Randomly choosing a subset of elements is a fundamental operation in statistics and probability. Simple random sampling with replacement is used in bootstrap methods (where the technique is called resampling), permutation tests and simulation.
Last week I showed how to use the SAMPLE function in SAS/IML software to sample with replacement from a finite set of data. Because not everyone is a SAS/IML programmer, I want to point out two other ways to sample (with replacement) observations in a SAS data set.
- The DATA Step: You can use the POINT= option in the SET statement to randomly select observations from a SAS data set. For many data sets you can use the SASFILE statement to read the entire sample data into memory, which improves the performance of random access.
- The SURVEYSELECT Procedure: You can use the SURVEYSELECT procedure to randomly select observations according to several sampling schemes. Again, you can use the SASFILE statement to improve performance.
The material in this article is taken from Chapter 15, "Resampling and Bootstrap Methods," of Simulating Data with SAS.
The DATA step
The following DATA step randomly selects five observations from the Sashelp.Cars data set:
sasfile Sashelp.Cars load; /* 1. Load data set into memory */ data Sample(drop=i); call streaminit(1); do i = 1 to 5; p = ceil(NObs * rand("Uniform")); /* random integer 1-NObs */ set Sashelp.Cars nobs=NObs point=p; /* 2. POINT= option; random access */ output; end; STOP; /* 3. Use the STOP stmt */ run; sasfile Sashelp.Cars close; |
A few statements in this DATA step require additional explanation. They are indicated by numbers inside of comments:
- Provided that the data set is not too large, use the SASFILE statement to load the data into memory, which speeds up random access.
- The NOBS= option stores the number of observations in the Sashelp.Cars data into the NObs variable before the DATA step runs. Consequently, the value of NObs is available throughout the DATA step, even on statements that execute prior to the SET statement. The POINT= option is used to read the (randomly chosen) observation.
- The STOP statement must be used to end the DATA step processing when you use the POINT= option, because SAS never encounters the end-of-file indicator during random access.
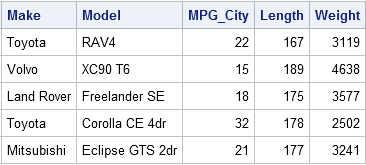
For the example, the selected observation numbers are 379, 417, 218, 380, and 296. You can print the random sample to see which observations were selected:
proc print data=Sample noobs; var Make Model MPG_City Length Weight; run; |
The SURVEYSELECT procedure
The main SAS procedure for (re)sampling is called the SURVEYSELECT procedure. The name is a bit unfortunate because statisticians and programmers who are new to SAS might browse the documentation and completely miss the relevance of this procedure. (To me, it is "PROC RESAMPLE.") The SURVEYSELECT procedure has many methods for sampling, but the method for sampling with replacement is known as unrestricted random sampling (URS). The following call creates an output data set that contains five observations that are sampled (with replacement) from the Sashelp.Cars data:
proc surveyselect data=Sashelp.Cars out=Sample2 NOPRINT seed=1 /* 1 */ method=urs sampsize=5 /* 2 */ outhits; /* 3 */ run; |
The call to PROC SURVEYSELECT has several options, which are indicated by numbers in the comments:
- The SEED= option specifies the seed value for random number generation. If you specify a zero seed, then omit the NOPRINT option so that the value of the chosen seed appears in the procedure output.
- The METHOD=URS option specifies unrestricted random sampling, which means sampling with replacement and with equal probability. The SAMPSIZE= option specifies the number of observations to select, or you can use the SAMPRATE= option to specify a proportion of observations.
- The OUTHITS options specifies that the output data set contains five observations, even if a record is selected multiple times. If you omit the OUTHITS option, then the output data set might have fewer observations, and the NumberHits variable contains the number of times that each record was selected.
If you are using SAS/STAT 12.1 or later, the output data set contains exactly the same observations as for the DATA step example, because PROC SURVEYSELECT uses the same random number generator (RNG) as the RAND function. Prior to SAS/STAT 12.1, PROC SURVEYSELECT used the older RNG that is used by the RANUNI function.
In summary, if you need to sample observations from a SAS data set, you can implement a simple sampling scheme in the DATA step or you can use PROC SURVEYSELECT. I recommend PROC SURVEYSELECT because the procedure makes it clearer what sampling method is being used and because the procedure supports other, more complex, sampling schemes that are also useful.

14 Comments
In one spot you say, The SURVEYSELECT procedure has many methods for sampling, but the method for sampling without replacement is known as unrestricted random sampling (URS).
Later on you say that URS is for sampling WITH replacement.
The METHOD=URS option specifies unrestricted random sampling, which means sampling with replacement and with equal probability.
I think that URS is WITH replacement, but that's not what your first statement suggests.
Thanks for catching that typo. It is as you say.
Pingback: Twelve posts from 2014 that deserve a second look - The DO Loop
Pingback: Four essential sampling methods in SAS - The DO Loop
Rick,
the random access method is a great technique. I was able to help a colleague with it just this week. The goal was to assign a randomly sampled value to a subject in another data set. I figured out how to do it using code like that below. My question is: Why is the do loop necessary? It won't work without it.
You can ask DATA step programming questions at the Base SAS Support Community. The DO loop is certainly not necessary, as the following example shows:
You are right! I'll bet I forgot the output statement when I tested it without the Do loop.
Hi Rick,
I am trying to do a similar thing shown in "***Randomly assign a car from sashelp.cars to each student of sashelp.class;" above. However, I would also like to have the randomly picked value satisfy a condition. How could I include a condition in the above code? For ex. the condition could be like the "year" of the car be before 2000?
Greatly appreciate your help. Thank you.
Use a WHERE clause to select the condition and use PROC SURVEYSELECT to randomly sample 19 cars. Then merge the class data with the sample of cars. If you need more help, post your question to the SAS Support Communities.
Thank you for your reply, Rick. I think I did not describe my question correctly. I have now posted it here: https://communities.sas.com/t5/SAS-Programming/Randomly-assign-a-date-which-also-satisfies-a-condition-from/m-p/577832#M163778
Hello Rick iam sreelatha,i learn lot of things from your blog as well as i want one doubt in this blog,you said permutation tests and simulation,what is permutation tests and simulation.and how it use in data sampling?
hi
useful blog. need some suggestion also.
method = urs
is it means that duplication record present in data?
"Sampling with replacement" means that there is a probability that the same record is selected multiple times. So, yes, it is possible that you might obtain a duplicate record.
Pingback: The essential guide to bootstrapping in SAS - The DO Loop