A few days ago on the SAS/IML Support Community, there was an interesting discussion about how to simulate data from a truncated Poisson distribution. The SAS/IML user wanted to generate values from a Poisson distribution, but discard any zeros that are generated. This kind of simulation is known as an acceptance-rejection method (also known as rejection sampling) because you simulate data from a known distribution and accept some variates while rejecting others. For example, the following SAS/IML function generates N random values from the Poisson(λ) distribution, but rejects any values that are zero:
proc iml;
/* Generate N observations from Poisson(lambda). Accept only positive variates */
start RandTPoisson( N, lambda);
x = j(N,1);
call randgen ( x, "POISSON", lambda);
idx = loc(x>=1); /* find all positive values */
if ncol(idx)>0 then
return( x[idx] ); /* return positive values */
else return( idx ); /* return empty matrix */
finish; |
When you execute an acceptance-rejection algorithm, you might generate 1,000 variates, but accept a much smaller number. For example, the following statement asks for 1,000 variates, but only 376 are returned by the RandTPoisson function:
call randseed(1); N = 1000; /* ask for 1,000 */ lambda = 0.5; x = RandTPoisson(1000, lambda); print (nrow(x))[label="Num Obs"]; /* fewer are accepted */ |
On the discussion forum, the user had written a SAS/IML function that iterates inside a DO-WHILE loop until enough variates are generated. At each iteration, the algorithm tries to generate the remaining number of variates:
/* A typical implementation of acceptance-rejection method that
uses a DO-WHILE loop and concatention. NOT EFFICIENT! */
start AcceptRejectRandTPoisson(N, lambda);
r = N;
do while (r > 0);
Y = Y // RandTPoisson(r, lambda);
r = N - nrow(Y); /* remaining observations */
end;
return(Y);
finish;
/* test the function */
x = AcceptRejectRandTPoisson(1000, 0.5);
print (nrow(x))[label="Num Obs"]; |
I often see accept-reject algorithms like this one, and in fact I have written a few myself. The algorithm works, but for many distributions you can write a more efficient algorithm that avoids the DO-WHILE loop. (In general, it can be challenging to write an efficient acceptance rejection algorithm in a vector language such as SAS/IML, R, or MATLAB.) As written, there are two efficiency problems with the DO-WHILE loop:
- Like Zeno's paradox, there is the problem of generating all N observations. The algorithm asks the RandTPoisson for some number of observations, but almost always get fewer observations than is requested.
- The program builds up the array dynamically in a loop, which is very inefficient.
In my forthcoming book, Simulating Data with SAS, I describe a more efficient implementation. The better way is to use statistical theory to predict how many observations you need to generate in order to obtain N that are accepted.
Today I'll show a "quick-and-dirty" method and next week I'll post a more precise statistical result.
For many acceptance-rejection algorithms, there is a well-known "base distribution" such as the normal or Poisson distribution. Observations are generated from the base distribution, and some are rejected. It is often possible to compute the probability that an observation is accepted. If so, you can avoid the inefficiencies in the DO-WHILE loop by simply calling the RandTPoisson function and requesting that it generate more observations than are needed.
Let's see how this works for the current example. The truncated Poisson distribution accepts only positive Poisson variates. You can use the CDF function, which is one of the four essential functions for statistical programmers, to compute the probability that a zero appears. That is the probability of rejection, so the probability of acceptance is computed as follows:
/* What is probability of a successful draw? */
p = 1 - cdf("Poisson", 0, lambda); /* 1 - P(X=0) */ |
If p is the probability of acceptance, then L = N / p is the number of Poisson variates that we should generate in order to obtain approximately N accepted values:
/* If you generate L = N/p variates, you expect N to be accepted */ L = ceil(N / p); x = RandTPoisson(L, lambda); print p[format=6.4] L (nrow(x))[label="Num Obs"]; /* remove the extraneous values, if necessary */ if nrow(x)>N then x = x[1:N]; |
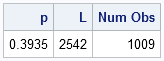
The quick-and-dirty method worked for this one random sample. However, there is no guarantee of success. You expect to get N acceptable values, but sometimes you will obtain fewer.
There are two ways to increase the odds that you will obtain at least N accepted values. The non-statistical (but simple!) way is to use a multiplication factors. Instead of generating L = N / p variate, ask for, say, 20% more: L = 1.2 * N / p. That will usually work. However, a better way is to use statistics to be extremely confident that you will get at least N accepted variates. Next week I'll show the statistical technique.
Conclusion: In a vector language, do not generate random variates with a DO-WHILE loop. Instead, it is more efficient to call a vectorized algorithm and to ask for more variates than are needed. Some of the variates will be rejected, but you can often use statistics to compute the number of variates that you should generate so that at least N are accepted.

10 Comments
Hi Rick,
If you use the REMOVE function, which has the ability to both accept a null matrix in the second argument and also return a null matrix if everything is removed, then you can avoid having to check things. One caveat though, you will end up with a row vector.
;
start RTP( N, lambda);
x = j(N,1);
call randgen ( x, "POISSON", lambda);
return( remove(x, loc( x=0 )));
finish;
;
I am looking forward to the next installment, I quite like the idea of setting the probability that my program will crash!
Brilliant observation, Ian. (But I suspect that YOUR programs NEVER crash!) I actually compare the timing of "subscript" vs "Remove" in Chapter 15 of my "Statistical Programming" book. The comparison is interesting.
I was looking at the problem of simulate data from a zero-truncated Poisson distribution since such a distribution is failry common in consumer choice analysis. One of the solutions I have stumbled upon is this, which uses the inverse cdf approach:
start rtpois(N,lambda);
min = pdf("poisson",0,lambda);
u = j(N,1);
call randgen(u, "Uniform");
y = quantile('poisson',u#(1 - min) + min,lambda);
return(y);
finish;
y = rtpois(1000,5.0);
It produces the required result but is not very efficient for relatively large values of lambda mostly due to computing quantile function. In such a case even a simple acceptance-rejection algorithm performs very well (not many rejections after all). Still fast though.
True. For clarity, I would suggest writing min=CDF("Poisson",0,lambda). It makes it easier to see the general case.
Pingback: Efficient acceptance-rejection simulation: Part II - The DO Loop
Christian Robert has some additional comments on his blog: http://xianblog.wordpress.com/2012/11/21/optimising-accept-reject/
Pingback: Remove or keep: Which is faster? - The DO Loop
Pingback: Implement the truncated normal distribution in SAS - The DO Loop
Hi Rick,
I am wondering if this post is still alive. Lucky me if I get a response. I have been searching about an objective way of choosing the enveloping constant M which is usually employed in rejection sampler to make sure the proposal density covers the target density.
Cheers,
Asad
Pingback: Generate points uniformly inside a circular region in 2-D - The DO Loop