Suppose that you have two data vectors, x and y, with the same number of elements. How can you rearrange the values of y so that they have the same relative order as the values of x? In other words, find a permutation, π, of the elements of y so that rank(π(y))=rank(x).
Stop reading here if you want to think about this problem before I provide the answer.
Permuting elements to achieve a target order
Although I've described the problem as it was originally presented to me, the x vector is not needed to solve this problem. Given the x data vector, let R=rank(x). The vector R is a permutation of the integers {1,2,...,N}, where N is the number of elements. The problem is to permute the elements of y so that rank(π(y))=R.
It turns out that the solution to this problem is easy. Notice that if the elements of y are in sorted order, then R provides the necessary permutation for y. Consequently, you can solve this problem in two steps: sort the elements of y and then use R to permute the sorted elements. The rank of a vector is computed in SAS/IML software by using the RANK function. This is shown in the following example:
proc iml;
/* Given R, find z, a permutation of y, so that rank(z)=R */
/* Example: x = {0.2, 1, 0.4, 0.3, 1.1, 0.1}; R = rank(x); */
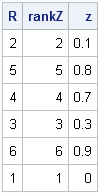
R = {2, 5, 4, 3, 6, 1}; /* target ranking */
y = {0.3, 0.8, 0.7, 0.9, 0.1, 0};
call sort(y); /* use sort(y,1) prior to SAS/IML 9.22 */
z = y[R]; /* reorder elements of y. Call result z */
rankZ = rank(z);
print R rankZ z; |
What if Y has duplicate values?
Notice that the algorithm uses the RANK function. If y has unique values, rank(y) is unique. However, if y has duplicate values, then tied values are assigned ranks arbitrarily. (See the documentation for the RANKTIE function for other possibilities.)
Consequently, if there are duplicate values in y, there are several possible permutations that result in an equivalent ordering for y, and the algorithm finds one of the valid permutations. For example, in the following example y has two pairs of duplicate values:
/* what if there are duplicates (ties) in y? */
y = {0.3, 0.8, 0.8, 0.9, 0, 0};
call sort(y);
z = y[R];
rankZ2 = rank(z);
print R rankZ2 z; |
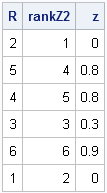
At first glance, it looks like rank(z) does not equal R. However, notice that the first and last elements of z are the same, and the second and third elements are also the same. Therefore you can exchange those elements—and the corresponding ranks—without changing z.
I'm happy to use the solution that I've described, but if it bothers you that rank(z) might not equal R, there is a sneaky way to resolve the issue: add a tiny amount of random noise to the y data. The jittered data will not have duplicate values, and so there is a unique solution to the jittered problem. I leave the details to the motivated reader.
