This blog post is part two of a series on model validation. The series is co-authored with my colleague Tamara Fischer.
After revisiting some of the key principles of DevOps and discussing how to map them to the area of analytical work in the first post of this series, let us now take a look at a well-known metaphor for test case development in the software industry. We are referring to the idea of the “test pyramid“ (see here for a thorough almost canonical explanation by Martin Fowler).
There are many variations of the test pyramid as it is not a strict methodology. It's simply a graphical representation that helps to get a clear view on the constraints to be taken into account when designing test cases: how they can be grouped (low-level to high-level), how many of them (in relation to the total) are to be expected, and the costs associated to them. Our version of the test pyramid looks like this:
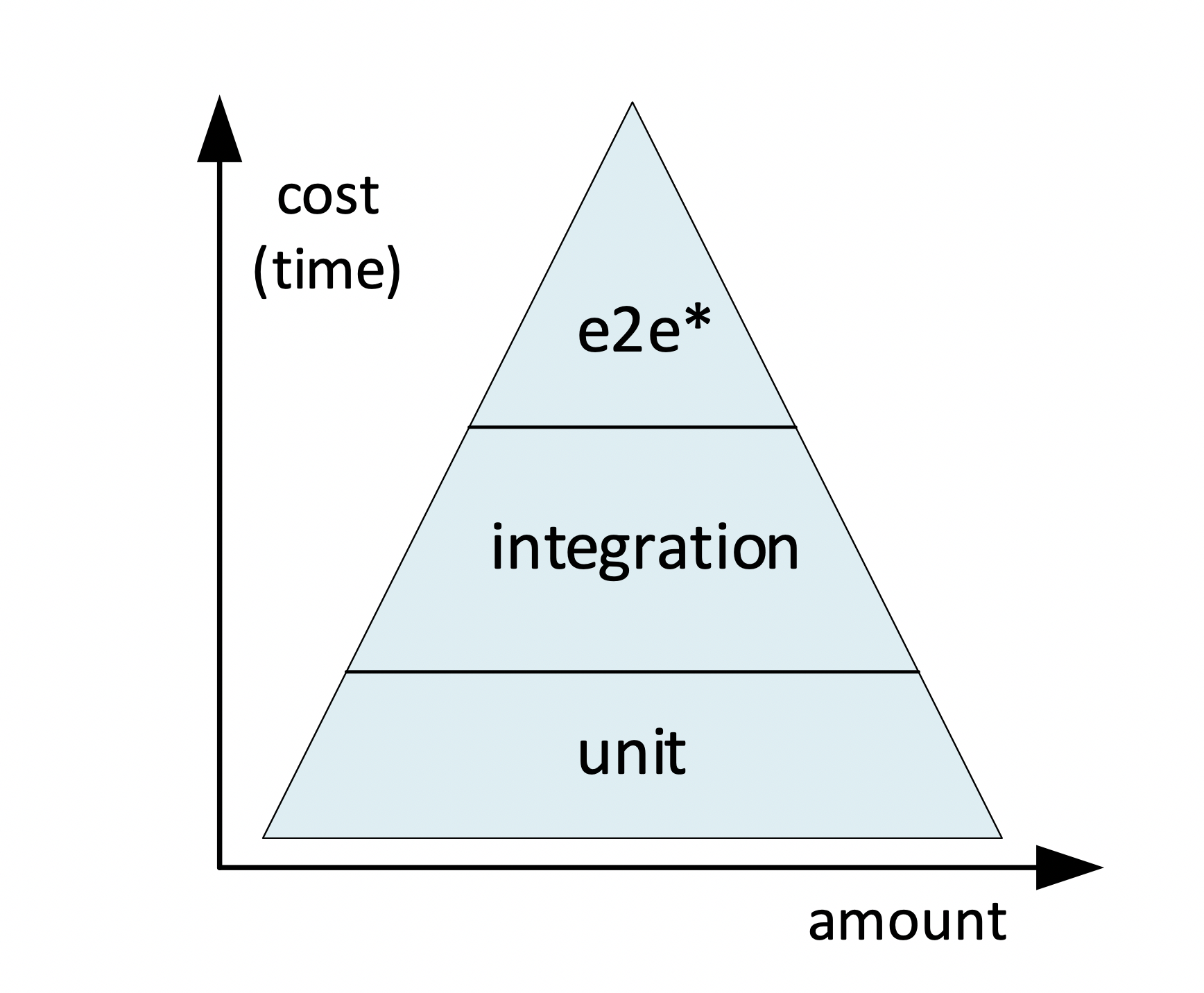
Let’s quickly walk through the layers to see how these sections of the pyramid can be applied to the validation of analytical models.
Unit tests
The bottom layer of our test pyramid is composed of unit tests. Unit tests are small, low-level checks aiming at validating infrastructure and coding policies. Typical unit test cases would be checking if the developer has committed all required files (model binary package, training data, metadata descriptors etc.) or checking if the code adheres to policies and conventions (has a header, has comments, etc.). Unit tests typically are quickly executed and can easily be reused.
For example, the following SAS code checks if the developer has included the model to the project before it was committed. It is assumed that the model function is stored in a single file, usually this is a file in the ASTORE format (analytical store). The name of the model file (passed to this test in the SAS macro variable MODELFILE) is specific to the project, so it is not part of the test but the test, as such, can be easily reused between any project.
/* ********************************************************** */ /* Unit Test: Test if the requested model file is available */ /* ********************************************************** */ %include "/tmp/driver.sas"; options nomprint nosource; %MACRO CHECK_MODEL; %put Checking for model file &MODELFILE. ; %if %sysfunc(fileexist(/tmp/& MODELFILE.)) %then %do; %put SUCCESS: The file & MODELFILE. was found. ; %end; %else %do; %put ERROR: The file & MODELFILE. does not exist. ; %end; %mend; %CHECK_MODEL; options mprint source; |
You might wonder about the return codes. Shouldn’t the test cancel or abort the SAS session if it fails? Is it sufficient to print out a simple “ERROR” statement to the log? In fact, it is – at least in this case. We’ll get back to this point at the end of this post.
A final remark at this point: if you’re searching for more sophisticated approaches for defining unit tests for SAS (our example given above is admittedly super simple), make sure to read recent SAS Global Forum papers like this one or take a look at this unit test framework hosted at SourceForge.
Integration tests
This group of tests checks how well the analytical model fulfills its purpose outside the training sandbox, where it will deal with data of a different quality (missing attributes, corrupt records) and frequency (like streaming data). Integration tests aim higher when compared to unit tests, because they try to measure model quality and model performance before the model is actually deployed to production.
Integration tests are also quite sophisticated in nature, as they use analytical algorithms to measure other analytical algorithms. One clever test falling into this category is the Feature Contribution Index, which analyzes the covariance structure of the predictors only. The advantage of this test is that a target variable is not needed to evaluate whether a model can be applied to new data.
If you’re interested in a detailed description of how the analytics behind this test works, take a look at this blog post.
End-to-end tests
The final group of tests could also be renamed to API tests. These tests try to uncover defects that only can be seen in the “end-to-end” scenarios that include the full loop from the client making the request to the service returning the response. One potential consequence is that true e2e tests might not be suitable for full automation. Testing the API, however, can be fully automated.
What’s the purpose of testing an API? Again, it is primarily a counter-measure to shield against changes creeping in over time.
To illustrate one potential scenario for model validation, take a look at the API defined by the model container images we’re using at SAS (here’s the GitHub project with the source codes). These containers, meant for executing analytical models written in Python or R, support a method call to trigger a scoring operation (taking the data to be scored as input). SAS Model Manager uses this API for interactively testing / validating the model using the graphical user interface.
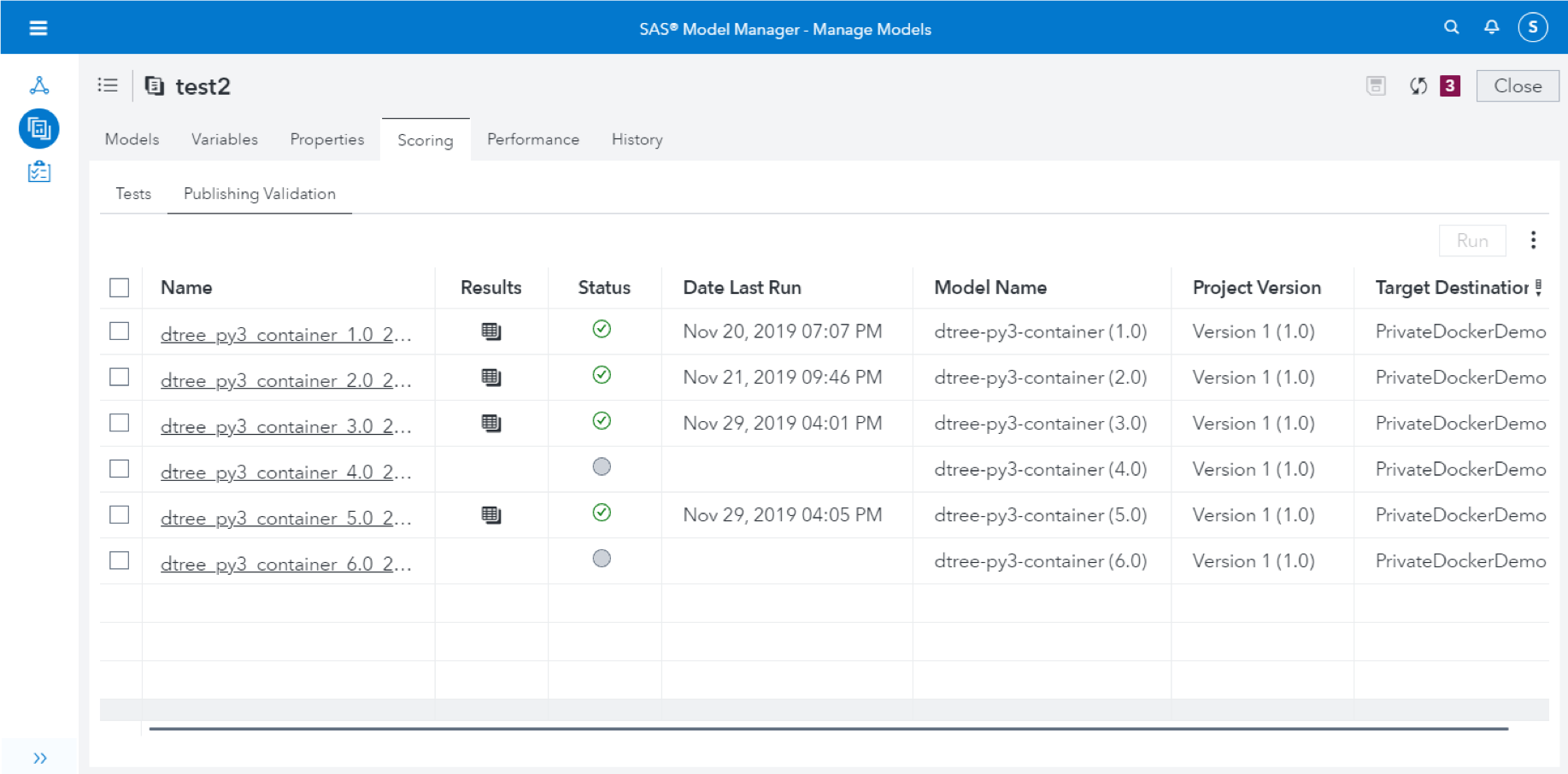
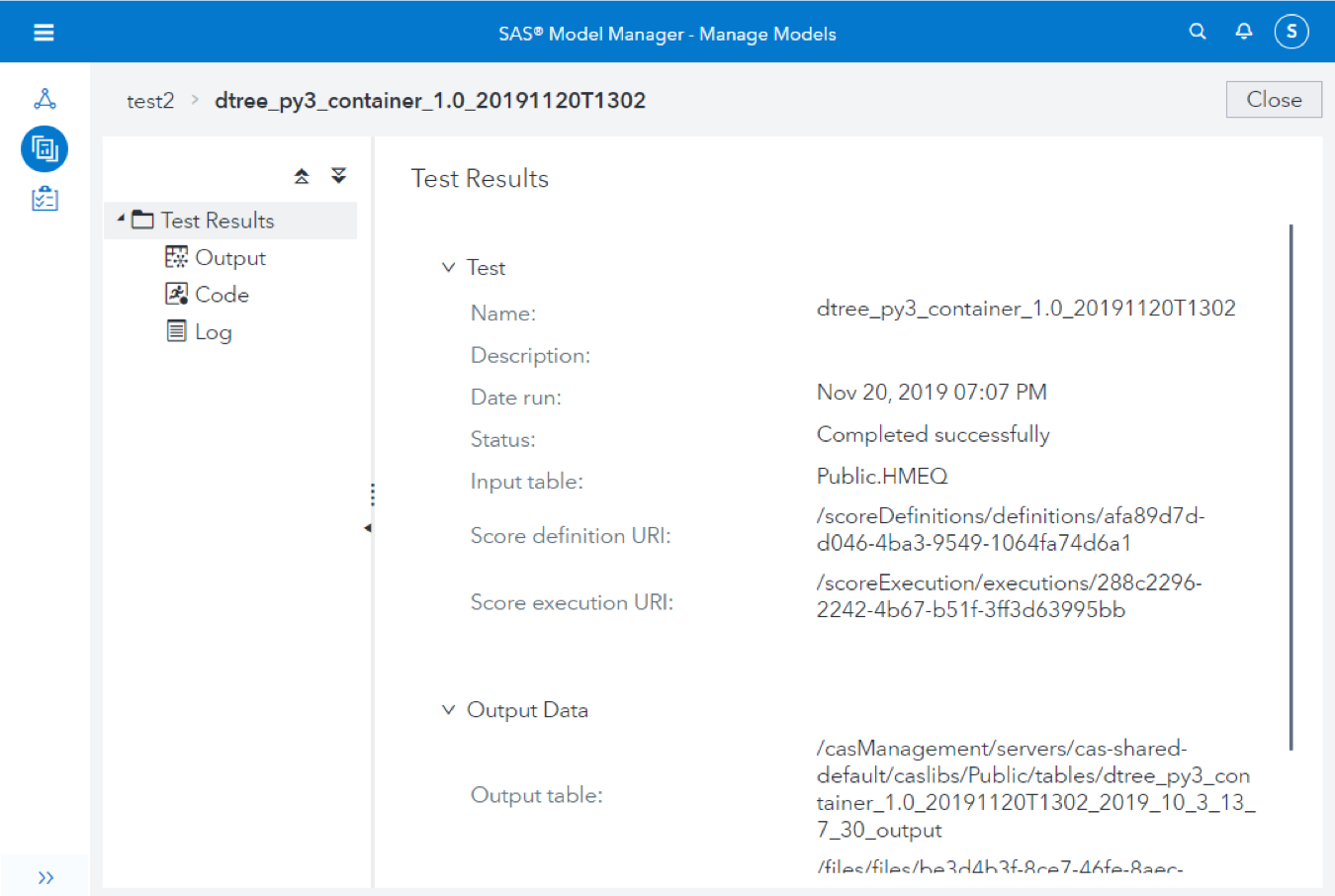
However, it’s easy to see that the same method call can be called in a batch pipeline as well.
Working on a chain gang
Coming back to a point we discussed earlier: what’s the appropriate response if one or more tests fail? As you’ve noticed in the simple example given above, we decided to not immediately cancel all processing. Instead we’re simply printing out the “test failed” notification to the SAS log. Why is that?
It’s important to understand that each test is only one out of potentially many being executed by an automated pipeline outside the immediate reach of the developer, which means it is crucial to aggregate the test results and send them back to the developer.
In our case (as you'll see in the 3rd part of this blog), we decided that we want to separate these steps in the automation pipeline: first we run all tests, push all generated output (logs, reports) back to a Git system and then evaluate the test results (stopping the pipeline at this point if we detect that a test had failed before). We believe that this is a more efficient way of sending feedback to the developer instead of sending separate notifications about each test (especially if there is more than one test failing).
We’re using Jenkins as the test automation system, and a pipeline written in Jenkins (the so-called “Jenkinsfile”) is basically a JSON document containing one or more (Linux) shell scripts sequentially chained together in stages. The following snippet should give you an idea of how we organized the validation pipeline. It shows the three most important stages:
- Sequentially run all tests. Each test is kept in a separate SAS file following a naming convention (test*.sas).
- Commit the output of all tests back to the original Git project.
- Sequentially evaluate the test logs (test*.log). Cancel processing if one of the tests has returned an error.
stage('Run unit tests and quality checks') { steps { sh ''' for f in test*.sas do docker exec $myCnt \ su -c "/opt/sas/spre/home/bin/sas -SYSIN /tmp/$f \ -CONFIG /opt/sas/spre/home/SASFoundation/sasv9.cfg \ -CONFIG /opt/sas/spre/home/SASFoundation/nls/u8/sasv9.cfg \ -PRINT /tmp/results.lst \ -LOG /tmp/results.log" testrunner (docker exec $myCnt cat /tmp/results.log) > $f.log (docker exec $myCnt cat /tmp/results.lst) > $f.lst done ''' } } stage('Commit test results back to git project') { steps { … code omitted … } } stage('Evaluate test results') { steps { sh ''' for f in test*.log do # grep for "ERROR", return false if found cat $f | if [ $(grep -c "ERROR:") == 0 ]; then exit 0; else exit 1; fi done ''' } } |
What’s next?
After reviewing some of the basic Devops principles in the first post of this series, we introduced the concept of the test pyramid in this installment, which helps us to organize the test cases we want to run against the analytical models. The next part will discuss the overall system architecture and will also share more details on the infrastructure (Jenkins, Docker etc.) that we used. Stay tuned!
Continue reading reading post three of this series: Creating a model validation pipeline
Join the virtual SAS Data Science Day to learn more about this method and other advanced data science topics.





