As Cat Truxillo points out in her recent blog post, some SAS procedures require data to be in a "long" (as opposed to "wide") format. Cat uses a DATA step to convert the data from wide to long format. Although there is nothing wrong with this approach, I prefer to use the TRANSPOSE procedure.
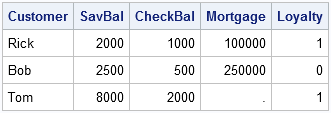
In a wide format, each subject is represented by one row and many variables. For example, variables for a customer in a bank might include the customer's name, checking account balance, savings account balance, mortgage amount, and whether the customer is part of a loyalty program.
data wide; input Customer $ SavBal CheckBal Mortgage Loyalty; datalines; Rick 2000 1000 100000 1 Bob 2500 500 250000 0 Tom 8000 2000 . 1 ; proc print data=wide noobs; run; |
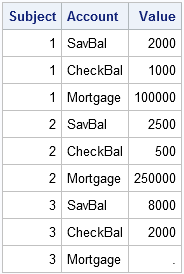
In a long format, each subject spans multiple rows. Each row contains at least three fields: a unique subject identifier, a variable identifier, and a value field. For example, the data in the SavBal, CheckBal, and Mortgage variables can also be represented by the following long format:
When I convert data from wide to long format, I use three sets of variables:
- A variable that uniquely identifies each subject
- Variables in the wide data that should be converted to rows in the long data
- Variables in the wide data set that should be retained and repeated for each new row in the long data.
The first variable uniquely identifies each subject and is used in the BY statement of the TRANSPOSE procedure. The banking data does not contain such a variable (a customer's name might not be unique), but you can add one by using the following DATA step:
/** 1. add a Subject variable (if necessary) **/ data wide; set wide; Subject+1; run; |
The second set of variables are columns in the wide data that should be converted to rows in the long data. These variables will be used in the VAR statement of the TRANSPOSE procedure. In the banking example, the data in the SavBal, CheckBal, and Mortgage variables are converted from columns to rows.
/** 2. Transpose the variables from wide to long format **/ proc transpose data=wide out=long1(rename=(Col1=Value)) name=Account; by Subject; /** for each subject **/ var SavBal CheckBal Mortgage; /** make a row for these variables **/ run; |
The third set of variables are columns in the wide data set that should be retained and repeated for each new row in the long data. For example, you might want to retain the Customer and Loyalty variables. (This step is optional, since sometimes you don't want to retain any variables.) You can accomplish this by using the MERGE statement in a DATA step:
/** 3. Merge with any variables that are not transposed **/ data long; merge long1 wide(keep=Subject Loyalty Customer); /** these variables are not transposed **/ by Subject; run; |
The following table shows the long version of the banking data:
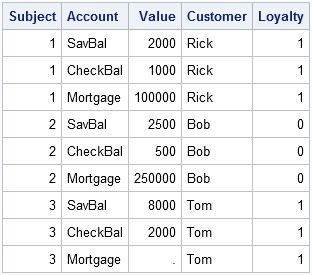
This is the same result that Cat achieved with the DATA step, with different data.
I use PROC TRANSPOSE because I'm lazy. By using PROC TRANSPOSE, I can locate an example that I've used successfully in the past and modify that example to convert my current data from wide to long format. I don't have to think about DATA step arrays. All I have to do is to identify the three kinds of variables mentioned in this blog post.
More than one person has weighed in on whether they prefer PROC TRANSPOSE or DATA step arrays. For more information on using PROC TRANSPOSE to manipulate data, search for "transpose" at www.lexjansen.com. You will find a variety of SUGI and SAS Global Forum papers the use PROC TRANSPOSE, many of them written by expert SAS programmers.

15 Comments
I can recommend two macros from Gerhard Svolba, makelong and makewide :
- makelong: http://support.sas.com/kb/32/121.html
- makewide: http://support.sas.com/kb/32/122.html
br, Thomas
Oh, I just found out that the macros of my comment have already be mentioned in the Article from Cat Truxillo.
br, Thomas
Pingback: Readers’ choice 2011: The DO Loop’s 10 most popular posts - The DO Loop
Pingback: Output percentiles of multiple variables in a tabular format - The DO Loop
Pingback: Plotting multiple series: Transforming data from wide to long - The DO Loop
This was so helpful! Thank you!
How would the coding change if we had two headers that we wanted to convert to rows (i.e., if we had Account and Product). For example, a Product for SavBal would be Savings; similarly a Product for CheckBal would be Chequing).
Sorry, but I don't understand your question. I recommend that you post sample data to the SAS Support Communities, along with a table that describes the output that you want.
Pingback: Comparative histograms: Panel and overlay histograms in SAS - The DO Loop
I found this very helpful. Is there an equivalent method to transpose long to wide format?
Yes. Several ways, in fact. When going from long to wide, you need to consider whether there are an equal number of observations for each group. You can find a discussion of three methods and their advantages/disadvantages in Zdeb (2012). I tend to use the DATA step array method (pp 5-7) more then the other methods.
Great example, very helpful. In your example, you showed how to make a new column called VALUES by choosing the variables:
var SavBal CheckBal Mortgage; /** make a row for these variables **/
What if I have another set of variables that I wanted to make another column out of ? How would I create another column and transpose the additional data which are characters?
I think the best way to get your question answered is to post sample data and the desired end result to the SAS Support Community.
Pingback: Graph wide data and long data in SAS - The DO Loop
Pingback: Automate the placement of reference lines in PROC SGPLOT - The DO Loop