In my book Simulating Data with SAS, I discuss a relationship between the skewness and kurtosis of probability distributions that might not be familiar to some statistical programmers. Namely, the skewness and kurtosis of a probability distribution are not independent. If κ is the full kurtosis of a distribution and γ is the skewness, then it is a mathematical fact that κ ≥ 1 + γ2. In particular, the full kurtosis can never be less than 1. Equivalently, the excess kurtosis, which is κ – 3, can never be smaller than –2.
My book includes SAS programs that readers can use to simulate univariate and multivariate data that satisfy specific statistical relationships. Occasionally readers write to say that the programs report an error when used to simulate from a distribution that has large skewness and small kurtosis. For example, recently a reader wrote to say that "the programs give error messages when I try to simulate data with skewness=2 and kurtosis=3."
My response: Yes, the error message appears because you are asking for the impossible. The values γ=2 and κ=3 do not satisfy the relationship that κ ≥ 1 + γ2. Consequently, there is no probability distribution that has that combination of skewness and kurtosis.
The distribution with the smallest kurtosis
It is easy to show that the simple discrete Bernoulli distribution is the probability distribution that has the least kurtosis for a given amount of skewness. This makes sense intuitively because the kurtosis measures the heaviness of the tails of a distribution. The Bernoulli distribution has no tails; all of the probability mass is near the center.
For the Bernoulli distribution with probability of success p, define q = 1 – p. Then the skewness of the Bernoulli distribution is γ = (1-2p) / sqrt(pq) and the full kurtosis is κ = (1-3pq) / (pq). These values satisfy the equation κ = 1 + γ2, which shows that the kurtosis is as small as possible for a given value of the parameter p.
Consequently, if you want an example of a distribution that has small kurtosis relative to the amount of skewness, choose the Bernoulli distribution. The Bernoulli distribution with p = 0.5 has the smallest kurtosis among all probability distributions. When p = 0.5, the full kurtosis is κ = 1, which is equivalent to an excess kurtosis of –2.
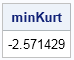
It is worth mentioning that if you have a sample of data and compute the sample estimate of excess kurtosis, the estimate might be smaller than –2. For example, the excess kurtosis for the data {1, 1, 2, 2} is –6. Even in larger samples, you can expect some random samples to have a kurtosis value that is less than the kurtosis of the probability distribution. For example, the following simulation draws 100 samples of size N from the Bernoulli(0.5) distribution. When N=10, the minimum value of the excess kurtosis is –2.57, which is less than the kurtosis of the distribution. If you increase N, the minimum kurtosis value gets closer to the population value of –2.
proc iml; N = 10; /* sample size */ NumSamples = 100; /* number of samples to draw */ call randseed(12345); x = randfun(N//NumSamples, "Bernoulli", 0.5); kurt = kurtosis(x); minKurt = min(kurt); print minKurt; |
For more information about skewness and kurtosis, see the articles "Skew this" and "Does this kurtosis make my tail look fat?"
