated.
Sure. I suggest that you look at the SURVEYSELECT procedure. as discussed in the article "Sample without replacement in SAS.". If you need to use the DATA step, the last sentence of that article contains a link. For an overview of various sampling techniques in SAS, see "Four essential sampling methods in SAS."
Rick, Quick Question. From SAS documentation I have read that Range of the seed values can be from 1 to 2^32-1 but from other SAS docs I read that the Range of the seed values can be from 1 to 2^31-1. I was wondering if you can shed some light on that as to which one can be used? We are using default MT Hybrid method.
The random number functions were revised in SAS 9.4M5. The documentation provides the correct range of the random number seeds. If you provide the link to a doc page for RAND or STREAMINIT (post-9.4M5) that says something different, I might be able to comment further.
Thanks Rick for the clarification!. I have a follow-up question if I may ask. We are using a seed value of 12345 and feeding it into call streaminit to initiate a random number generation program in SAS® Version 9.4 (based on the Hybrid 1998/2002 32-bit Mersenne twister). We are using the below code and we are using the PROC PLAN to create the randomization schedule.
user_seed=12345;
call streaminit(user_seed);
rand_num = ceil((2**31 - 1)*rand("uniform"));
When I used the 2**32 instead, it was giving me a SAS ERROR "The SEED value exceeds the largest integer that can be stored on this machine" which prompted me to change it to 2**31. So is 2**31 a max seed value limitation for PROC PLAN?. Hope my question make sense.
1. Please ask SAS programming questions at the SAS Support Communities.
2. PROC PLAN is not the DATA step. Just because the DATA step supports a wider range of seeds does not imply that procedures do.
3. In SAS 9.4M5, you can generate a random integer between 1 and M by using rand_num = rand("Integer", 1, M);
HI Rick,
thank for your explanations.
Could you help me in simulating correlated categorical (nominal) data ?.
My aim is to check some statistical properties about the Cohen's kappa.
Many tahnks for your help
BMCesana
For multinomial data, see "Simulate from the multinomial distribution in SAS." The correlations in multinomial data are determined by the probability of each category.
The case of general correlated categorical variables is more complicated. I present it in Chapter 9 of Simulating Data with SAS (Wicklin, 2013). Appendix B of that book provides some useful SAS/IML functions.
Dear Rick,
Many thanks for your very fast and kind reply.
Unfortunately, I think that the problem is too much complicated.
Indeed I need to simulate 2 multinomial (multicategorial) distributions maybe with different probabilities (the 2 raters can give their rating with different probabilities) that are correlated to exprime the agreement of the two raters.
So, the two distributions are uncorrelated in the case of an agreement absolutely by chance and are more an more positively correlated in the case of an increasing agreement.
Many thanks for your help
Bruno Mario Cesana
It sounds like you might have a mixture of distributions. Regardless, the most important thing in simulation is to be able to write down the distribution or model you are simulating from. Think about how you would analyze the data, then use the documentation for that procedure to help you formulate the model in the simulation. Good luck.
Dear Rick, I don't think that there is a mixture of distributions underlying the model. Indeed, the problem is that there are two raters: the first assigns a value from an ordinal scale (absent, moderate and severe) or nominal scale (depression, anxiety, schizophrenia) the subjects according to the marginal probabilitis of the rows of a contingency table.
The same applies for the second rater which assigns the subjects according to the marginal probabilities of the columns of a contingency table.
Of course, the marginal probabilities do not have to be the same.
If there is no agreement the two multinomial / multicategorical distributions are not correlated, but in the case of an agreement, the two distributions are correlated.
The following papers are very useful for illustrating the problem. In addition, the second shows a SAS IML Macro for generating correlated data, but in the context of longitudinal studies.
1)-A.J. Lee Some simple methods for generating correlated categorical variates Computational Statistics & Data Analysis 26 (1997) 133-148
2)-Noor Akma Ibrahim, Suliadi Suliadi Generating correlated discrete ordinal data using
R and SAS IML computer methods and programs in biomedicine 104 ( 2011 ) e122–e132
Many thanks for your help in having the IML code for obtaining two correlated multinomial / categorical distributions
Again, I direct you to Chapter 9 and Appendix B of my book, which implements a method by Kaiser, Träger, and Leisch (2011), which builds on the work of Demirtas (2006). Good luck.