In a previous blog post, I discussed ways to produce statistically independent samples from a random number generator (RNG). The best way is to generate all samples from one stream. However, if your program uses two or more SAS DATA steps to simulate the data, you cannot use the same seed value multiple times because that could introduce biases into your study. An easy way to deal with this situation is to use the CALL STREAM subroutine to set different key values for each DATA step.
An example of using two DATA steps to generate random numbers
Suppose that you have a simulation that needs to call the DATA step twice, and each call generates random numbers. If you want to encapsulate that functionality into a macro call, you might want to pass in the seed for the random number streams. An INCORRECT approach is to do the following:
%macro DoItWRONG(seed=); data A; call streaminit('PCG', &seed); /* ... do something with random numbers ... */ run; data B; call streaminit('PCG', &seed); /* <== uh-oh! Problem here! */ /* ... do something else with random numbers ... */ run; %mend; |
This code is unacceptable because the same seed value and RNG are used for both DATA steps. That means that the stream of random numbers is the same for the second DATA step as for the first, which can lead to correlations that can bias your study.
Prior to SAS 9.4M5, the only way to resolve this issue was to use different seed values for each DATA step. For example, you could use &seed + 1 in the second DATA step.
Because the Mersenne twister RNG (the only RNG in SAS prior to 9.4M5) has an astronomically large period, streams that use different seed values have an extremely small probability of overlapping.
Use the CALL STREAM subroutine
SAS 9.4M5 introduced new random number generators. The Mersenne twister algorithm supports one parameter (the seed) which initializes each stream. The Threefry and PCG algorithms support two initialization parameters. To prevent confusion, the first parameter is called the seed value and the second is called the key value. By default, the key value is zero, but you can use the CALL STREAM subroutine to set a positive key value.
You should use the key value (not the seed value) to generate independent streams in two DATA steps. The following statements are true:
- The PCG generator is not guaranteed to generate independent streams for different seed values. However, you can use the key value to ensure independent streams. Two streams with the same seed and different key values never overlap.
- The Threefry generators (TF2 and TF4) generate independent streams for different seed values. However, the Threefry generators also accept key values, and two streams with different key values never overlap.
- The Mersenne twister algorithm does not inherently support a key value. However, the STREAM routine creates a new seed from the current seed and the specified key value. Because of the long-period property of the MT algorithm, two streams that use the same seed and different key values are "independent with high probability."
The following example modifies the previous macro to use the CALL stream routine. For the PCG RNG, two streams that have the same seed and different key values do not overlap:
%macro DoIt(seed=); data A; call streaminit('PCG', &seed); call stream(1); /* ... do something with random numbers ... */ run; data B; call streaminit('PCG', &seed); call stream(2); /* <== different stream, guaranteed */ /* ... do something else with random numbers ... */ run; %mend; |
Of course, this situation generalizes. If the macro uses three (or 10 or 20) DATA steps, each of which generates random numbers, you can use a different key value in each DATA step. If you initialize each DATA step with the same seed and a different key, the DATA steps generate independent streams (for the Threefry and PCG RNGs) or generate independent streams with high probability (for the Mersenne twister RNG).
A real example of using different streams
This section provides a real-life example of using the CALL STREAM subroutine. Suppose a researcher wants to create a macro that simulates many samples for a regression model. The macro first creates a data set that contains p independent continuous variables. The macro then simulates B response variables for a regression model that uses the independent variables from the first data set.
To prevent the second DATA step from using the same random number stream that was used in the first DATA step, the second DATA step calls the STREAM subroutine to set a key value:
%macro Simulate(seed=, N=, NCont=, /* params for indep vars */ key=, betas=, /* params for dep vars */ NumSamples=); /* params for MC simul */ /* Step 1: Generate nCont explanatory variables */ data MakeData; call streaminit('PCG', &seed); /* if you do not call STREAM, you get the stream for key=0 */ array x[&NCont]; /* explanatory vars are named x1-x&nCont */ do ObsNum = 1 to &N; /* for each observation in the sample */ do j = 1 to &NCont; x[j] = rand("Normal"); /* simulate NCont explanatory variables */ end; output; end; keep ObsNum x:; run; /* Step 2: Generate NumSamples responses, each from the same regression model Y = X*beta + epsilon, where epsilon ~ N(0, 0.1) */ data SimResponse; call streaminit('PCG', &seed); call stream(&key); keep SampleId ObsNum x: Y; /* define regression coefficients beta[0], beta[1], beta[2], ... */ array beta[0:&NCont] _temporary_ (&betas); /* construct linear model eta = beta[0] + beta[1]*x1 + betat[2]*x2 + ... */ set MakeData; /* for each obs in data ...*/ array x[&nCont] x1-x&NCont; /* put the explanatory variables into an array */ eta = beta[0]; do i = 1 to &NCont; eta = eta + beta[i] * x[i]; end; /* add random noise for each obs in each sample */ do SampleID = 1 to &NumSamples; Y = eta + rand("Normal", 0, 0.1); output; end; run; /* sort to prepare data for BY-group analysis */ proc sort data=SimResponse; by SampleId ObsNum; run; %mend; |
For a discussion of how the simulation works, see the article "Simulate many samples from a linear regression model." In this example, the macro uses two DATA steps to simulate the regression data. The second DATA step uses the STREAM subroutine to ensure that the random numbers it generates are different from those used in the first DATA step.
For completeness, here's how you can call the macro to generate the data and then a call PROC REG with a BY statement to analyze the 1,000 regression models.
%Simulate(seed=123, N=50, NCont=3, /* params for indep vars */ key=1, Betas = 1 -0.5 0.5 -0.25, /* params for dep vars */ NumSamples=1000) /* params for MC sim */ proc reg data=SimResponse noprint outest=PE; by SampleID; model Y = x1-x3; run; title "Parameter Estimates for key=1"; proc print data=PE(obs=5) noobs; var SampleID Intercept x1-x3; run; |
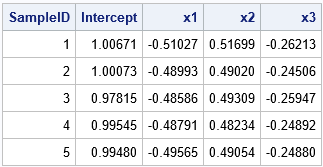
You can verify that the macro generates different simulated data if you use the same seed value but change the key value in the macro call.
In summary, this article shows that you can use the STREAM call in the SAS DATA step to generate different random number streams from the same seed value. For many simulation studies, the STREAM subroutine is not necessary. However, it useful when the simulation is run in stages or is implemented in modules that need to run independently.
