Finding nearest neighbors is an important step in many statistical computations such as local regression, clustering, and the analysis of spatial point patterns. Several SAS procedures find nearest neighbors as part of an analysis, including PROC LOESS, PROC CLUSTER, PROC MODECLUS, and PROC SPP. This article shows how to find nearest neighbors for every observation directly in SAS/IML, which is useful if you are implementing certain algorithms in that language.
Compute the distance between observations
Let's create a sample data set. The following DATA step simulates 100 observations that are uniformly distributed in the unit square [0,1] x [0,1]:
data Unif; call streaminit(12345); do i = 1 to 100; x = rand("Uniform"); y = rand("Uniform"); output; end; run; |
I have previously shown how to compute the distance between observations in SAS by using PROC DISTANCE or the DISTANCE function in SAS/IML. The following statements read the data into a SAS/IML matrix and computes the pairwise distances between all observations:
proc iml; use Unif; read all var {x, y} into X; close; D = distance(X); /* N x N distance matrix */ |
The D matrix is a symmetric 100 x 100 matrix. The value D[i,j] is the Euclidean distance between the ith and jth rows of X. An easy way to look for the nearest neighbor of observation i is to search the ith row for the column that contains smallest distance. Because the diagonal elements of D are all zero, a useful trick is to change the diagonal elements to be missing values. Then the smallest value in each row of D corresponds to the nearest neighbor.
You can use the following statements assigns missing values to the diagonal elements of the D matrix. You can then use the SAS/IML subscript reduction operators to find the minimum distance in each row:
diagIdx = do(1, nrow(D)*ncol(D), ncol(D)+1); /* index diagonal elements */ D[diagIdx] = .; /* set diagonal elements */ dist = D[ ,><]; /* smallest distance in each row */ nbrIdx = D[ ,>:<]; /* column of smallest distance in each row */ Neighbor = X[nbrIdx, ]; /* coords of closest neighbor */ |
Visualizing nearest neighbors
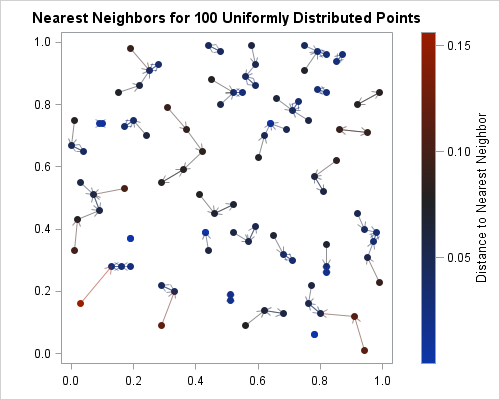
If you write the nearest neighbors and distances to a SAS data set, you can use the VECTOR statement in PROC SGPLOT to draw a vector that connects each observation to its nearest neighbor. The graph indicates the nearest neighbor for each observation.
Z = X || Neighbor || dist; create NN_Unif from Z[c={"x" "y" "xc" "yc" "dist"}]; append from Z; close; QUIT; title "Nearest Neighbors for 100 Uniformly Distributed Points"; proc sgplot data=NN_Unif aspect=1; label dist = "Distance to Nearest Neighbor"; scatter x=x y=y / colorresponse=dist markerattrs=(symbol=CircleFilled); vector x=xc y=yc / xorigin=x yorigin=y transparency=0.5 colorresponse=dist; /* COLORRESPONSE= requires 9.4m3 for VECTOR */ xaxis display=(nolabel); yaxis display=(nolabel); run; |
Alternative ways to compute nearest neighbors
If you don't have SAS/IML but still want to compute nearest neighbors, you can use PROC MODECLUS. The NEIGHBOR option on the PROC MODECLUS statement produces a table that gives the observation number (or ID value) of nearest neighbors. For example, the following statements produce the observation numbers for the nearest neighbors:
ods select neighbor; /* Use K=p to find nearest p-1 neighbors */ proc modeclus data=Unif method=1 k=2 Neighbor; /* k=2 for nearest nbrs */ var x y; run; |
To get the coordinates of the nearest neighbor, you can create a variable that contains the observation numbers and then use an ID statement to include that ID variable in the PROC MODECLUS output. You can then look up the coordinates. I omit the details.
Why stop at one? A SAS/IML module for k nearest neighbors
You can use the ideas in the earlier SAS/IML program to write a program that returns the indices (observation numbers) of the k closest neighbors for k ≥ 1. The trick is to replace the smallest distance in each row with a missing value and then repeat the process of finding the smallest value (and column) in each row. The following SAS/IML module implements this computation:
proc iml;
/* Compute indices (row numbers) of k nearest neighbors.
INPUT: X an (N x p) data matrix
k specifies the number of nearest neighbors (k>=1)
OUTPUT: idx an (N x k) matrix of row numbers. idx[,j] contains
the row numbers (in X) of the j_th closest neighbors
dist an (N x k) matrix. dist[,j] contains the distances
between X and the j_th closest neighbors
*/
start NearestNbr(idx, dist, X, k=1);
N = nrow(X); p = ncol(X);
idx = j(N, k, .); /* j_th col contains obs numbers for j_th closest obs */
dist = j(N, k, .); /* j_th col contains distance for j_th closest obs */
D = distance(X);
D[do(1, N*N, N+1)] = .; /* set diagonal elements to missing */
do j = 1 to k;
dist[,j] = D[ ,><]; /* smallest distance in each row */
idx[,j] = D[ ,>:<]; /* column of smallest distance in each row */
if j < k then do; /* prepare for next closest neighbors */
ndx = sub2ndx(dimension(D), T(1:N)||idx[,j]);
D[ndx] = .; /* set elements to missing */
end;
end;
finish; |
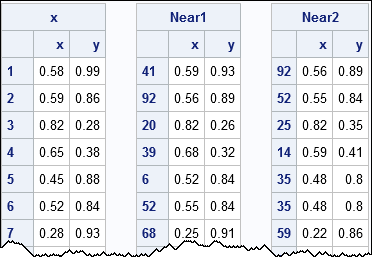
You can use this module to compute the k closest neighbors for each observation (row) in a data matrix. For example, the following statements compute the two closest neighbors for each observation. The output shows a few rows of the original data and the coordinates of the closest and next closest observations:
use Unif; read all var {x, y} into X; close;
k=2;
run NearestNbr(nbrIdx, dist, X, k);
Near1 = X[nbrIdx[,1], ]; /* 1st nearest neighbors */
Near2 = X[nbrIdx[,2], ]; /* 2nd nearest neighbors */ |
In summary, this article defines a short module in the SAS/IML language that you can use to compute the k nearest neighbors for a set of N numerical observations. Notice that the computation builds an N x N distance matrix in RAM, so this matrix might consume a lot of memory for large data sets. For example, the distance matrix for a data set with 16,000 observations requires about 1.91 GB of memory. For larger data sets, you might prefer to use PROC DISTANCE or PROC MODECLUS.

9 Comments
http://support.sas.com/documentation/cdl/en/grstatproc/67909/HTML/default/viewer.htm#p1wtsx90517bf4n12fpaaeh6za0l.htm is the link for the VECTOR statement in PROC SGPLOT.
Thanks for showing us how to visualize nearest neighbors!
Very neat post!
Can we expand the same method to more complicated business case?
Suppose having 1 million customers with valid home address in US. Home address can be converted to the exact location (latitude, longitude). From the center of each zip code(more than 40,000), how to pick top 100 nearest customers based on the distance between two points?
For simplicity, assume that the nearest homes have the same zip code as the center of the zip. This reduces the problem to 40,000 small problems. For each zip code, find the households that are in that zip code and are closest to the center. You don't even need to use the DISTANCE function because you are comparing the distance from the houses to the center of the zip code. If "center" is the coordinates of the zip code center and "household" is a matrix where each row contains the coordinates of houses in the zip code, you can compute the nearest houses by using the following SAS/IML statements:
Pingback: The distribution of nearest neighbor distances - The DO Loop
Pingback: Distances between observations in two groups - The DO Loop
Pingback: What is loess regression? - The DO Loop
Pingback: Ten posts from 2016 that deserve a second look - The DO Loop
Pingback: Is "La Quinta" Spanish for "Next to Denny's"? - The DO Loop
Pingback: Implement a SMOTE simulation algorithm in SAS - The DO Loop