Did you know that you can index into SAS/IML matrices by using unique strings that you assign via the MATTRIB statement? The MATTRIB statement associates various attributes to a matrix. Usually, these attributes are only used for printing, but you can also use the ROWNAME= and COLNAME= attributes to subset a matrix.
For example, the following statements read the names and populations (in 2005) of 197 countries into SAS/IML vectors:
proc iml;
use Sashelp.Demographics;
read all var {Name Pop};
close; |
You can use the MATTRIB statement to assign the names of countries to the rows of the Pop matrix. You can then subset the rows by using a character array of names, as follows:
mattrib Pop rowname=Name; /* access rows by using the country name */
/* extract and print populations of large countries */
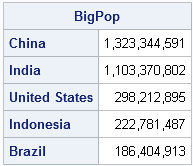
countries = {"China" "India" "United States" "Indonesia" "Brazil"};
BigPop = Pop[countries, ]; /* extract subset */
print BigPop[rowname=countries format=comma13.]; |
Using names rather than indices can make a program more readable. For example, to find the population of a continent, you can add up the populations of the countries in the continent:
/* find population of North America */ NAPop = Pop["United States", ] + Pop["Canada", ]; print NAPop[label="Population of North America (2005)" format=comma13.]; |

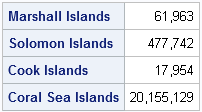
Of course, for many data analysis tasks, you don't want to hard-code the observations, but want to compute them by using some sort of query. For example, you might be interested in the populations of island nations. To find all countries that have the word "islands" as part of their name and print their populations, run the following statements:
/* find population of countries with "Islands" in their name */ idx = loc( find(Name, "ISLANDS") ); u = propcase( Name[idx] ); print (Pop[u, ])[rowname=u format=comma13.]; |
Using the MATTRIB function to assign row names or column names can result in readable code. However, it isn't as efficient as directly accessing the indices of a matrix, so I would usually extract the populations of island nations by using Pop[idx].
I sometimes use this technique for demonstrations and presentations, and I think it would be useful for teaching. Can you think of another instance in which this technique would be useful?

7 Comments
Very clever.
You forgot to include Mexico in your North American population calculation.
Good point. Sorry about that! According to the CIA World Factbook, I also excluded Greenland and some island nations. Of course, if you consider the CONTINENT of NA, I also excluded all of Central America and the Carribean! I think I'll leave the computation as "an exercise for the reader."
Hi again Rick. I have a small quandary here.
I'm trying to subset a SAS output dataset that has a _TYPE_ and _NAME_ column, each of which has repeated entries. The challenge is to extract all of a certain set of _TYPE_ options (easy with the WHERE statement) and then to further subset by limiting the set of _NAME_ entries if desired.
However, I see that the MATTRIB-based subsetting option only works if there is a unique entry in the rownames, if rownames are repeated (e.g. rownames are AABBCCDD and you wish to retain only rows AA and CC) then it does not work.
Any suggestions in this regard? In this particular case I could bring in each _TYPE_ separately into a different matrix and then subset but is there a way to subset where rownames are repeated?
You are corerct. The rownames need to be unique. They are just used to look up the corresponding index.
You should loop over the unique values of the row names and use the LOC function to find the corresponding rows. For very large data, a more efficient (but less intuitive) method is to use the UNIQUEBY function to extract the subsets.
Is it possible to print rowname as a new variable in a SAS dataset by using create from IML ?