A common question on SAS discussion forums is how to randomly assign observations to groups. An application of this problem is assigning patients to cohorts in a clinical trial. For example, you might have 137 patients that you want to randomly assign to three groups: a control group, a group that gets an established treatment, and a group that gets a new treatment. Random assignment tends to produce groups in which patients who have confounding factors (obesity, high blood pressure, and other pre-existing conditions) are distributed equally across the groups.
There are many ways to perform a random assignment in SAS, including the DATA step and PROC PLAN. However, my favorite procedure for random assignment is to use the GROUPS= option in PROC SURVEYSELECT. This article shows three ways to assign subjects to groups:
- Assign the subjects as evenly as possible to G groups.
- Assign the subjects within each stratum as evenly as possible to G groups.
- Assign the subjects to groups by using a specified list of sample sizes.
Distribute subjects equally among groups
In the simplest situation, you want to randomly assign N subjects to G groups so that the group sizes are as equal as possible. If G divides N, you can make the groups equal in size. Otherwise, one or more groups will have one more subject than the others.
Suppose that you have N=137 patients to assign to G=3 groups. Because 137 is a prime number, the groups cannot be equal. The following DATA step extracts 137 patients from the Sashelp.Heart data set. The call to PROC SURVEYSELECT uses the GROUP=3 option to randomly assign the patients to three groups. The output data set contains a new indicator variable that is named GroupID and has the values 1, 2, or 3. The call to PROC FREQ shows that the subjects are (nearly) equally divided among the three groups:
/* Extract 137 patients from the Sashelp.Heart dat set */ data Have; ID + 1; set Sashelp.Heart(obs=137); keep ID Sex Height Weight Diastolic Systolic Cholesterol; run; /* SAS/STAT 13.1 : use GROUPS= option */ /* See https://support.sas.com/kb/36/383.html */ proc surveyselect data=Have noprint seed=12345 out=Cohorts groups=3; run; proc freq data=Cohorts; table GroupID / nocum; /* count how many subjects in each group */ run; |
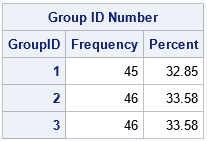
The output shows that each group contains approximately 33% of the subjects. Forty-five subjects are assigned to the first group and 46 subjects are assigned to the second and third groups. When the number of groups does not evenly divide the number of subjects, the first groups have fewer subjects than the last groups.
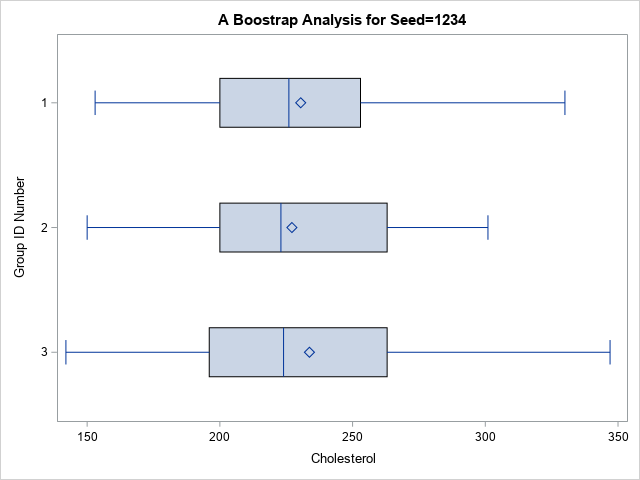
As stated earlier, a benefit of random assignment is that covariate values have nearly identical distributions in each group. For example, the following statements create a box plot of the Cholesterol variable. The distribution of Cholesterol values seems to be similar in the three groups.
proc sgplot data=Cohorts; hbox Cholesterol / category=GroupID; run; |
Distribute subjects within strata equally among groups
Sometimes the subjects have additional categorical characteristics such as Sex or Race. You might want to randomly assign subjects within each category. For example, these data contain 86 females and 51 males. The following call to PROC SURVEYSELECT uses the STRATA statement to separately assign the females to three groups (sizes are 28, 29, and 29) and the males to three groups (sizes are 17). To use the STRATA statement, you need to sort the data by the Sex variable, as follows:
/* random assignment within strata */ proc sort data=Have; by Sex; run; proc surveyselect data=Have noprint seed=12345 out=Cohorts groups=3; strata Sex; run; proc freq data=Cohorts; table Sex*GroupID / nocum nocol nopercent; run; |
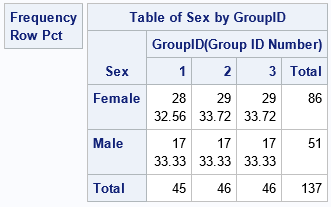
The output from PROC FREQ shows that the random assignment is as even as possible within the males and within the females, separately, with about 33% of each gender in each group.
Assign subjects unequally to groups
In some situations, you might not want an equal number of subjects in each group. For example, you might want to assign fewer subjects to the control group and more to the experimental groups. The GROUP= option supports a list of sample sizes. The following call to PROC SURVEYSELECT randomly assigns 40 subjects to each of the first two groups and 57 subjects to the third group:
/* You can also specify the groups sizes */ proc surveyselect data=Have noprint seed=12345 out=CohortSize groups=(40 40 57); run; proc freq data=CohortSize; table GroupID / nocum; run; |
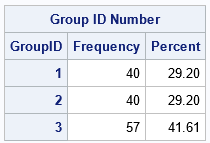
The output from PROC FREQ verifies that the sample sizes for the three groups are as specified on the GROUP= list.
Summary
This article shows that it is easy to use PROC SURVEYSELECT to carry out a random assignment of subjects to groups. This article shows three examples:
- Random assignment (evenly) to G groups.
- Random assignment within each stratum (evenly) to G groups.
- Random assignment to G groups when you want to specify the size of each group.
Further reading
- Use the DATA step or PROC SURVEYSELECT to split data into three data sets: Training, testing, and validation.
- Use PROC SURVEYSELECT to assign unique random IDs to subjects.
- Use the OPTEX procedure to assign subjects to groups so that the mean or variance of a covariate is as equal as possible across groups.
- SAS Usage Note 36383: Randomly assign the observations in a data set to two or more groups shows how to randomly assign observations to groups if you are using SAS 9.3. It also shows how to use PROC PLAN to pre-assign subjects when the total number of subjects is unknown.

2 Comments
Nice entry, Rick. Another common task is block randomization. This is similar to a stratified randomization, but not identical. Often in settings where block randomization is needed, the assignments are made sequentially. To prevent the study administrators inferring the assignment of the last experimental unit(s) in a block, the first N unit(s) in the block will be discarded. Is this something you can get SURVEYSELECT to do directly, or will it take a combination of data steps and with the procedure?
I don't have expertise in block randomization. My first thought would be to look at PROC PLAN.
I discussed this with a colleague. We think that "assignments are made sequentially" refers to the investigator applying the block randomization assignments to subjects. When the block size is fixed (with fixed treatment/placebo allocation) and the process is non-blinded, then the investigator will know what the final assignment(s) in the block will be. I think this concern is sometimes addressed by using a blinded process or varying block sizes.
I don't think Ken's comment refers to a sequential selection method (e.g., Chromy's method).
PROC SURVEYSELECT does not provide an option with GROUPS= to discard the first N units/assignments in each block (stratum or replicate). But you could do this in a separate DATA step.