I have previously written about how to use the "table" distribution to generate random values from a discrete probability distribution. For example, if there are 50 black marbles, 20 red marbles, and 30 white marbles in a box, the following SAS/IML program simulates random draws (with replacement) of 1,000 marbles:
proc iml;
call randseed(1234); /* set random number seed */
x = j(1000, 1); /* allocate space for 1,000 draws */
p = {0.5 0.2 0.3}; /* probabilities of each category */
call randgen(x, "Table", p); /* fill vector with values 1, 2, or 3 */
/* compute and print empirical distribution of values */
call tabulate(category, freq, x);
print (freq/sum(freq ))[c={"Black" "Red" "White"}]; |
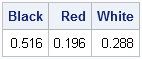
The observed percentages of each category are close to their expected values. About 50% of the draws resulted in a black marble, about 20% resulted in red, and about 30% resulted in white.
It is worth knowing what happens if you specify a set of probabilities that do not sum to 1. If you specify k outcomes whose probabilities sum to T < 1, then a "new outcome" is created. The RANDGEN routine will return the value (k+1) with probability 1-T. In other words, the random sample that is generated by the previous RANDGEN call can also be generated by using the following definition for the probability vector:
p = {0.5 0.2}; /* prob of third category is 0.3 */ |
In a similar way, probabilities that sum to more than 1 are truncated. For example, suppose that you specify the following array:
p = {0.5 0.2 0.4}; /* prob of third category is still 0.3 */ |
The sum of the elements exceeds 1. SAS software will truncate the third element so that the value 3 is returned with probability 0.3, not 0.4 as was specified. Some programmers might expect each element to be divided by the sum of the elements (1.1 in this example), but that is not what happens. You can force that behavior by defining
p = p / sum(p).
The RAND function in the SAS DATA step behaves in the same manner.
