Imagine the following scenario. You have many data sets from various sources, such as individual stores or hospitals. You use the SAS DATA step to concatenate the many data sets into a single large data set. You give the big data set to a colleague who will analyze it. Later that day, he comes back and says "One of these observations is very interesting. Can you tell me which of the original data sets this observation came from?"
There's a simple way to generate the answer this question. When you use the SET option to concatenate the data sources, use the INDSNAME= option on the SET statement. The INDSNAME= option was introduced back in the SAS 9.2 days, but it is not as well-known as it should be, considering how useful it is.
Recording the name of a data source
Let's create some example data. The following SAS macro code creates 10 SAS data sets that each have a variable called X. A subsequent DATA step uses the SET statement to vertically concatenate the 10 data sets into a single data set:
%macro CreateDS; %do i = 0 %to 9; data A&i; x = &i; run; %end; %mend; %CreateDS; /* create data sets A0, A1, A2, ..., A9 */ data Combined; /* concatenate into a single data set */ set A0-A9; run; |
The Combined data set has 10 observations, one from each of the original data sets. However, there is no variable that indicates which observation came from which of the original data sets.
Longtime SAS programmers are undoubtedly familiar with the IN= data set option. You can put the IN= option inside parentheses after each data set name. It provides a (temporary) flag variable that you can use during the DATA step. For example, the following DATA step creates a variable named SOURCE that contains the name of the source data set, but (yuck!) it uses zillions of IF-THEN statements:
/* create SOURCE variable: Using the IN= option is long and tedious */ data Combined; set A0(in = ds0) A1(in = ds1) A2(in = ds2) A3(in = ds3) A4(in = ds4) A5(in = ds5) A6(in = ds6) A7(in = ds7) A8(in = ds8) A9(in = ds9); if ds0 then source = "A0"; else if ds1 then source = "A1"; else if ds2 then source = "A2"; else if ds3 then source = "A3"; else if ds4 then source = "A4"; else if ds5 then source = "A5"; else if ds6 then source = "A6"; else if ds7 then source = "A7"; else if ds8 then source = "A8"; else if ds9 then source = "A9"; run; proc print data=Combined; run; |
An easier way: Use the INDSNAME= option
The IN= data set option gets the job done, but for this task it is messy and unwieldy. Fortunately, there is an easier way. You can use the INDSNAME= option on the SET statement to create a temporary variable that contains the name of the source data set. You can then use the SCAN function to extract the libref and data set name to permanent variables, as follows:
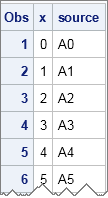
/* create SOURCE variable: Using the INDSNAME= option is quick and easy */ data Combined2; set A0-A9 indsname = source; /* the INDSNAME= option is on the SET statement */ libref = scan(source,1,'.'); /* extract the libref */ dsname = scan(source,2,'.'); /* extract the data set name */ run; proc print data=Combined2; run; |

Success! Now the source for each observation is clearly indicated.
For an additional example, see the SAS Sample "Obtain the name of data set being read with SET statement with INDSNAME= option." For more cool DATA step features, see the paper "New in SAS 9.2: It’s the Little Things That Count" (Olson, 2008).

13 Comments
What a gem of an option! Thanks for sharing Rick.
I'm curious as to why the default length of the variable is 41 bytes if not previously defined... why 41? Although it is close to 42... ;-)
Thanks,
Michelle
In SAS, a libref can be 8 characters long and a data set name can be 32 characters long. Add one character for the dot ('.') and you get 41 characters.
Ahhh of course... simple maths!
This will come in handy. Thanks for the tip, Rick
I have also posted this question in SAS forum, but since your blog gets so much attention I thought it might be good to post it here as well. I get temp datasets 'sometimes' when using this feature:
NOTE: There were 456 observations read from the data set WORK.AVERAGE_LT700.
NOTE: There were 480 observations read from the data set WORK.AVERAGE_LT700_PREP.
NOTE: There were 480 observations read from the data set WORK.AVERAGE_LT700_PREP_TWO.
NOTE: There were 456 observations read from the data set WORK.AVERAGE_700_800.
NOTE: There were 480 observations read from the data set WORK.AVERAGE_700_800_PREP.
NOTE: There were 480 observations read from the data set WORK.AVERAGE_700_800_PREP_TWO.
If I don't delete the prep and prep_two my data set grows in triplicate. Can you help me understand why this is happening?
Thank You,
Mark
The SAS Support Communities are the correct place to post questions like this. I am sure you will get many responses.
Thanks for the tip!
Do you have any idea how I could use the above in statements (I only have 2 data sets) while using a keep statement on the same set statement?
Thanks!
You can either use
set A(keep=y z) B(keep=y z) indsname = source;
or you can use
set A B indsname = source;
keep y z libref dsname;
Thanks, Rick!
This was exactly what I needed.
For some reason, the (IN=XXXX) option doesn't like me :(
Remember that the IN= data set option creates a temporary variable that is not written to the data set. You need to copy it to a permanent variable if you want to output it, like this:
set A B(in=XXX);
inB = XXX; /* create variable in output data set */
Hi,
I need to create a temporary variable that contains the name of the source data set in PROC APPEND.
I can not use Data step Set statement, because my each source has diff structure I .e column names and orders are not same so I need to use FORCE option to read the file as is.
Thanks
You can ask SAS programming questions at https://communities.sas.com/
Nice!