In a voting contest, is it possible for a huge population to get behind a ridiculous candidate with such force that no other contestant can possibly catch up? The answer is: Yes.
Just ask the folks at NERC, the environmental research organization in the UK. They are commissioning a new vessel for polar research, and they decided to crowdsource the naming process. Anyone in the world is welcome to visit their NameOurShip web site and suggest a name or vote on an existing name submission.
As of today, the leading name is "RRS Boaty McBoatface." ("RRS" is standard prefix for a Royal Research Ship.) This wonderfully creative name is winning the race by more than just a little bit: it has 10 times the number of votes as the next highest vote getter, "RRS Henry Worsley".
I wondered whether the raw data for this poll might be available, and I was pleased to find it embedded in the web page that shows the current entries. The raw data is in JSON format, embedded in the source of the HTML page. I saved the web page source to my local machine, copied out just the JSON line with the submissions data, then used SAS to parse the results. Here's my code:
filename records "c:\projects\votedata.txt";
data votes (keep=title likes);
length likes 8;
format likes comma20.;
label likes="Votes";
length len 8;
infile records;
if _n_ = 1 then
do;
retain likes_regex title_regex;
likes_regex = prxparse("/\'likes\'\:\s?([0-9]*)/");
title_regex = prxparse("/\'title\':\s?\""([a-zA-Z0-9\'\s]+)/");
end;
input;
position = prxmatch(likes_regex,_infile_);
if (position ^= 0) then
do;
call prxposn(likes_regex, 1, start, len);
likes = substr(_infile_,start,len);
end;
start=0; len=0;
position = prxmatch(title_regex,_infile_);
if (position ^= 0) then
do;
call prxposn(title_regex, 1, start, len);
title = substr(_infile_,start,len);
end;
run; |
With the data in SAS, I used PROC FREQ to show the current tally:
title "Vote tally for NERC's Name Our Ship campaign"; proc freq data=votes order=freq; table title; weight likes; run; |
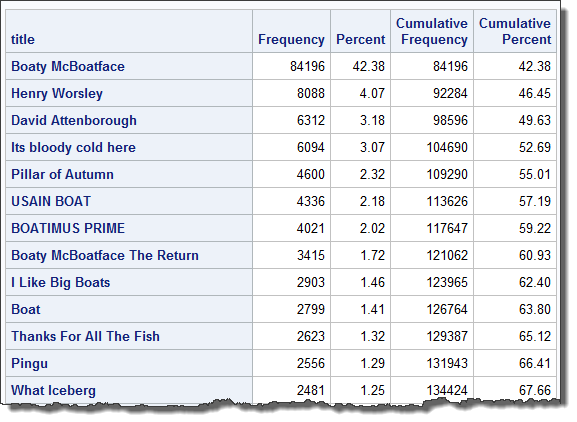
The numbers are compelling: good ol' Boaty Mac has over 42% of the nearly 200,000 votes. The arguably more-respectable "Henry Worsley" entry is tracking at just 4%. I'm not an expert on polling and sample sizes, but even I can tell that Boaty McBoatface is going to be tough to beat.
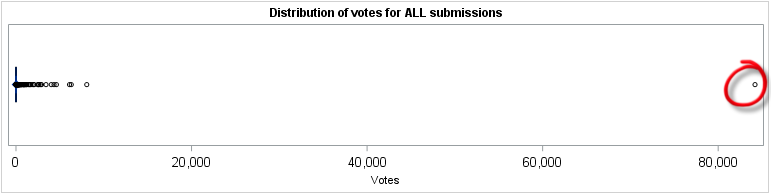
To drive the point home a bit more, let's look at a box plot of the votes distribution.
title "Distribution of votes for ALL submissions"; proc sgplot data=votes; hbox likes; xaxis valueattrs=(size=12pt); run; |
In this output, we have a clear outlier:
If we exclude Boaty, then it shows a slightly closer race among the other runners up (which include some good serious entries, plus some whimsical entries, such as "Boatimus Prime"):
title "Distribution of votes for ALL submissions except Boaty McBoatface"; proc sgplot data=votes(where=(title^="Boaty McBoatface")); hbox likes; xaxis valueattrs=(size=12pt); run; |
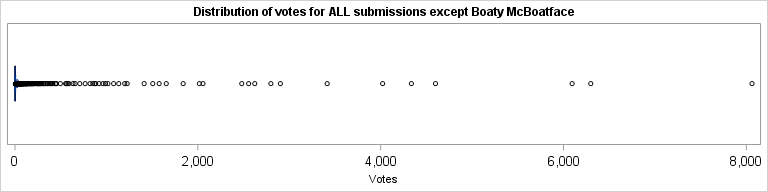
See the difference between the automatic axis values between the two graphs? The tick marks show 80,000 vs. 8,000 as the top values.
Digging further, I wondered whether there were some recurring themes in the entries. I decided to calculate word frequencies using a technique I found on our SAS Support Communities (thanks to Cynthia Zender for sharing):
/* Tally the words across all submissions */ data wdcount(keep=word); set votes; i = 1; origword = scan(title,i); word = compress(lowcase(origword),'?'); wordord = i; do until (origword = ' '); /* exclude the most common words */ if word not in ('a','the','of','and') then output; i + 1; wordord = i; origword = scan(title,i); word = compress(lowcase(origword),'?'); end; run; proc sql; create table work.wordcounts as select t1.word, /* count_of_word */ (count(t1.word)) as word_count from work.wdcount t1 group by t1.word order by word_count desc; quit; title "Frequently occurring words in boat name submissions"; proc print data=wordcounts(obs=25); run; |
The top words evoke the northern, cold nature of the boat's mission. Here are the top 25 words and their counts:
1 polar 352 2 ice 193 3 explorer 110 4 arctic 86 5 red 69 6 sir 55 7 john 54 8 lady 46 9 sea 42 10 ocean 42 11 scott 41 12 bear 39 13 aurora 38 14 artic 37 15 queen 37 16 captain 36 17 james 36 18 endeavour 35 19 william 35 20 star 34 21 spirit 34 22 new 26 23 antarctic 26 24 boat 25 25 cold 25 |
I don't know when voting closes, so maybe whimsy will yet be outvoted by a more serious entry. Or maybe NERC will exercise their right to "take this under advisement" and set a certain standard for the finalist names. Whatever the outcome, I'm sure we haven't heard the last of Boaty...

7 Comments
Very cool analysis! Any date/time stamp on each vote? Wonder how long it took for the name to take over.
Cool ship! I hear Johnny in my head describing it as: "Oh, it's a big pretty white ship with a red stripe, curtains in the windows and and it looks like a big Tylenol!"
No time stamps, but the data did include supporting explanations for each submission. Many explanations said "not as good as Boaty McBoatface, but..."
It's really a cool analysis, and thanks for sharing. It helps me learn a lot about Perl Regular Expression(PRX), but I wonder how the data step reads into the raw TXT file. For a common data step, it detects a particular delimiter, and reads one by one observation. However, in your coding, I did not find the delimiter, could you please help me figure out the reason? Thanks a lot!
Hi Wang,
In the data file, I formatted the JSON so it's basically one record per line. The automatic variable _INFILE_ holds the current line in the buffer, read from the INPUT statement. So instead of reading the data directly into variables, my DATA step processes the information in the _INFILE_ buffer and creates variables from the result.
Hi Chris,
It runs until the 16th April and Boaty McBoatface is getting some good TV time in the UK now which is probably helping with the voting for it. The British sense of humour. We can't be trusted.
John
Pingback: Boaty McBoatface is on the run - The SAS Dummy
Pingback: Copy McCopyface and the new naming revolution - The SAS Dummy