Sometimes I can't remember where I put things. If I lose my glasses or garden tools, I am out of luck. But when I can't remember where I put some data, I have SAS to help me find it.
When I can remember the name of the data set, my computer's operating system has tools to help me find the file. However, sometimes I can remember the name of the variable, but not the data set name. Or I might remember that there are some variables that satisfy a statistical condition, but I can't remember their names or the name of the data set they're in.
In situations like these, you might think that I'd be stuck, but this article shows how to search for variables when you can't remember which data set contains them.
Three useful SAS/IML function for search through data sets
Last week I had two occasions where I had to conduct a search for variables that I only dimly remembered.
Base SAS programmers use SQL, SAS dictionaries, the DATA step, and other tools to search through libraries of SAS data sets. For example, you can use these tools to write a 'grep macro' to locate variables (in any data set) that contain a specific value.
In SAS/IML software there are three functions that enable you to search through multiple data sets:
- The DATASETS function returns the names of all SAS data sets in a specified libref.
- The CONTENTS function returns the names of all variables in a specified data set.
- The USE statement enables you to >open a data set when the name of the data set is stored in a character variable.
I've previously used the DATASETS function and the USE statement to read hundreds of data sets in a loop. I've used the CONTENTS function to find variable names that are common to multiple data sets.
Find a variable that has a specified name
Suppose you can remember the name of a variable, but you cannot remember the name of the data set that the variable is in. No problem! The following SAS/IML function loops through all data sets in the SASHELP library (or any other libref) and finds all data sets that contain the specified variable. To illustrate the technique, this program searches all data sets for a variable named "weight":
proc iml;
lib = "sashelp"; /* where to look? */
ds = datasets(lib); /* vector contains names of all data sets */
/* Find data sets that contain a certain variable name */
do i = 1 to nrow(ds);
varnames = upcase( contents(lib, ds[i]) ); /* var names in i_th data set */
if any(varnames = "WEIGHT") then
print (ds[i]);
end; |

The loop is easy and intuitive. This example does not use the USE statement to open the data sets because you are not interested in a variable's data, just its name.
Find a pair of strongly correlated variables
The next example finds variables that have an extreme value of some statistic. Specifically, the goal is to find a pair of variables that have a large positive or negative correlation.
You can write a loop that reads all numerical variables in the SASHELP library and computes all pairwise correlations. There are three tricks in the following program:
- Some data sets might not have any numeric variables, and Pearson correlations are meaningless for these data sets. The program uses the _ALL_ keyword on the READ statement to read the data. If a data set contains even one numerical variable, it will be read into the X matrix. If not, the matrix X will be a character matrix, and you can use the TYPE function to check whether X is numeric.
- You can restrict your attention to correlations in the lower triangular portion of the correlation matrix. The program uses the StrictLowerTriangular function from a previous post about how to extract the lower triangular elements of a matrix.
- There are some data sets that have only two nonmissing observations or that have two variables that are a perfectly correlated (1 or -1). The following statements ignores these non-interesting cases.
start StrictLowerTriangular(X);
if ncol(X)=1 then return ( {} ); /* return empty matrix */
v = cusum( 1 || (ncol(X):2) );
return( remove(vech(X), v) );
finish;
/* find data sets variables in SASHELP that have the most extreme correlations */
dsNames = j(2, 1, BlankStr(32)); /* remember data set names for min/max */
corrVals = {1, -1}; /* default values for min and max values */
do i = 1 to nrow(ds);
dsName = lib + "." + strip(ds[i]);
use (dsName);
read all var _ALL_ into x; /* 1. read all numerical vars in i_th data set */
close (dsName);
if type(x)='N' then do;
w = StrictLowerTriangular( corr(x, "pearson", "pairwise") ); /* 2 */
if ^IsEmpty(w) then do; /* check to see if there is a new min or max */
if (min(w) > -1) & (min(w) < corrVals[1]) then do; /* 3 */
corrVals[1] = min(w);
dsNames[1] = ds[i];
end;
if (max(w) < 1) & (max(w) > corrVals[2]) then do; /* 3 */
corrVals[2] = max(w);
dsNames[2] = ds[i];
end;
end;
end;
end;
print dsNames corrVals[f=best20.]; |
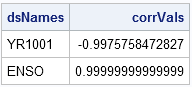
The output shows that the most negatively correlated variables are in the Sashelp.Yr1001 data set. You can reread that data set to find the names of the variables. In a similar way, the Sashelp.Enso data set contains two variables that are almost perfectly positively correlated because they are measuring the same quantity in different units.
You can use this technique to investigate a wide variety of statistics. Which variables have the largest range? The largest standard deviation? You can also write your own "grep function" to locate the character variables that have specified values. The resulting function is simpler and shorter than the "grep macro" in Base SAS.
