 Gender and race discrimination has been banned in most countries for many years, although gender did have specific exclusions for the insurance industry, where the risk for males and females could be shown to substantially different (e.g. females have a higher life expectancy than males). In the European Union (EU) such discrimination has been prohibited. So what does this mean?
Gender and race discrimination has been banned in most countries for many years, although gender did have specific exclusions for the insurance industry, where the risk for males and females could be shown to substantially different (e.g. females have a higher life expectancy than males). In the European Union (EU) such discrimination has been prohibited. So what does this mean?
For men, they pay less for life insurance and more for annuities
For women, they pay more for life insurance and less for annuities.
The EU has now turned its attention to the algorithms used for everything from which adverts to show online and product recommendations to image recognition and translation. Pretty much everything we do online has an algorithm working behind the scenes. The EU is consulting as to what should be in these algorithms and how to open them up, so that it’s not just a black box making a decision.
Basic algorithm
First consider a simple scorecard used for credit scoring to determine whether to grant a loan or mortgage to an individual.
What do we mean by a scorecard? A scorecard is a predictive model which assigns a numerical score based upon the attributes of an individual.
In statistical terms, it’s a form of a regression model. The model determines which attributes (or features) to use and the associated points based on past experience and the attributes of previous individuals who have defaulted versus those who haven’t.
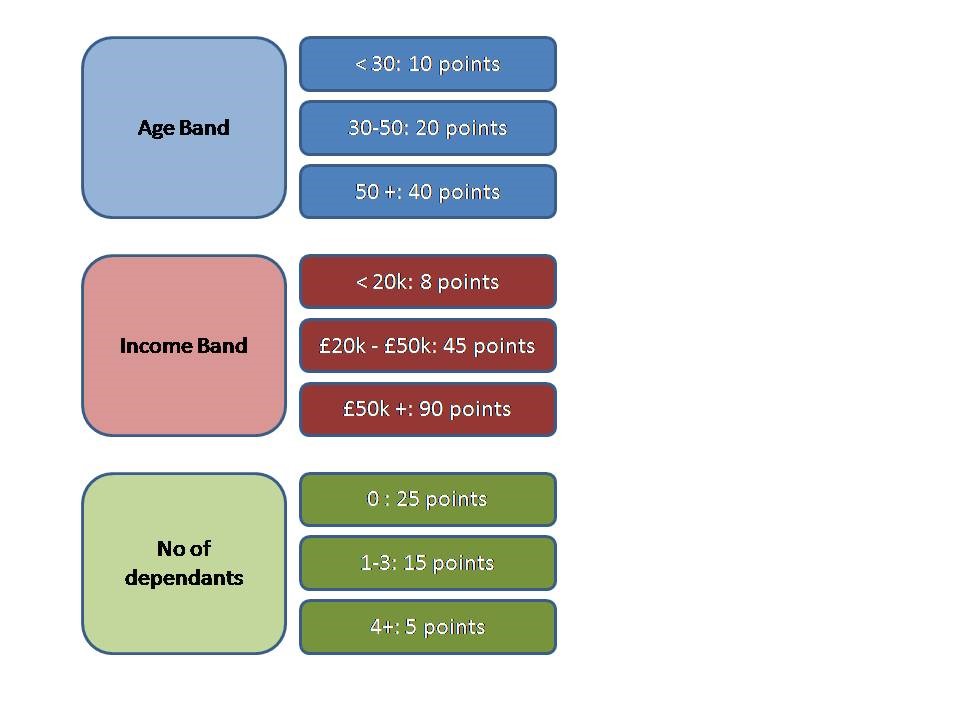 A typical, though simple, scorecard is shown on the left: An individual aged 35, earning £30k and having one dependant, would get a score of:
A typical, though simple, scorecard is shown on the left: An individual aged 35, earning £30k and having one dependant, would get a score of:
20 + 45 + 15 = 80 points.
In the case of a credit scorecard, if 80 points is above the threshold for lending, then the customer would be offered credit, otherwise they would be declined.
Individuals and regulators can clearly see what factors have been used, and that allows them to challenge attributes that they feel may be discriminatory. It’s possible to examine the characteristics of those being refused credit versus those accepted, even for attributes not used within the model, provided the data exists.
Even in the simple example above there could be discrimination against certain groups, for example, more females than males tend to work part-time, often due to family commitments, and therefore are likely to have a lower income and dependants. This means that the decline rate for women versus men is likely to be higher.
Other factors may tend to discriminate against other groups. For example, certain groups may have lower incomes or larger families and thus be refused credit because their score falls below the threshold.
Is it fair?
Yes and no. Yes, because the model hasn’t used any discriminatory factors in the building process, and we could argue that it’s evidence-based. We can show statistically that younger people are more likely to default, and similarly those with lower incomes, therefore the model is only behaving in the way expected.
And no, because the model is utilising, albeit unknowingly, correlations between discriminatory factors and the outcome of obtaining credit. Customers may, understandably, be reluctant to provide details of ethnicity and similar sensitive factors to avoid discrimination. This often means that organisations aren’t able to demonstrate that their models are “fair,” even if they wanted to.
Nevertheless, credit scorecards are widely used in the industry and shown to be reliable measures of risk.
Complex algorithms
Moving to the online world, where individuals share their most intimate and private details about themselves through search, web browsing and purchasing, it gets more complicated. The explosion of algorithms making decisions in this space is overwhelming. Here are some examples:
A/B split test: Browsers to a website are split randomly among two different offers (offer A and offer B); the offer with the highest response is deemed the champion and is then used as the lead offer. This is fairly old-school, and given the volume and velocity of data, more sophisticated multi-factor designs are used which combine a number of factors about the person browsing.
Search engines: Based on your previous browsing history, certain websites will rate higher than others. An avid cook, typing in “apple” might find recipes in their highest rankings, while a technology geek would get iPhones.
In both cases, the algorithms are working behind the scenes, re-tuning themselves based on what you click and don’t click. There can be hundreds of potential factors considered; as a result, the algorithm is changing constantly. The algorithm that made the decision five minutes ago may be different from the algorithm making the decision now.
Once in operation, algorithms continue to re-tune automatically, to optimise the revenue or click-thru rate of the sponsoring organisation. Explicit prohibited factors will be excluded, but it can be difficult (perhaps impossible) to know exactly which factors did get used in making the decision at an exact point in time.
Individual’s browsing habits may have picked up a whole range of third-party cookies from a variety of sites scattered across multiple jurisdictions. Combinations of these cookies with data added from other sources will then be used to determine which advertisement to show and what discount the individual may be entitled to. There’s also the problem of omission – based on an individual’s characteristics, what better offers were they not shown?
Some newer types of models, such as the Deep Learning algorithms used by the Alpha Go team at Google to beat the Go grandmaster, Lee Sedol, are incredibly complex. They’re on the verge of being impossible to understand. In building the model, the system played millions of games and learned new and unique strategies. Such strategies would be difficult to open up for scrutiny; it’d be like asking a human to defend why they chose tea rather coffee that morning.
What can we do?
There’s no easy fix for the system. Organisations and consumers are demanding increasing levels of data-rich content, and often the only way to provide it is through the use of targeted advertising and sponsored content.
There’s a balance required between the needs of individuals and groups of individuals to ensure that they aren’t unfairly excluded from the benefits of the digital economy. On the supply side, there are thousands of organisations, employing millions of people, who benefit from a low cost digital environment with algorithms producing everything from which adverts to display, through to which driver to assign for an Uber car. I think we can safely say “Watch this space.”
And we invite you to watch with us. On September 8, we’re hosting a webinar to show you how to remain compliant and protect and safeguard all of your customers’ personal identifiable information, but give you the agility, accessibility and flexibility you need as part of your data strategy – and help you control your data through better policies and parameters. Register now for: EU Personal Data Protection 2018.
