String comparisons in SAS software are case-sensitive. For example, the uppercase letter "F" and lowercase letter "f" are treated as unique characters. When these two letters represent the same condition (for example, a female patient), the strings need to be handled in a case-insensitive manner, and a SAS programmer might write the following compound IF statement:
if sex="F" | sex="f" then do; /** person is female **/ end; |
However, if you plan on comparing many strings (or long strings with mixed case), it is often more efficient to use the UPCASE function to convert the entire string variable to uppercase characters, as shown in the following statements
s = upcase(sex); if s="F" then do; /** person is female **/ end; |
This blog post presents two tips that enable you to handle inconsistent string data in a uniform manner. You can use the tips in the DATA step and in the SAS/IML language.
How to UPCASE in SAS/IML Software
The UPCASE function is part of Base SAS software, and functions in Base SAS software can be called from SAS/IML software. If you call UPCASE on a SAS/IML matrix, the function converts every element in the matrix to uppercase.
I recently needed to use the UPCASE function to process data related to parameter estimates for a set of statistical models. I had some data, similar to those generated by the following DATA step, which I read into SAS/IML vectors:
data Models;
input Distribution $12. Param;
datalines;
ChiSquare 19
gamma 10
chisq 28
t 9
GAMMA 12
;
proc iml;
use Models;
read all var {Distribution Param};
close Models; |
I needed to extract all of the parameters for gamma distributions, but I knew that the values of the Distribution variable were inconsistent: some were indicated by "gamma" (lowercase), others by "GAMMA" (uppercase), and there might also be "Gamma" (mixed case).
Tip: Use the UPCASE function to compare strings in a case-insensitive manner.
You can use the UPCASE function to handle all these cases in a single IF clause or to call the LOC function. The following statements convert the names of distributions to uppercase for easy comparison, and use the LOC function to extract the parameters for the rows that correspond to the gamma distribution:
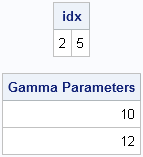
/** simpler and more robust **/ d = upcase(Distribution); idx = loc(d = "GAMMA"); print idx, (Param[idx])[label="Gamma Parameters"]; |
Use SUBSTR to Compare Truncated Values
There is a related trick that you can use to handle truncated values.
Tip: Use the SUBSTR function to compare the first few characters of strings.
The Distribution variable contains the values "ChiSquare" and "chisq," and both of these situations need to be handled in a uniform way. You can use the SUBSTR function to truncate the values of Distribution to, say, five characters, as shown in the following statements:
/** find chi-square models **/ /** truncate to first 5 chars **/ d2 = substr(d, 1, 5); idx = loc(d2 = "CHISQ"); |
These two tips enable you to robustly handle abbreviations and mixed-case spellings of data values.

4 Comments
Pingback: Some SAS Samples have long titles, but what is the length of the longest title that has appeared so far? - The DO Loop
Pingback: Cleaning up after yourself: Deleting data sets - The DO Loop
Hello, There is no SAS option to do this on temp bases?
I have a data set that is stacked from different sources of customers (in this case students) names, sex, birthdates, and enterprise customer id but in my case because of different db. sources one db. might have a name change in it that is a legitimate difference I want to keep (name changes might not be replicated to all our db. systems), whether that be a typo correction or full legal name change I want to keep those differences and others might just be simple upper-lower case differences to do data entry issues. What I want to do is drop out all that are just upper-lower case differences and keep just one of those obs. my code...
proc sql;
create table xd_person_want_A7 as
select
distinct
EMPLID,
last_name,
first_name,
middle_name,
name_suffix,
name_display,
sex,
birthdate
from xd_person_want_A6
order by EMPLID, last_name, first_name, middle_name, name_suffix, name_display, sex, birthdate
;quit;
proc print data = xd_person_want_A7 (obs=3);run;
* --- dedup check of just one columns in the key ---;
proc sort data = xd_person_want_A7 nodupkey out = test dupout = dups ;
by emplid;
run;
/* I get some 5K+ dups out of 250k+- obs,,, so, in this case, my next move it working towards making a data warehouse data set keeping the emplid as a foreign key (to link to my fact table) but making my own SID_emplid key for this new db. I am not sure how to use upcase in this example without the output getting changed to all up case, there is no "SAS option" to do this? Most names are formatted in the typical Cap first letter way and I did not want to muck with them in my new data warehouse */
%put &max_SID_emplid2.;
/* Here we use the max_sid_emplid calculated in the beginning of this code.
It keeps the sid keys starting off with next logical key */
data xd_person_want_A8;
set xd_person_want_A7;
by EMPLID last_name first_name middle_name name_suffix name_display sex birthdate;
retain sid_emplid2;
if sid_emplid2=. then sid_emplid2=&max_SID_emplid2.;
sid_emplid2=sid_emplid2+1;
run;
You can ask SAS programming questions at the SAS Support Communities.