As announced and demonstrated at SAS Innovate 2024, SAS plans to include a generative AI assistant called SAS Viya Copilot in the forthcoming SAS Viya Workbench. You can submit a text prompt (by putting it in a comment string) and the Copilot will generate SAS code for you.
My colleagues and I were discussing the reproducibility of the AI assistant. That is, suppose two SAS customers give the same prompt to the Copilot. Should they expect the same response? This article explains several reasons why the same prompt might generate different responses for different users or at different times.
The variability of an AI assistant
There are multiple reasons why two users might not get the same response even though they submit the same prompt:
- Generative AI models incorporate randomness into their algorithms. Consequently, the same input might produce different outputs at different times. This is done to provide variety and mimic a human-like response.
- Generative AI uses the entire conversation to generate responses. The answer to a prompt is influenced by previous prompts and answers in the conversation.
- Your preferences are incorporated in the response. This fact is familiar to people who have used the Microsoft Copilot interface, where you can set a "conversation style" such as "more creative", "more balanced", or "more precise." This style setting sets parameters that the Copilot uses to formulate its responses.
- Your prompt might have different correct answers. For example, suppose you ask, "What are some popular boy names?" Surely, that answer varies from country to country and from year to year. If you ask that question from a domain in the US, you might get names such as Liam, Noah, Oliver, and James. However, from a domain in India, you might get the answers that include Arjun, Vihaan, Kabir, and Reyansh.
For factual and unambiguous questions, you might receive very similar or identical response every time you ask the question. However, even in that situation, the presentation of the response can vary. The Google Gemini AI has a nice interface where you can see three "drafts" that Gemini composed in response to the prompt. Each is slightly different. You can choose one of those three prompts or click on a button that will generate additional responses.
These ideas also apply to prompts that generate programs. Even for a simple programming query, there are often several correct answers, as shown in the next section.
Variation in programming responses
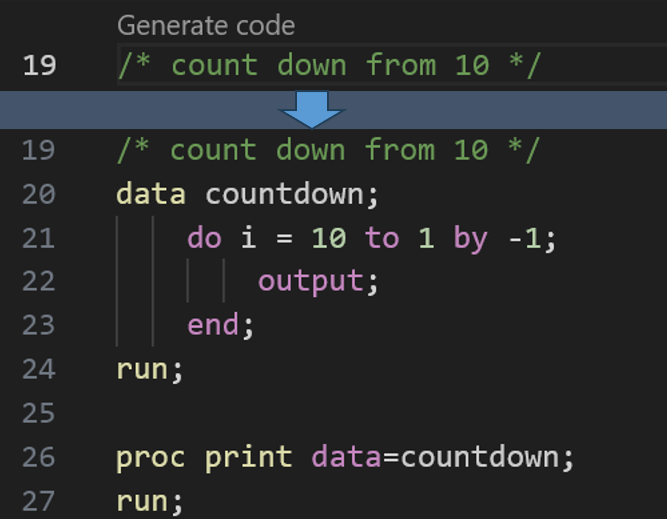
Let's suppose you give the following prompt to an AI assistant: "Write a SAS program that counts down from 10."
How would you write this program? Most likely, you would write a DATA step that uses a DO loop and a BY keyword, as follows:
data countdown1; do i = 10 to 1 by -1; output; end; run; |
If I were teaching a course on SAS programming and a student gave this response, I would give it full marks. But suppose another student provides a different response, as follows:
data countdown2; i = 10; do while (i >= 1); output; i = i - 1; end; run; |
This second program produces the same output as the first, but it uses a DO-WHILE statement. If a student gave this response, I would also give it full marks, although I feel that the first program is easier to read than the second programmer. In addition, a program that uses a DO-WHILE syntax can often be rewritten to use a DO-UNTIL syntax:
data countdown3(keep=count); count = 10; do until (count < 1); output; count = count - 1; end; run; |
All three of these programs were written by SAS Viya Copilot (except I changed the data set names to make them unique). All are correct. Usually, the Copilot chooses the first response, which is the simplest. Usually, the looping variable is named 'i', but in the third example the Copilot used 'count' as the variable name. Each program is correct, yet the programs are different.
How should you think about this kind of variation? I like to compare the Copilot response to an internet search. If you use Google or another search engine and search for "SAS program count down from 10", you will get thousands of hits. Some of them provide an answer, others are "false positives" that are related to the search keywords but do not actually discuss how to count down in SAS. Among the thousands of hits, most of the program-related responses discuss the DO loop with a negative value for the BY keyword. A few discuss the DO-WHILE loop or the DO-UNTIL loop.
This is representative of the data on which that the AI assistants are initially trained. They learn to formulate a response based on many examples. If most of the training examples use a DO loop, but a nontrivial proportion use a DO-WHILE or DO-UNTIL loop, you should expect the AI assistant to generate responses that are similar to the training data. Most responses will use a DO loop, but a few might use a DO-WHILE or DO-UNTIL loop.
Interestingly, if you perform the Google search that I suggested, the number one answer is actually not any of the DO loop programs, but a SAS Communities article that discusses a macro loop! So, that is yet another possible response.
Steering the Copilot towards a desired answer
Among the many "correct" answers, there might be one that you prefer. If so, how can you direct the Copilot towards your preferred response? There are basically two options:
- Think of all the possible ways that the Copilot could respond, then add constraints to your prompt so that the Copilot produces the answer you prefer. For example, to encourage the Copilot to produce a DO loop with a BY clause (the first program), you could submit a prompt such as "Write a SAS program that counts down from 10. Put the results in a data set. Do not use a WHILE or UNTIL clause." Adding constraints can be difficult because you do not know in advance all possible Copilot responses.
- Start with a general response, then follow up with additional prompts until the result is acceptable. This is usually the easier method. For example, the first prompt is "Write a SAS program that counts down from 10." If the Copilot generates a SAS macro that displays text to the log, you can follow up with a new prompt, "Do not show me a macro loop. Write the results to a data set." Similarly, if the Copilot uses a DO-WHILE loop, you can follow up with a new prompt, "Write a different program that does not use a WHILE clause."
Summary
This article discusses the issue of reproducibility for responses by an AI assistant such as SAS Viya Copilot. In general, you should not expect an AI assistant to always give the same response to the same prompt. Generative AI models incorporate randomness into their algorithms. They also use previous prompts and answers to generate a response. Furthermore, some prompts have multiple correct answers as seen by the example of a SAS program that counts down from 10. You can steer the Copilot towards a desired response by adding additional constraints to your prompt, such as "please use <feature>" or "do not use <feature>".

2 Comments
Very interesting. I did not know about randomness deliberately inserted into AI responses.
Pingback: Display the largest values for each group - The DO Loop