I recently needed to solve a fun programming problem. I challenge other SAS programmers to solve it, too! The problem is easy to state: Given a long sequence of digits, can you write a program to count how many times a particular subsequence occurs? For example, if I give you a sequence of 1,000 digits, can you determine whether the five-digit pattern {1 2 3 4 5} appears somewhere as a subsequence? How many times does it appear?
If the sequence is stored in a data set with one digit in each row, then SAS DATA step programmers might suspect that the LAG function will be useful for solving this problem. The LAG function enables a DATA step to examine the values of several digits simultaneously.
The SAS/IML language also has a LAG function which enables you to form a matrix of lagged values. This leads to an interesting way use vectorized computations to solve this problem. The following SAS/IML program defines a small eight-digit set of numbers in which the pattern {1 2 3} appears twice. The LAG function in SAS/IML accepts a vector of lags and creates a matrix where each column is a lagged version of the input sequence:
/* Find a certain pattern in sequence of digits */ proc iml; Digit = {1,1,2,3,3,1,2,3}; /* digits to search */ target = {1 2 3}; /* the pattern to find */ p = ncol(target); /* length of target sequence */ D = lag(Digit, (p-1):0); /* columns shift the digits */ print D; |
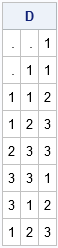
The output shows a three-column matrix (D) that contains the second, first, and zeroth lag (in that order) for the input sequence. Notice that if I am searching for a particular three-digit pattern, this matrix is very useful. The rows of this matrix are all three-digit patterns that appear in the original sequence. Consequently, to search for a three-digit pattern, I can use the rows of the matrix D.
To make the task easier, you can delete the first two rows, which contain missing values. You can also form a binary matrix X that has the value X[i,j]=1 when the j_th element of the pattern equals the j_th element of the i_th row, and 0 otherwise, as shown in the following:
D = D[p:nrow(Digit),]; /* delete first p rows */ X = (D=target); /* binary matrix */ print X; |
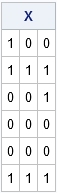
Notice that in SAS/IML, the comparison operator (=) can perform a vector comparison. The binary comparison operator detects that the matrix on the left (D) and the vector on the right (target) both contain three columns. Therefore the operator creates the three-column logical matrix X, as shown. The X matrix has a wonderful property: a row of X contains all 1s if and only if the corresponding row of D matches the target pattern. So to find matches, you just need to sum the values in the rows of X. If the row sum equals the number of digits in the pattern, then that row indicates a place where the target pattern appears in the original sequence.
You can program this test in PROC IML as follows. The subscript reduction operator [,+] is shorthand for "compute the sum of each row over all columns".
/* sum across columns. Which rows contain all 1s? */ b = (X[,+] = p); /* b[i]=1 if i_th row matches target */ NumRepl = sum(b); /* how many times does target appear? */ if NumRepl=0 then print "The target does not appear in the digits"; else print "The target appears at location " (loc(b)[1]), /* print 1st location */ "The target appears" (NumRepl) "times."; |

The program discovered that the target pattern appears in the sequence twice. The first appearance begins with the second digit in the sequence. The pattern also appears in the sequence at the sixth position, although that information is not printed.
Notice that you can solve this problem in SAS/IML without writing any loops. Instead, you can use the LAG function to convert the N-digit sequence into a matrix with N-p rows and p columns. You can then test whether the target pattern matches one of the rows.
Your turn! Can you solve this problem?
Now that I have shown one way to solve the problem, I invite SAS programmers to write their own program to determine whether a specified pattern appears in a numeric sequence. You can use the DATA step, DS2, SQL, or any other SAS language.
Post a comment to submit your best SAS program. Extra points for programs that count all occurrences of the pattern and display the location of the first occurrence.
To help you debug your program, here is test data that we can all use. It contains 10 million random digits:
data Have(keep=Digit); call streaminit(31488); do i = 1 to 1e7; Digit = floor(10*rand("uniform")); output; end; run; |
To help you determine if your program is correct, you can use the following results. In this sequence of digits:
- The five-digit pattern {1 2 3 4 5} occurs 101 times and the first appearance begins at row 34417
- The six-digit patter {6 5 4 3 2 1} occurs 15 times and the first appearance begins at row 120920
You can verify these facts by using PROC PRINT as follows:
proc print data=Have(firstobs=34417 obs=34421); run; proc print data=Have(firstobs=120920 obs=120925); run; |
Happy programming!

23 Comments
I am the first one.
Nifty post, Rick. Here's a brute force approach that builds every string....
Clever! I like how you use SUBSTRN and CAT to avoid using LAG.
can do better
no need for substrN() or lag
(see my 6 statement solution, later)
Quentin's code is not efficient due to turn digit into character.
I would use QUEUE skill.
I love your solution - I just learned now that a temporary array retains its values, thanks!
Third. Learned this merge "trick" far back in the 90s.
Nice way to build lagged columns. You could also construct "word" columns like
w5 = d1*10000+d2*1000+d3*100+d4*10+d5;
w6 = d1*100000+d2*10000+d3*1000+d4*100+10*d5+d6;
and then DROP d1-d6 if you wanted a smaller data set.
I tried the following but I am not getting the totals. I do not have data step debugger to dig into it. However I guess that my idea will work faster. I appreciate if you can point to my mistake.
I missed the successive ones in my earlier algorithm. The following does.
Yes, your idea does work fast.
I like it for it simplicity and because it just do a one scan of the data file, which could be sometimes very very big, these days.
With a little help from SAS macros, your code could be like this
Pingback: Find your birthday in the digits of pi - The DO Loop
I immediately thought of using a data step merge operation as employed by Eric. His solution is efficient for the problem specified. But I generally dislike the idea of displaying just the first occurrence of an event when there is a reasonably finite list of outcomes of interest. What constitutes a reasonably finite set may be open to question. Without looking at results you posted for the sequence {1 2 3 4 5}, I estimated the number of occurrences as {number of sequences} * {probability of sequence pattern). The number of sequences is 10**7 while the probability of a sequence of 5 digits chosen at random would be 10**(-5). So, we would expect 100 occurrences of {1 2 3 4 5}. With probability 99.9%, the number of 5 digit sequences would be at most 130. Still seems like a finite number to me. With virtually complete certainty, there would be no more than 150 instances found. Enumerating all locations (up to 150 locations) has appeal to me.
Thus, for EXTRA extra credit, I added a temporary array to store locations of each occurrence of the sequence {1 2 3 4 5} (up to 150 occurrences). All locations are then returned.
Thank you, Rick, for posting this challenging brain exercise. Here is my solution. No lags, no merges, no hard-coded logic. Just assign your pattern value to a macro variable called pattern and run. The output dataset have1 will have number of observations equal to the number of pattern occurrences, each observation will have the occurrence position. Here it goes:
Lovely, nice and compact.
Let me know what you guys think of this approach.
I just want to put in a vote in favor of Leonid Batkhan's solution. I probably would have read in the "matching strings" from a dataset as well rather than using macro variables for each pattern I was searching for, but overall I find that a very elegant solution. One of course could just keep the first and last observations of the output dataset if all you want to know is the first and last locations; one could also keep track of the count and output it. I would wager that it's fast, too, and of course requires minimal storage. Nicely done!
sorry to be sooo slow in taking the opportunity
and apparently repeating a part of Dale's solution - but with even more brevity
and here is the code
surprised by how much my brief solution (code-wise) is slower than Keshan's (on March 10, 2017 11:35 pm)
7¼ secs for my 6 statement CATS() based solution against the Keshan's array-shuffle loop which took 1½secs on the same machine
In future I shall be more careful about making those data-type conversions
Hi All, I love all the solutions here, it shows that how flexible SAS is to accommodate many different approaches to a problem. At first, my program was specific to the sequence 12345 then I modified it into the following macro so any sequence of numbers of any length could be found.
So this is my very first DS2 program, just for fun ;-))) Thanks Rick.
The algorithm is based on muthia kachirayan's
I'm looking for a code in an excel file that will predict the most probable " digit " to come next ? If my string belong is in cells A1:A100.
Example data :
1123133123314212353346233233333243222331232233336113211523133331323142321113151333223126332213522556 next is 3 can a code work finding the 3 after the 100 string digits ?
Thank you in advance.
Serge,
Tabulate the frequencies of the digits. The one that occurs the most is the most probable. In your example, 3 occurs 40 times, which is more than any other digits 1-6. Good luck.