"Moving to cloud" is top of agenda for a lot of the customers I meet. They see the potential for agility or cost reduction. Interestingly when I was speaking to the CTO of one our customers that was an earlier adopter of cloud, he didn’t see an overall cost reduction and didn’t mind. But they did experience increased agility in IT which directly lead to business improvements and an impact on the bottom line. Food for thought.
One of the biggest costs of running an analytics system can be the storage or database cost, whether through typical databases like Oracle, DB2, Hadoop, or Teradata or just SAN alongside your SAS implementation. Getting the storage equation right on cloud can bring your TCO (Total Cost of Ownership) right down; some of our customers have halved it.
When moving to a public cloud some customers just assume that they can "lift and shift" and still get the full advantages of cloud. Unfortunately often this isn’t true -- some small refactoring changes nearly always make sense. Often the virtual hardware on the cloud doesn’t have the same performance criteria as on-premise which means your SAS jobs will run slower when retrieving data. (Buyer beware: some instance types have lower I/O throughput.) To get faster data I/O (throughput) you might need to boost your SAS instance types which increase overall cloud costs. This can also be true for storage types too, so you may end up with more storage volume than you need if you are to guarantee a level of I/O throughput. (For more tech details, Conor Hogan, SAS Solutions Architect, describes the cloud and storage options when using SAS in the cloud.)
In this article I'll cover two main themes. First, thinking differently with SAS Grid storage on cloud, especially with regard to databases. Then, I'll look at getting access to that troublesome data that has stayed on-premise, addressing security and data-on-cloud including cloud caches.
Databases on cloud: do you need one?
 I often get asked what database(s) do you support on cloud, and how does the access pattern work. To learn which databases are supported, view the current list for SAS Viya and the current list for SAS 9.4. Most of the traditional databases work fine as infrastructure-as-a-service, and follow standard rules. It starts to get more interesting as customers use the native databases in AWS, Google Cloud and Azure. These each have their own nuances, which customers didn’t quite understand at the start of the journey. (SAS recently released an access engine that uses native Google BigQuery APIs, with great performance.)
I often get asked what database(s) do you support on cloud, and how does the access pattern work. To learn which databases are supported, view the current list for SAS Viya and the current list for SAS 9.4. Most of the traditional databases work fine as infrastructure-as-a-service, and follow standard rules. It starts to get more interesting as customers use the native databases in AWS, Google Cloud and Azure. These each have their own nuances, which customers didn’t quite understand at the start of the journey. (SAS recently released an access engine that uses native Google BigQuery APIs, with great performance.)
Prior to this customers had been accessing cloud data via ODBC or JDBC, which have limitations in comparison to the new native access engines. However it’s important to note that JDBC was enhanced recently to open up more options to cloud native databases, giving SAS customers a platform-neutral option to try a number of the new native cloud database players.
We also added support for Snowflake (a scalable cloud native database) and will be furthering our support for Azure native databases like HDInsights. SAS 9.4M6 (or higher) or SAS Viya 3.4 (or higher) is required for SAS/ACCESS Interface to Google BigQuery or Snowflake.
Incidentally a number of the database connectors on SAS Viya also support multi-node access which allows each node in SAS Viya to read/write data in parallel to your database, massively speeding up your loading times. There’s a useful article on the SAS Communities that tells you more.
There are quite a few good papers on our conference proceedings covering connecting to cloud databases like Redshift here or within SAS communities like this example to Amazon RDS.
But do you need actually need a database? You could just use the storage on the instances, but that might not be as efficient if you are wanting to scale and take machines up and down in the cloud. You might want to use lower cost persistent storage like AWS S3. Luckily, SAS has started to build out its options for reaching into native-cloud storage buckets like S3 in Amazon, with the ability in SAS Viya to read and write directly in parallel without any additional processing layers required. (caveats exist.), have a look here for more details. Storage on S3 is cheap, but the catch with cloud is that moving data up and down the wire between on- and off-premise might be expensive.
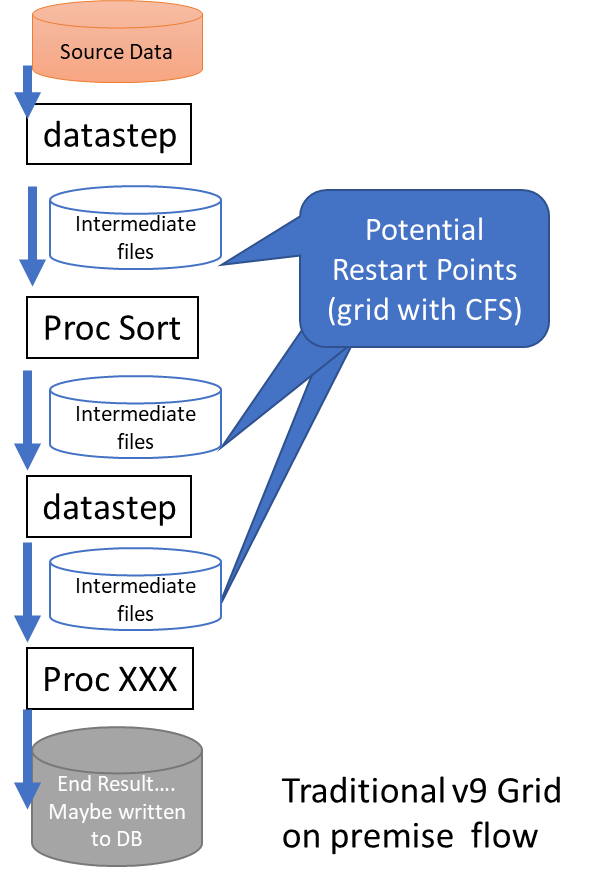 Many SAS Grid Computing users are considering migrating to the cloud, but wonder about what to do with their Clustered File system (CFS), mainly used as a central store, to store SAS data sets in between processing steps, including SASWORK. There are Cloud Clustered File Systems available (and they can be expensive), but because we are moving to cloud we need to think a bit more laterally, more cloud native and decouple work steps to take advantage of cloud design principles.
Many SAS Grid Computing users are considering migrating to the cloud, but wonder about what to do with their Clustered File system (CFS), mainly used as a central store, to store SAS data sets in between processing steps, including SASWORK. There are Cloud Clustered File Systems available (and they can be expensive), but because we are moving to cloud we need to think a bit more laterally, more cloud native and decouple work steps to take advantage of cloud design principles.
Let’s look at an example. The diagram shows a typically data management or analytics data flow, that could be running at scale every day in a SAS grid. The great thing about this design is it allows recovery if a node goes from the last step, as the data is written to a file system that all the nodes can see (SASWORK on a CFS), but has the disadvantage of high cost (relatively on cloud). One way to overcome this could be to re-factoring your design. This could be relatively simple. Let’s look at two simple ways of refactoring this:
- Don't worry about the job 'blowing up', cloud 'hardware' fails relatively infrequently on cloud. Remember Cloud resources are disposable, to restart from the beginning is very viable proposition, so just spin up a new copy on demand, maybe on a bigger instance if you need to make up time, replacing the failed machine. The later version of SAS Grid Manager for LSF from 9.4 M5 allows dynamic bursting/scaling on demand within AWS, so this is really easy to achieve.
- Replace SASWORK with either a database or S3 or move the work into CAS on SAS Viya where node redundancy will protect your data…between steps and failure.
SAS has completed testing of Amazon FSx for Lustre, which offers a new off the shelf highly performant clustered file system suitable for grid, at a reasonable price point. However, be aware that this is sold in large blocks, and may require an even larger size to achieve sufficient throughput for a SAS Grid. We understand AWS is working to reduce these constraints.
Looking forward to SAS Viya 3.5 (4Q2019) we will be introducing further direct access data to cloud native storage sources: parquet on s3 (an extension of the caslib concept) and CASLIBS (direct read and write access) and on Azure Data Lake Storage, Gen 2 -- supporting CSV and ORC formats for direct access.
New SAS tools to help
We covered storage transitions and considerations for design patterns when we lift and shift a SAS system to the cloud and can move most of the storage or the data to the cloud with it. This could include refactoring the workload to be more cloud friendly. This design fits with ‘data gravity’ paradigm, which implies keeping the data near the processing to reduce I/O or network latency low. Increasingly we see cloud design patterns separating compute and processing to allow flexible processing models, including hydrating data on demand.
Unfortunately, in real life the situation isn’t so clear cut, sometimes all the data can’t be moved to the cloud due to cost, security, historical constraints or maybe because the data SAS processes originates from sources that must stay on-premise next to the primary systems they support.
Luckily SAS Viya offers us some very clever solutions to help with this…
 The first of these is SAS Cloud Data Exchange (CDE) that comes as part of our SAS Data Preparation product with SAS Viya. CDE is a data connection capability that securely performs high-volume data transfers (via https) from an on-premises data store(s) to a cloud-based instance of SAS Viya for use in SAS Viya applications. This is done by installing an on-premise local SAS data agent that queries the local source(s) and then pulls the relevant data up to your CAS Cloud instance. This allows end users with a Graphical user Interface to reach through and get to on-premise data, while the administrators don’t have to setup multiple connections (and holes through a firewall) for each access engine to reach on-premise data. There a great summary article of how this works on SAS Communities.
The first of these is SAS Cloud Data Exchange (CDE) that comes as part of our SAS Data Preparation product with SAS Viya. CDE is a data connection capability that securely performs high-volume data transfers (via https) from an on-premises data store(s) to a cloud-based instance of SAS Viya for use in SAS Viya applications. This is done by installing an on-premise local SAS data agent that queries the local source(s) and then pulls the relevant data up to your CAS Cloud instance. This allows end users with a Graphical user Interface to reach through and get to on-premise data, while the administrators don’t have to setup multiple connections (and holes through a firewall) for each access engine to reach on-premise data. There a great summary article of how this works on SAS Communities.
One of the other key considerations we see from some customers is not leaving the data in the cloud permanently. This is where the SAS Viya caching and in-memory model come into play. Used in conjunction with CDE the CAS engine can be used as a semi-temporary store for your data -- think of it as a cache for analysts. SAS Viya’s built in scheduling capabilities could be used to pull in large tables before users arrive and the parallel loading capabilities of SAS Cloud Data Exchange also make on-demand request very feasible. This does requires some design and thought behind the strategies that are used for this in-memory cache in order to meet core situational requirements.
One of the other great advantages of this solution is that that it can also offer an effective route to access data for open source developers (a clever cache) in the cloud. CAS in conjunction with SAS Cloud Data Exchange can provide a secure and audited connectivity back to the on-premise data, and expose it through native Python or R packages that support SAS. The python-swat package allows the Python client access to SAS Cloud Analytic Services. It allows users to execute CAS actions, access data in CAS and process the results all from Python.
In fact, python-swat mimics much of the API of the Pandas package, so that using CAS should feel familiar to current Pandas users. And if they so choose, they can download the data from CAS as required.
This rounds off my initial thoughts on considerations of data when migrating SAS to cloud -- thoughts and discussion are welcome as ever.

2 Comments
Hi Paul,
I lead the data science organization at FannieMae in Washington, DC. My goal is to help the organization migrate/lift-and-shift our SAS models to Amazon AWS. Reading your blog was very helpful. But, i wanted to get clarification about a point that you made. Are you suggesting that one can move an entire SAS Grid in its entirety to AWS in one swoop rather than one model at a time? if that is possible, it would be quite awesome. What are your thoughts and any best practices for quick and low-effort migration to AWS?
Hi Peter
you could move an entire grid to AWS in one fell swoop if you wanted (i.e. a switch over/parallels run typically are seen ) the approach obviously depends on things like appetite for risk and the cost profile and if it makes sense.
High Level thoughts:
- use the opportunity to refactor storage and high TCO items on the infrastructure side, this often equates to benefits
- use it as an opportunity to refactor any major pinch-points.
- don't assume your users are happy, see if there are any easy wins, too often i hear the phrase lift and shift...on its own it only a very short sighted.
- contact your account team, we can giev lots advice on doing this we have design patterns and tools to help on the journey
- use our audit tool to work out what assets you need to move https://communities.sas.com/t5/SAS-Communities-Library/Preparing-for-promotion-migration-and-modernization-of-your-SAS/ta-p/687375 has soem useful hints
- look at Viya, it will give you cloud native capabilities (inc access to low cost native AWS storage) and the flexibility of elastic compute which will be great for smoothing workloads.
regards Paul.