A common question on SAS discussion forums is how to repeat an analysis multiple times. Most programmers know that the most efficient way to analyze one model across many subsets of the data (perhaps each country or each state) is to sort the data and use a BY statement to repeat the analysis for each unique value of one or more categorical variables. But did you know that a BY-group analysis can sometimes be used to replace macro loops? This article shows how you can efficiently run hundreds or thousands of different regression models by restructuring the data.
One model: Many samples
As I've written before, BY-group analysis is also an efficient way to analyze simulated sample or bootstrapped samples. I like to tell people that you can choose "the slow way or the BY way" to analyze many samples.
In that phrase, "the slow way" refers to the act of writing a macro loop that calls a SAS procedure to analyze one sample. The statistics for all the samples are later aggregated, often by using PROC APPEND. As I (and others) have written, macro loops that call a procedure hundreds or thousands of time are relatively slow.
As a general rule, if you find yourself programming a macro loop that calls the same procedure many times, you should ask yourself whether the program can be restructured to take advantage of BY-group processing.
Stuck in a macro loop? BY-group processing can be more efficient. #SASTip Share on XMany models: One sample
There is another application of BY-group processing, which can be incredibly useful when it is applicable. Suppose that you have wide data with many variables: Y, X1, X2, ..., X1000. Suppose further that you want to compute the 1000 single-variable regression models of the form Y=Xi, where i = 1 to 1000.
One way to run 1000 regressions would be to write a macro that contains a %DO loop that calls PROC REG 1000 times. The basic form of the macro would look like this:
%macro RunReg(DSName, NumVars); ... %do i = 1 %to &NumVars; /* repeat for each x&i */ proc reg data=&DSName noprint outest=PE(rename=(x&i=Value)); /* save parameter estimates */ model Y = x&i; /* model Y = x_i */ quit; /* ...then accumulate statistics... */ %end; %mend; |
The OUTEST= option saves the parameter estimates in a data set. You can aggregate the statistics by using PROC APPEND or the DATA step.
If you use a macro loop to do this computation, it will take a long time for all the reasons stated in the article "The slow way or the BY way." Fortunately, there is a more efficient alternative.
The BY way for many models
An alternative way to analyze those 1000 regression models is to transpose the data to long form and use a BY-group analysis. Whereas the macro loop might take a few minutes to run, the BY-group method might complete in less than a second. You can download a test program and compare the time required for each method by using the link at the end of this article.
To run a BY-group analysis:
- Transpose the data from wide to long form. As part of this process, you need to create a variable (the BY-group variable) that will be unique for each model.
- Sort the data by the BY-group variable.
- Run the SAS procedure, which uses the BY statement to specify each model.
1. Transpose the data
In the following code, the explanatory variables are read into an array X. The name of each variable is stored by using the VNAME function, which returns the name of the variable that is in the i_th element of the array X. If the original data had N observations and p explanatory variables, the LONG data set contains Np observations.
/* 1. transpose from wide (Y, X1 ,...,X100) to long (varNum VarName Y Value) */ data Long; set Wide; /* <== specify data set name HERE */ array x [*] x1-x&nCont; /* <== specify explanatory variables HERE */ do varNum = 1 to dim(x); VarName = vname(x[varNum]); /* variable name in char var */ Value = x[varNum]; /* value for each variable for each obs */ output; end; drop x:; run; |
2. Sort the data
In order to perform a BY-group analysis in SAS, sort the data by the BY-group variable. You can use the VARNUM variable if you want to preserve the order of the variables in the wide data. Or you can sort by the name of the variable, as done in the following call to PROC SORT:
/* 2. Sort by BY-group variable */ proc sort data=Long; by VarName; run; |
3. Run the analyses
You can now call a SAS procedure one time to compute all regression models:
/* 3. Call PROC REG and use BY statement to compute all regressions */ proc reg data=Long noprint outest=PE; by VarName; model Y = Value; quit; /* Look at the results */ proc print data=PE(obs=5); var VarName Intercept Value; run; |
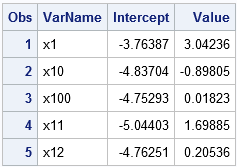
The PE data set contains the parameter estimates for every single-variable regression of Y onto Xi. The table shows the parameter estimates for the first few models. Notice that the models are presented in the order of the BY-group variable, which for this example is the alphabetical order of the name of the explanatory variables.
Conclusions
You can download the complete SAS program that generates example data and runs many regressions. The program computes the regression estimates two ways: by using a macro loop (the SLOW way) and by transforming the data to long form and using BY-group analysis (the BY way).
This technique is applicable when the models all have a similar form. In this example, the models were of the form Y=Xi, but a similar result would work for GLM models such as Y=A|Xi, where A is a fixed classification variable. Of course, you could also use generalized linear models such as logistic regression.
Can you think of other ways to use this trick? Leave a comment.

27 Comments
Ah transpose - a neat trick. BY group processing is good and efficient when you can do everything in one PROC. The output for each group is gathered together. It suits the monolithic procedure design for which SAS is known. However, I almost always find I need to do something with the output from the PROC, usually with ODS graphics. In that case, the output becomes scattered. The introduction of PROC PLM also seems not to fit with the BY group processing model in that two PROCs are required, so you get two groups of output.
.
I know that you can use PROC DOCUMENT to reorganise the output but it seems to know nothing about BY groups, so some complex messing about is required. Here's a suggestion: make PROC DOCUMENT able to re-order pages into BY groups.
Hi Peter,
I believe PROC DOCUMENT will do what you want. The BY-group information is part of the path for the tables and graphs. You have to use the LIST statement to examine the output. Then you can use the REPLAY statement to replay the items in BY-group order. But you are correct that there is some manual work. it is not automatic.
Pingback: Reorder the output from a BY-group analysis in SAS - The DO Loop
Thank you for the tutorial!
Would it be possible to also get the p-value and the 95% confidence interval in that table as well (as addition columns)?
Sure, turn of ODS graphics and use ODS EXCLUDE ALL to suppress the output. Then use the ODS OUTPUT statement to store the ParameterEstimates table in a data set.
Thank you soo much for the quick and very helpful response!!
Much appreciated! Had spent quite a bit of time trying to figure that out.
Hello Everyone,
First off this technique is great. I have question on how you would approach a problem I have. I am using logistic regression that uses limitless dummy variables (or categorical variables) but only two macroeconomic variables. Here is an example of what I did using the "Slow Way":
proc logistic data=&estimationdata desc namelen=50;
model &depvar = %scan(¯ovar,&maci) %scan(¯ovar,&macj) &dummyvar
/ selection=stepwise include=2 slentry=&significancelevel slstay=&significancelevel;
ods output ParameterEstimates = est&mack;
ods output FitStatistics = fit&mack;
ods output ConvergenceStatus = cs&mack;
run;
Where ¯ovar references a list of macro variables and &dummyvar references a list of dummy variables
I tried something as follows but doesnt give the desired outcome
data Long;
set dwngrd;
array Dummy [*] &dummyvars.; /* <== specify explanatory variables HERE */
do DummyVarNum = 1 to dim(Dummy);
DummyName = vname(Dummy[DummyVarNum]); /* variable name in char var */
DummyValue = Dummy[DummyVarNum]; /* value for each variable for each obs */
output;
end;
array Macro [*] &VarNameList.; /* <== specify explanatory variables HERE */
do MacroVarNum = 1 to dim(Macro);
MacroName = vname(Macro[MacroVarNum]); /* variable name in char var */
MacroValue = Macro[MacroVarNum]; /* value for each variable for each obs */
output;
end;
drop &VarNameList.
&dummyvars. ;
run;
Thanks
Hi Tyler, from your question, it sounds like you intended to post it to a discussion forum. Try the SAS Support Community. Someone there will help you. Basically, you need to assign Dummy[i] and Macro[i] inside the loops and have a single OUTPUT statement outside the loop.
Hi Rick, great post! very useful.
In addition, you for sure know that this approach can be extended to n variables in a straight forward way but even this can be further generalized:
Suppose you have n variables and want to quickly estimate all possible models with any number of 1 to n variables, you just have to create all possible combinations of k <= n variables and fill the rest n - k with (different) null variables. This way you always have exactly n variables for the model statement and SAS will happily ignore the additional nulls.
The only thing I haven't figured out how to do in an elegant way is to generate these combinations. Right now, I am (ab)using proc plan with half a ton of boiler plate code around it :)
PROC PLAN is a good choice. I assume that k is a fixed value, otherwise this is all-subset regression. I've written about how generate all "n choose k" combinations of the variables. Depending on your application, you might want to use the ALLCOMB or LEXCOMBI functions. Also, depending on what you are trying to accomplish, you might want to use PROC GLMSELECT, which performs variable selection for regression models that have many variables.
What kind of format do the variables name need to be in? Do they need to share a common prefix and be numbered?
No, they can be any list of variables, although they often share a common prefix in practice. On the ARRAY statement in the DATA step, you can use any valid way to specify the variables that are put into the X array. For example, if the first explanatory variable is named FirstVar and the last is named LastVar and you want to specify all variables between them, you can use
array x [*] FirstVar--LastVar; /* <== specify explanatory variables */
Hi Rick
I really like your code but I am not sure how to extend it to the case when variables names are not in the format of xi and have actual name can you help me please? Can we extract variable names using say proc content and use that list and apply proc reg or proc genmod on each name singly?
The only place where you need the variable names is on the ARRAY statement when doing the transpose (the DATA LONG step). Put the names of the variables in a macro variable and use that, or use one of the six ways to specify a list of variables in SAS to specify the variable names. For example, you could use
array x[*] _NUMERIC_;
and then use a WHERE clause (or subsetting IF) exclude the group that contains the Y variable after the transpose. You'll also want to change some DROP clauses to KEEP, and vice versa.
Rick:
I want to be able to use your method, but my application is different. Instead of a database with many variables, I want to test a subset of the observations in a database, all with the same variables. To use your terminology, my WIDE database has 50 observations, I want to create a LONG database with 40 observations, run a regression of that and then repeat with a new LONG database with a different combination of 40 observations, until I exhaust all of the possible combinations of 40 from within 50. I would love to hear that your method can be adopted to do that as my existing method using a DO loop that creates a new LONG for each iteration is slow.
Yes. What you describe is the technique that I recommend for Jackknife or bootstrap analyses. You create a long data set that has 40 obs for each sample
and you tag each sample by an identifier that you use in a BY statement for analysis. You don't say how you plan to choose the 40 obs, but for many sampling schemes, you can use PROC SURVEYSELECT. For references and examples, see steps 2 and 3 of the bootstrap method in the "The essential guide to bootstrapping in SAS."
is it possible to use do loop for GLM? could you please share your inshight. Thank you.
This is my current code and I am do not know how to use loop to get multiple output and run proc plm on it.
ODS Graphics on;
PROC GLM Data= work.new plots=(diagnostics);
CLASS x1 x2;
Model &y = x1|x2 /solution;
**OUTPUT OUT = out1 RESIDUAL = ols_residual PREDICTED = y_forecast1;
ODS Output ParameterEstimates = outest1;**
Lsmeans x1 x2 x1*x2/ cl pdiff adjust=Tukey lines Stderr;
MEANS x1*x2/Tukey lines;
**STORE Model1;**
PROC Print Data=out1;
PROC PLM Restore= Plots=ALL;
score data=work.new out=out1 Residual=res Predicted=yhat;
show all;
LSMEANS x1 x2 x1*x2/ pdiff adjust=Tukey;
run;
Quit;
In most SAS procedures, a "DO loop" if performed by using the BY statement to perform a series of computations. However, I do not know what you are trying to iterate, so please post your SAS programming questions to the SAS Support Communities.
Thank you, Rick. I really appreciate your help.
Thank you for great tutorial! How can I use your code for categorical variables?
The last paragraph says "a similar result would work for GLM models." If you have 1000 categorical variables C1, C2, ..., C1000, you can do the same manipulations to convert from Wide format to Long format.
Thank you! So if I should ask my question in the SAS community, then I'll do. But I don't know if my code is correct:
ods graphics off;
ods exclude all;
proc GLM data=Long;
CLASS VarName;
by VarName;
model Y = Value;
ods output ParameterEstimates=PEOut;
quit;
ods exclude none;
Yes. You should ask programming questions at the Support Communities. In the code you posted, change the CLASS statement to
CLASS Value;
Hi Rick, thank you for this post.
I have transposed my data in the long format per your guidance above.
However, for the model portion, I would like to perform a competing risks regression; see code for example with just one model below (would like to repeat this for 100 genes).
proc phreg data=test;
class gene1 (ref='0')/param=ref;
model localfailtime*localfailevent(0)= gene1/ eventcode=1 rl;
run;
I tried the below, but this does not work... any tips?
proc reg data=test2 noprint outest=PE;
by VarName;
model localfailtime*localfailevent(0) = Value;
quit;
"Does not work" is very vague. If you want to run a PHREG model for each value of the VarName variable, then put the BY statement in PROC PHREG. If you encounter problems, post your code and the error messages to communities.sas.com
Regression results can only be analyzed with R squares and p values? Any trick to get them ?
The doc tells you how to get these statistics: Use the TABLEOUT and RQUARE options on the PROC REG statement:
proc reg data=Long noprint outest=PE TABLEOUT RSQUARE; by VarName; model Y = Value; quit; proc print data=PE; where _TYPE_ = "PARMS" & _RSQ_ > 0.1; var VarName Intercept Value _RSQ_; run; proc print data=PE; where _TYPE_ = "PVALUE" & Value < 0.05; format Intercept Value PVALUE6.4; var VarName Intercept Value; run;