A SAS/IML user on a discussion forum was trying to read data into a SAS/IML matrix, but the data was so large that it would not fit into memory. (Recall that SAS/IML matrices are kept in RAM.) After a few questions, it turned out that the user was trying to compute certain statistical quantities for each row of the data. This is good news because it implies that he does not have to read the entire huge data set into a SAS/IML matrix. Instead, he can read a block of observations into a matrix, do the computations for those rows, and overwrite the matrix by reading the next block. This article describes how to use the SAS/IML language to read blocks of observations from a SAS data set.
The SAS/IML language supports several ways to read data from a SAS data set. I have previously discussed sequential access and random access of data. In the article on sequential access, I showed how to read data one observation at a time, but you can also read blocks of observations.
A simple example: Computing row means
Suppose that you have the following data, which contains 20,000 observations and 1,000 variables:
%let NumCols = 1000;
%let NumRows = 20000;
data Big;
keep x1-x&NumCols;
array x{&NumCols} x1-x&NumCols;
do i = 1 to &NumRows;
do j = 1 to &NumCols;
x{j} = i;
end;
output;
end;
run; |
Each row is constant, and the mean of the ith row is i. This data set is not huge, so you do not need to do anything special to read the data. The following call to PROC IML shows the "usual" way to read the data into a SAS/IML matrix and to compute the row sums:
proc iml;
use Big nobs N; /* N = num obs in the data set */
read ALL var _NUM_ into x;
close Big;
result = x[ , :]; /* compute mean of each row */
/* print the top and bottom observations */
top = 1:3; bottom = (N-3):N;
print (result[top, ])[label="Result" r=(char(top))],
(result[bottom, ])[r=(char(bottom))]; |
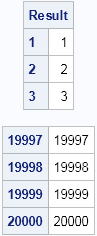
The first three and last three observations are printed. Two features of the SAS/IML language are used that might not be familiar to every reader:
- The NOBS option on the USE statement is used to create a scalar N that contains the number of observations in the SAS data set.
- A subscript reduction operator (:) is used to compute the mean of each row.
Obviously, if you really wanted to compute row means you could do this computation more simply by using the DATA step. This simple example is presented so that you can focus on the core issue (reading data in blocks) without being distracted by extraneous details.
Reading blocks of observations
Now suppose that the Big data set is much, much, bigger than in this example. So big, in fact, that it cannot fit into RAM. What can you do?
Well, because this example computes quantities that depend only on rows, you can read the data in blocks (sometimes called "chunks"). The key change is to the syntax of the READ statement. Instead of using the ALL option to read all observations, use the NEXT statement and specify the number of rows that you want to read by using a macro variable. Also, you need to use the DO DATA statement to tell the SAS/IML language to keep reading data until there are no more unread observations.
For example, the following PROC IML program reads 2,000 observations at a time:
%let BlockSize = 2000;
proc iml;
use Big nobs N; /* 1. Get number of observations */
result = j(N, 1, .); /* 2. allocate space for results */
/* read the blocks */
row = 1;
do data; /* 3. DO DATA statement */
read next &BlockSize var _NUM_ into x; /* 4. Read block */
lastRow = min(row + &Blocksize - 1, N); /* don't go past N */
result[row:lastRow, ] = x[ , :]; /* 5. Compute on this block */
row = lastRow + 1;
end;
close Big;
/* print the top and bottom observations */
top = 1:3; bottom = (N-3):N;
print (result[top, ])[label="Result" r=(char(top))],
(result[bottom, ])[r=(char(bottom))]; |
The output is the same as before. The main features of this program are as follows:
- As before, use the NOBS option on the USE statement to get the total number of observations.
- Allocate space to hold the results.
- Use the DO DATA statement to read the data.
- Use the NEXT &BlockSize option to read 2,000 observations into the matrix x.
- Compute and store the statistics for this block of observations.
That's it. This technique saves memory because you re-use the matrix x over and over again. You do not run out of RAM because the matrix is never huge.
In terms of efficiency, choose the block size to be fairly large. Reading the data in large blocks enables you to vectorize the computations, which is more efficient than reading and computing with small blocks.
One more trick: Reading the last block of observations
There is one wrinkle that you might encounter when you use this technique. If the number of observations is not an integer multiple of the block size, then the last block of observations is not fully read. Instead, you get a warning the looks like the following:
WARNING: Only 1234 observations available, 2000 requested.
This is just an informational message. SAS/IML does in fact read all of the available data, and the fact that the MIN function is used to define the lastRow variable means that the number of observations read will match the index for the result matrix.
Whether this "block reading" technique is suitable for your application depends on what you are trying to accomplish. But in cases where the computations depend only on rows, you can solve your problem by reading portions of the data, even when the complete data are too large to fit into RAM.

6 Comments
I'm new to SAS and SAS-IML. My question is: How do read into or import a variance-covariance matrix into SAS-Proc IML? I know I can do this just by typing them directly into SAS-IML, but what if I have a large dataset? Thanks!
See this blog post: Computing covariance and correlation matrices
Thanks. Your blog is very helpful and informative especially for people like me starting to learn how to do programming.
I'm using social network procedures (so they require a full matrix, not just a line, to calculate) from Jim Moody's SPAN suite. All of my calculations work fine on a copy of the original data but I need to use data now that has 25 imputations attached to it in the same file, enough to well overload my memory allocations. Each line has both an id number for the case and an imputation number (0-25). Is it possible to use the blocking technique with 26 identically sized blocks to perform the analysis and save all the results out to a single standard SAS file?
Yes, that sounds doable.
Pingback: Writing data in chunks: Does the chunk size matter? - The DO Loop