My article about the difference between CLASS variables and BY variables in SAS focused on SAS analytical procedures. However, the BY statement is also useful in the SAS DATA step where it is used to merge data sets and to analyze data at the group level. When you use the BY statement in the DATA step, the DATA step creates two temporary indicator variables for each variable in the BY statement. The names of these variables are FIRST.variable and LAST.variable, where variable is the name of a variable in the BY statement. For example, if you use the statement BY Sex, then the names of the indicator variables are FIRST.Sex and LAST.Sex.
This article gives several examples of using the FIRST.variable and LAST.variable indicator variables for BY-group analysis in the SAS DATA step. The first example shows how to compute counts and cumulative amounts for each BY group. The second example shows how to compute the time between the first and last visit of a patient to a clinic, as well as the change in a measured quantity between the first and last visit. BY-group processing in the DATA step is a fundamental operation that belongs in every SAS programmer's tool box.
Use FIRST. and LAST. variables to find count the size of groups
The first example uses data from the Sashelp.Heart data set, which contains data for 5,209 patients in a medical study of heart disease. The data are distributed with SAS. The following DATA step extracts the Smoking_Status and Weight variables and sorts the data by the Smoking_Status variable:
proc sort data=Sashelp.Heart(keep=Smoking_Status Weight) out=Heart; by Smoking_Status; run; |
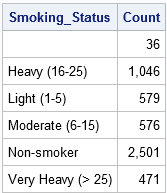
Because the data are sorted by the Smoking_Status variable, you can use the FIRST.Smoking_Status and LAST.Smoking_Status temporary variables to count the number of observations in each level of the Smoking_Status variable. (PROC FREQ computes the same information, but does not require sorted data.) When you use the BY Smoking_Status statement, the DATA step automatically creates the FIRST.Smoking_Status and LAST.Smoking_Status indicator variables. As its name implies, the FIRST.Smoking_Status variable has the value 1 for the first observation in each BY group and the value 0 otherwise. (More correctly, the value is 1 for the first record and for records for which the Smoking_Status variable is different than it was for the previous record.) Similarly, the LAST.Smoking_Status indicator variable has the value 1 for the last observation in each BY group and 0 otherwise.
The following DATA step defines a variable named Count and initializes Count=0 at the beginning of each BY group. For every observation in the BY group, the Count variable is incremented by 1. When the last record in each BY group is read, that record is written to the Count data set.
data Count; set Heart; /* data are sorted by Smoking_Status */ BY Smoking_Status; /* automatically creates indicator vars */ if FIRST.Smoking_Status then Count = 0; /* initialize Count at beginning of each BY group */ Count + 1; /* increment Count for each record */ if LAST.Smoking_Status; /* output only the last record of each BY group */ run; proc print data=Count noobs; format Count comma10.; var Smoking_Status Count; run; |
The same technique enables you to accumulate values of a variable within a group. For example, you can accumulate the total weight of all patients in each smoking group by using the following statements:
if FIRST.Smoking_Status then cumWt = 0; cumWt + Weight; |
This same technique can be used to accumulate revenue from various sources, such as departments, stores, or regions.
Use FIRST. and LAST. variables to compute duration of treatment
Another common use of the FIRST.variable and LAST.variable indicator variables is to determine the length of time between a patient's first visit and his last visit. Consider the following DATA step, which defines the dates and weights for four male patients who visited a clinic as part of a weight-loss program:
data Patients; informat Date date7.; format Date date7. PatientID Z4.; input PatientID Date Weight @@; datalines; 1021 04Jan16 302 1042 06Jan16 285 1053 07Jan16 325 1063 11Jan16 291 1053 01Feb16 299 1021 01Feb16 288 1063 09Feb16 283 1042 16Feb16 279 1021 07Mar16 280 1063 09Mar16 272 1042 28Mar16 272 1021 04Apr16 273 1063 20Apr16 270 1053 28Apr16 289 1053 13May16 295 1063 31May16 269 ; |
For these data, you can sort by the patient ID and by the date of visit. After sorting, the first record for each patient contains the first visit to the clinic and the last record contains the last visit. You can subtract the patient's weight for these dates to determine how much the patient gained or lost during the trial. You can also use the INTCK function to compute the elapsed time between visits. If you want to measure time in days, you can simply subtract the dates, but the INTCK function enables you to compute duration in terms of years, months, weeks, and other time units.
proc sort data=Patients; by PatientID Date; run; data weightLoss; set Patients; BY PatientID; retain startDate startWeight; /* RETAIN the starting values */ if FIRST.PatientID then do; startDate = Date; startWeight = Weight; /* remember the initial values */ end; if LAST.PatientID then do; endDate = Date; endWeight = Weight; elapsedDays = intck('day', startDate, endDate); /* elapsed time (in days) */ weightLoss = startWeight - endWeight; /* weight loss */ AvgWeightLoss = weightLoss / elapsedDays; /* average weight loss per day */ output; /* output only the last record in each group */ end; run; proc print noobs; var PatientID elapsedDays startWeight endWeight weightLoss AvgWeightLoss; run; |
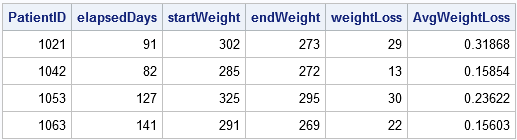
The output data set summarizes each patient's activities at the clinic, including his average weight loss and the duration of his treatment.
Some programmers think that the FIRST.variable and LAST.variable indicator variables require that the data be sorted, but that is not true. The temporary variables are created whenever you use a BY statement in a DATA step. You can use the NOTSORTED option on the BY statement to process records regardless of the sort order.
Summary
In summary, the BY statement in the DATA step automatically creates two indicator variables. You can use the variables to determine the first and last record in each BY group. Typically the FIRST.variable indicator is used to initialize summary statistics and to remember the initial values of measurement. The LAST.variable indicator is used to output the result of the computations, which often includes simple descriptive statistics such as a sum, difference, maximum, minimum, or average values.
BY-group processing in the DATA step is a common topic that is presented at SAS conferences. Some authors use FIRST.BY and LAST.BY as the name of the indicator variables. For further reading, I recommend the paper "The Power of the BY Statement" (Choate and Dunn, 2007). SAS also provides several samples about BY-group processing in the SAS DATA step, including the following:
- Carry non-missing values down a BY-Group
- Use BY groups to transpose data from long to wide
- Select a specified number of observations from the top of each BY-Group
WANT MORE GREAT INSIGHTS MONTHLY? | SUBSCRIBE TO THE SAS TECH REPORT

8 Comments
The first.variable/last.variable IMHO ranks up there with transposing as features that show off the power of SAS for data preparation.
Another source for details on this is the documentation section "By-Group Processing in SAS Programs".
Good to know. This will help eliminate the duplicates in SAS data sets where it does matter which observation is kept and which ones are discarded.
I've a dataset like;
Height Patid
. 1
56 1
56 1
56 1
56 1
56 2
45 2
45 2
45 2
45 2
45 3
So How can I retain missing value to no 56 and 56 is not included in Patid =2
And output dataset like
Height Patid
56 1
56 1
56 1
56 1
56 1
45 2
45 2
45 2
45 2
45 2
Please solve this one..
You can ask programming questions like this at the SAS Support Communities.
data a;
input Height Patid;
datalines;
. 1
56 1
56 1
56 1
56 1
56 2
45 2
45 2
45 2
45 2
45 3
;
run;
data ab;
set a;
if height;
run;
very good article. I was trying to copy your logic, but stuck on one problem. if you want to limit your list with IN operator, so count the smoking status only for selected patients and for others not, and to have it one report, how to change this code? pls advise.
In general, the SAS Support Communities are the best place to ask programming questions. To answer your question, put a WHERE clause in the PROC SORT statement to filter out the patients that you do not want to analyze.
Pingback: Display the largest values for each group - The DO Loop