Last week someone posted an interesting question to the SAS/IML Support Community. The problem involved four nested DO loops and took hours to run. By transforming several nested DO loops into an equivalent matrix operation, I was able to reduce the run time to about one second.
The process of converting loops into vector or matrix operations is called vectorization. The programmer who posted the question knew that vectorization would improve the program, but also stated that "vectorization is really difficult." I agree. However, life is full of difficult but necessary tasks. In statistical programming, vectorization is necessary (but rewarding!) because it can dramatically decrease the run time of a program.
Statistical programmers need to know how to vectorize programs. Whether you write your programs in SAS/IML language, MATLAB, or R, it is essential to know how to convert loops into equivalent vector operations. Therefore, I have decided to post a series of examples that show how to recognize certain patterns that arise in loops, and how to replace those loops with matrix operations. These examples will be tagged with the "vectorization" tag in the word cloud (in the right sidebar) on my blog. Today is the first example.
Here are some general tips and techniques:
- When you have nested loops, vectorize the inner loop first.
- Convert a loop with scalar operations into a single vector operation. For example, convert sums into vector dot products.
- Convert a loop of vector operations into a single matrix-vector multiplication.
- Convert a loop of matrix-vector multiplications into a single matrix-matrix multiplication.
In terms of matrix computations, follow this general rule:
Solve the problem by using the highest possible level of Basic Linear Algebra Subroutine (BLAS).
A level-0 BLAS is a scalar operation. A level-1 BLAS is a vector operation, such as a vector addition, a dot product, or a vector norm. A level-2 BLAS is a matrix-vector operation, such as a matrix-vector multiplication, an outer product, or solving a triangular linear system. A level-3 BLAS is a matrix-matrix operation, such as matrix multiplication, forming a cross-product matrix, or solving triangular linear systems with multiple right-hand sides (see the SAS/IML TRISOLV function).
The notions of "level" and BLAS are discussed in Chapter 1 of Golub and van Loan's Matrix Computations.
An example problem with three nested loops
The problem in the discussion forum involved four nested loops, but I'll extract the essence of the problem into a simpler example. Suppose that you have implemented a textbook formula and your SAS/IML program looks like the following:
proc iml;
X = {1 2 3, /* example data */
4 3 1,
1 1 2,
0 0 3};
n = nrow(X);
p = ncol(X);
S=j(p,p,.); /* allocate matrix to hold results */
do j = 1 to p;
do k = 1 to p;
u=0;
do m = 1 to n;
u = u + X[m,j]*X[m,k];
end;
S[j,k] = u; /* the (j,k)th result */
end;
end;
print S; |
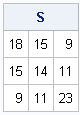
At this stage, the program consists of three loops and scalar operations (level-0 BLAS).
When I study these loops, I notice the following:
- The outer loop (the j loop) is a loop over the columns of the matrix X because the expression X[m,j] appears in the innermost loop.
- The middle loop (the k loop) is also a loop over the columns of the matrix X because the expression X[m,k] appears in the innermost loop.
- The inner loop (the m loop) is performing a summation. (Notice that u=0 before the loop and u=u+stuff inside the loop.) The terms that are being summed are the product of the jth and kth columns.
Step 1: Attack the innermost loop
Because the inner loop is a sum, replace the inner loop by the SUM function. The SUM function takes a vector. For this example, that vector will be the elementwise product of the jth and kth columns: X[ ,j]#X[ ,k]. The following statements show the simplified program, which now has only two loops:
/* Step 1: Replace inner loop with sum of the product of j_th col and k_th col. */
S=j(p,p,.);
do j = 1 to p;
do k = 1 to p;
S[j,k] = sum( X[ ,j] # X[,k] );
end;
end; |
Step 2: Replace summations by dot products
The inner loop now involves the sum of the elementwise product of two vectors. This sum has a more common name: the vector dot product. Consequently, replace the SUM function by a dot product. In order to get the dimensions to match, transpose the first vector, as follows:
/* Step 2: The sum of the product of two vectors is their dot product. */
S=j(p,p,.);
do j = 1 to p;
do k = 1 to p;
S[j,k] = X[ ,j]` * X[,k];
end;
end; |
At this stage, the program consists of two loops and vector operations (level-1 BLAS).
Step 3: Replace vector operations with matrix-vector operations
The next step involves converting vector operations into a matrix-vector operation. Notice that the X[,j] term does not change in the inner DO loop. Furthermore, the product is over all columns, so the inner loop is equivalent to a vector-matrix multiplication. The program is thereby reduced to one loop, as follows:
/* Step 3: Convert to vector-matrix product */ S=j(p,p,.); do j=1 to p; S[j, ] = X[ ,j]` * X; end; |
At this stage, the program consists of one loop and matrix-vector operations (level-2 BLAS).
Step 4: Replace matrix-vector multiplications with matrix-matrix operations
The last step is to recognize that the only remaining loop iterates over the columns of X. But that is equivalent to iterating over the rows of X` (the transpose of X). The loop of vector-matrix multiplication is consequently equivalent to the cross-product operation, X`X, as follows:
/* Step 4: A loop over all rows is equivalent to multiplication by X` */ S = X` * X; print S; |
Notice that the three loops have been replaced by a single level-3 BLAS: matrix multiplication. As stated earlier, for large problems you can realize substantial savings of time if you eliminate loops in favor of high-level linear algebra operations.
One final comment. If you've struggled and labored, but still can't figure out how to vectorize your SAS/IML program, post it to the SAS/IML Support Community. That community is a helpful place to discuss issues related to efficiency and programming in the SAS/IML language.

4 Comments
Pingback: Timing performance improvements due to vectorization - The DO Loop
Pingback: Eight tips to make your simulation run faster - The DO Loop
Pingback: The best articles of 2013: Twelve posts from The DO Loop that merit a second look - The DO Loop
Pingback: Ten tips before you run an optimization - The DO Loop